Downloaded 27 times





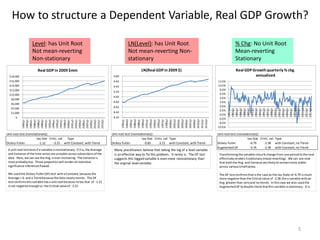
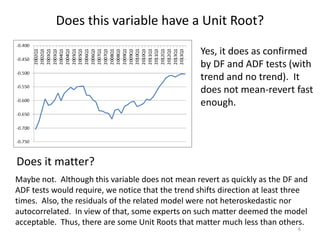
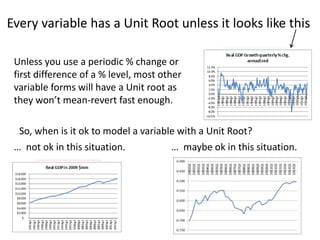






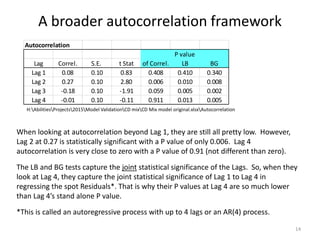
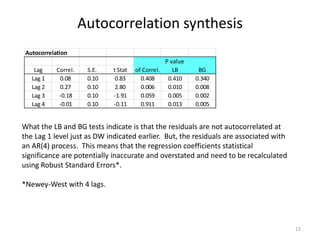









This document discusses unit roots, autocorrelation, and multicollinearity in econometric models, emphasizing the consequences of non-stationary variables. It presents methods for testing unit roots, highlighting the Dickey-Fuller tests and the importance of understanding residuals to avoid spurious regressions. Additionally, it addresses multicollinearity's effects on regression coefficients and statistical significance, offering insights on when modeling with unit root variables is acceptable.











































































































