Download as PDF, PPTX


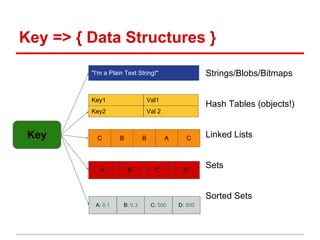










![Counter API (with redis internals)
counter = BitmapCounter('uniques', timeResolutions=(RES_DAY,))
#sampling current users
counter.add(userId)
> BITSET uniques:day:1339891200 <userId> 1
#Getting the unique user count for today
counter.getCount(time.time())
> BITCOUNT uniques:day:1339891200
#Getting the the weekly unique users in the past week
timePoints = [now() - 86400*i for i in xrange(7, 0, -1)]
counter.aggregateCounts(timePoints, counter.OP_TOTAL)
> BITOP OR tmp_key uniques:day:1339891200 uniques:day:1339804800 ....
> BITCOUNT tmp_key](https://image.slidesharecdn.com/kickingasswithredis-120618095415-phpapp02/85/Kicking-ass-with-redis-17-320.jpg)






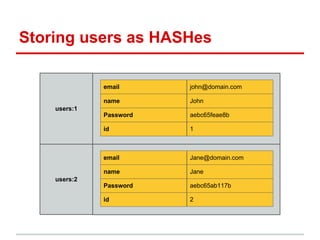
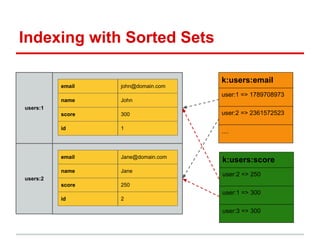
This document discusses using Redis to solve real world problems. It provides 4 patterns for using Redis: [1] as a simple, fast object store using hashes; [2] indexing objects with sorted sets; [3] using bitmaps for unique value counting; and [4] resolving locations with geohashing. Each pattern is explained and code examples are provided to illustrate how to model problems in Redis and leverage its data structures and performance. A variety of use cases are presented that can benefit from each pattern.









![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)