The document provides a comprehensive overview of Redis, an in-memory data structure store that serves as a database, cache, or message broker. It details various data types supported by Redis, such as strings, lists, sets, sorted sets, and hashes, along with examples of commands for each data type. Additionally, it discusses the use of Redis for implementing the publish/subscribe paradigm in a project and highlights performance advantages and suitable use cases.






![Strings
Command line:
> set mystr foo
OK
> set myint 1
OK
> get mystr
"foo"
> append mystr foo
(integer) 6
> incr myint
(integer) 2
> mget mystr myint
1) "foofoo"
2) "2"
Are key-value pairs, to store strings or integers, with:
□Common operations on strings (APPEND, STRLEN, exc.);
□Atomic increment/decrement (INCR/DECR) on integers;
□Get multiple values at once (MGET).
Python:
>>> import redis
>>> r = redis.StrictRedis(
host='localhost',
port=6379, db=0
)
>>> r.set('mystr', 'foo')
True
>>> r.set('myint', 1)
True
>>> r.get('mystr')
'foo'
>>> r.append('mystr', 'foo')
6L
>>> r.incr('myint')
2
>>> r.mget('mystr', 'myint')
['foofoo', '2']
7](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-8-320.jpg)

![Interacting
with Lists
Command line:
> rpush mylist A
(integer) 1
> rpush mylist B
(integer) 2
> lpush mylist first
(integer) 3
> lrange mylist 0 ‐1
1) "first"
2) "A"
3) "B"
> lrange mylist 1 3
1) "A"
2) "B"
Python:
>>> import redis
>>> r = redis.StrictRedis(
host='localhost',
port=6379, db=0
)
>>> r.rpush('mylist', 'A')
1L
>>> r.rpush('mylist', 'B')
2L
>>> r.lpush('mylist', 'first')
3L
>>> r.lrange('mylist', 0, ‐1)
['first', 'A', 'B']
>>> r.lrange('mylist', 1, 3)
['A', 'B']
9](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-10-320.jpg)

![Interacting
with Sets
Command line:
> sadd myset A
(integer) 1
> sadd myset B
(integer) 1
> sadd myset2 C
(integer) 1
> sismember myset C
(integer) 0
> smembers myset
1) "A"
2) "B"
> sunion myset myset2
1) "A"
2) "B"
3) "C"
Python:
>>> import redis
>>> r = redis.StrictRedis(
host='localhost',
port=6379, db=0
)
>>> r.sadd('myset', 'A')
1
>>> r.sadd('myset', 'B')
1
>>> r.sadd('myset2', 'C')
1
>>> r.sismember('myset', 'C')
False
>>> r.smembers('myset')
set(['A', 'B'])
>>> r.sunion('myset', 'myset2')
set(['A', 'C', 'B'])
11](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-12-320.jpg)

![Interacting
with ZSETs
Command line:
> zadd myzset 2 C
(integer) 1
> zadd myzset 3 D
(integer) 1
> zadd myzset 1 A
(integer) 1
> zadd myzset 2 B
(integer) 1
> zrange myzset 0 ‐1
1) "A" 2) "B" 3) "C" 4) "D"
> zrangebyscore myzset 1 2
1) "A" 2) "B" 3) "C"
> zrangebylex myzset (A [D
1) "B" 2) "C" 3) "D"
Python:
>>> import redis
>>> r = redis.StrictRedis(
host='localhost',
port=6379, db=0
)
>>> r.zadd('myzset', 2, 'C')
1
>>> r.zadd('myzset', 3, 'D')
1
>>> r.zadd('myzset', A=1)
1
>>> r.zadd('myzset', B=2)
1
>>> r.zrange('myzset', 0, ‐1)
['A', 'B', 'C', 'D']
>>> r.zrangebyscore('myzset', 1, 2)
['A', 'B', 'C']
>>> r.zrangebylex('myzset', '(A', '[D')
['B', 'C', 'D']
13](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-14-320.jpg)

![Interacting
with Hashes
Command line:
> hset myhash key1 A
(integer) 1
> hmset myhash key2 B key3 C
OK
> hget myhash key2
"B"
> hmget myhash key1 key3
1) "A"
2) "C"
> hgetall myhash
1) "key1"
2) "A"
3) "key2"
4) "B"
5) "key3"
6) "C"
Python:
>>> import redis
>>> r = redis.StrictRedis(
host='localhost',
port=6379, db=0
)
>>> r.hset('myhash', 'key1', 'A')
1L
>>> r.hmset('myhash',
{'key2':'B', 'key3':'C'}
)
True
>>> r.hget('myhash', 'key2')
'B'
>>> r.hmget('myhash', 'key1', 'key3')
['A', 'C']
>>> r.hgetall('myhash')
{'key3': 'C', 'key2': 'B', 'key1': 'A'}
15](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-16-320.jpg)



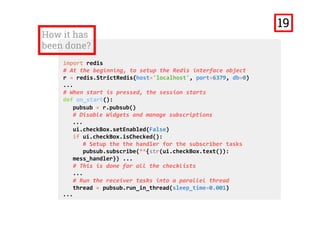

![How it has
been done? (2)
...
# Handler that pushes the received message onto the web‐chat
def mess_handler(message):
QtCore.QMetaObject.invokeMethod(ui.textEdit,
"append",QtCore.Q_ARG(str, str(message['data'])+'n'))
...
# To send a message when send is pressed
def on_send():
# Get the info about the message from the UI
msg = str(ui.textEdit_2.toPlainText())
if len(msg) > 0:
usrname = str(ui.lineEdit.text())
if len(usrname) == 0:
usrname = '<Anonymous>'
channel = str(ui.comboBox.currentText())
ui.textEdit_2.clear()
message = ‘%s [%s]: %s' % (usrname, channel, msg)
# Publish the message onto the specified channel
r.publish(channel, message)
...
21](https://image.slidesharecdn.com/redispresentationslideshare-160319161336/85/Redis-Usability-and-Use-Cases-22-320.jpg)


















































![[Individual presentation] android fragment](https://cdn.slidesharecdn.com/ss_thumbnails/individualpresentationandroidfragment-160421152630-thumbnail.jpg?width=640&height=640&fit=bounds)



































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)













