Download to read offline










![Parallel Evolutionary Search 5 (EV5)
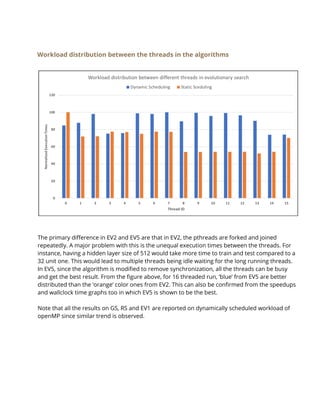
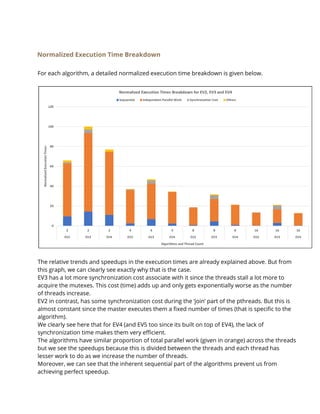
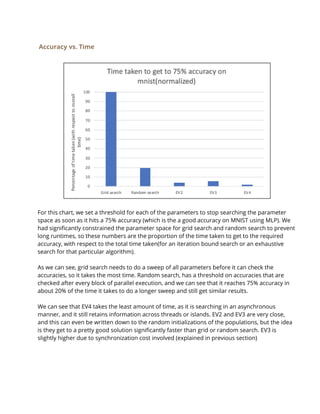
For this approach we used the same model as EV4, but we also parallelized the part of the code
where the master sorts and evolves the global array. We used openMP to implement a parallel
for loop here and ended up parallelizing the evolutions carried out by the master thread.
In addition to that, we also padded the three global arrays to completely take up the cache line
size in order to prevent false sharing. This method thus is our best model in terms to
performance and gave us the most speedups.
Experimental Setup
Tiny DNN
Our initial approach was to use a highly optimized neural network library, to run
hyperparameter search on convolutional neural networks. We wanted to stick with C/C++ for our
implementation, as it is much easier to parallelize on that, rather than python (which has much
better frameworks for deep learning).
We found a library called tiny-dnn which provided a very high level abstraction of neural
networks. It was a highly optimized library which could be linked to a project by using header
only compilation. This library was also in C++14 which prevented us from running this on GHC.
We implemented most of our techniques using the Tiny DNN framework, but on actually running
the tests on multiple threads, we saw that there were no performance improvements. We
hypothesized that this is because of the tinyDNN doing some optimizations using openMP and
pthreads under the hood in the background and this was clashing with our parallelization
implementations. The library was taking up most resources on the limited resource machine we
were running our experiments on. We could not profile because we could not run it on GHC (due
to C++14) and AWS blocked proper profiling on their instances. At this point, we decided to
abandon this library, and use a simpler DNN (a multi layer perceptron) to train our networks.
MLP
We eventually decided that we will mostly try and use an existing simple multi-layer perceptron
codebase, or reimplement our own version on a simple multilayer perceptron with
backpropagation. We ended up taking some motivation and code [2], and reimplemented parts
of it to fit our needs.
This meant that we could not test our algorithms on very complicated networks (just MLPs), but
given the resource constraints we had, and the amount of time it takes to train even a single
complicated network, it would have taken us considerable amount of resources and time to](https://image.slidesharecdn.com/metamachinelearninghyperparameteroptimization-210221212408/85/Meta-Machine-Learning-Hyperparameter-Optimization-12-320.jpg)

![Credit Distribution
The work was equal by both partners. We both worked together on figuring out the approaches,
setting up frameworks and getting a basic version of our project working. We split up the
algorithms we have implemented equally, and had equal contribution in terms of the analysis
and the report.
References
[1] https://github.com/tiny-dnn
[2] https://github.com/davidalbertonogueira/MLP/blob/master/README.md
[3] https://deepmind.com/blog/population-based-training-neural-networks/
[4] http://geco.mines.edu/workshop/aug2011/05fri/parallelGA.pdf
[5] https://blog.floydhub.com/guide-to-hyperparameters-search-for-deep-learning-models/
Two images were taken from:
[6] https://www.slideshare.net/alirezaandalib77/evolutionary-algorithms-69187390
[7] https://www.slideshare.net/alirezaandalib77/evolutionary-algorithms-69187390](https://image.slidesharecdn.com/metamachinelearninghyperparameteroptimization-210221212408/85/Meta-Machine-Learning-Hyperparameter-Optimization-24-320.jpg)

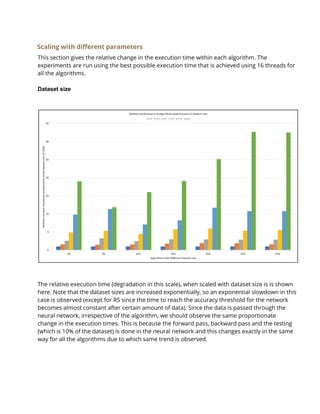
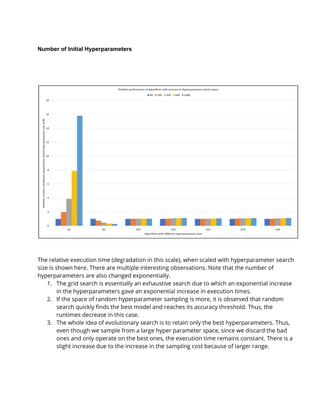
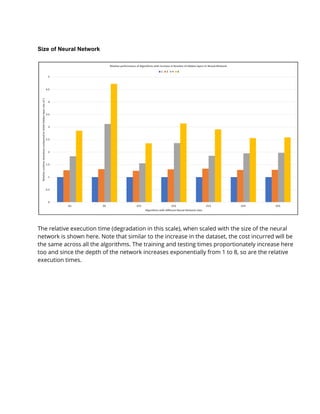
The document discusses the implementation of various hyperparameter optimization algorithms for deep neural networks, focusing on improving search efficiency using parallel computing techniques. The authors achieved significant speedups by creating their own evolutionary algorithms and leveraging parallelism, resulting in faster and more effective hyperparameter searches compared to traditional methods like grid and random search. Different approaches, such as 'island' strategies and iterative local evolutionary searches, were explored to enhance performance in high-dimensional hyperparameter spaces.




































































