Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
直住
Uploaded by
直久 住川
436 views
第11回ACRiウェビナー_インテル/竹村様ご講演資料
第11回ACRiウェビナー_インテル/竹村様ご講演資料
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 53
2
/ 53
3
/ 53
4
/ 53
5
/ 53
6
/ 53
7
/ 53
8
/ 53
9
/ 53
10
/ 53
11
/ 53
12
/ 53
13
/ 53
14
/ 53
15
/ 53
16
/ 53
17
/ 53
18
/ 53
19
/ 53
20
/ 53
21
/ 53
22
/ 53
23
/ 53
24
/ 53
25
/ 53
26
/ 53
27
/ 53
28
/ 53
29
/ 53
30
/ 53
31
/ 53
32
/ 53
33
/ 53
34
/ 53
35
/ 53
36
/ 53
37
/ 53
38
/ 53
39
/ 53
40
/ 53
41
/ 53
42
/ 53
43
/ 53
44
/ 53
45
/ 53
46
/ 53
47
/ 53
48
/ 53
49
/ 53
50
/ 53
51
/ 53
52
/ 53
53
/ 53
More Related Content
PDF
第11回ACRiウェビナー_東工大/坂本先生ご講演資料
by
直久 住川
PDF
FPGA+SoC+Linux実践勉強会資料
by
一路 川染
PDF
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
PDF
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
PDF
20180729 Preferred Networksの機械学習クラスタを支える技術
by
Preferred Networks
PDF
深層学習向け計算機クラスター MN-3
by
Preferred Networks
PDF
Topology Managerについて / Kubernetes Meetup Tokyo 50
by
Preferred Networks
PDF
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
第11回ACRiウェビナー_東工大/坂本先生ご講演資料
by
直久 住川
FPGA+SoC+Linux実践勉強会資料
by
一路 川染
Tensor flow usergroup 2016 (公開版)
by
Hiroki Nakahara
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
20180729 Preferred Networksの機械学習クラスタを支える技術
by
Preferred Networks
深層学習向け計算機クラスター MN-3
by
Preferred Networks
Topology Managerについて / Kubernetes Meetup Tokyo 50
by
Preferred Networks
大規模DCのネットワークデザイン
by
Masayuki Kobayashi
What's hot
PDF
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
PDF
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
PPTX
自宅インフラの育て方 第2回
by
富士通クラウドテクノロジーズ株式会社
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PPTX
Azure仮想マシンと仮想ネットワーク
by
Kuninobu SaSaki
PDF
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正版)」
by
ManaMurakami1
PPTX
Edge Computing と k8s でなんか話すよ
by
VirtualTech Japan Inc.
PDF
カスタムメモリマネージャと高速なメモリアロケータについて
by
alwei
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
CXL_説明_公開用.pdf
by
Yasunori Goto
PDF
TensorFlow XLAは、 中で何をやっているのか?
by
Mr. Vengineer
PDF
オンラインゲームの仕組みと工夫
by
Yuta Imai
PPTX
YoctoをつかったDistroの作り方とハマり方
by
wata2ki
PDF
ZynqMPのブートとパワーマネージメント : (ZynqMP Boot and Power Management)
by
Mr. Vengineer
PDF
いまさら聞けないパスワードの取り扱い方
by
Hiroshi Tokumaru
PDF
GPU仮想化最前線 - KVMGTとvirtio-gpu -
by
zgock
PDF
年の瀬!リアルタイム通信ゲームサーバ勉強会
by
monobit
PDF
20111015 勉強会 (PCIe / SR-IOV)
by
Kentaro Ebisawa
PDF
Pcapngを読んでみる
by
Yagi Shinnosuke
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
オンプレML基盤on Kubernetes 〜Yahoo! JAPAN AIPF〜
by
Yahoo!デベロッパーネットワーク
自宅インフラの育て方 第2回
by
富士通クラウドテクノロジーズ株式会社
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
Azure仮想マシンと仮想ネットワーク
by
Kuninobu SaSaki
「NVIDIA プロファイラを用いたPyTorch学習最適化手法のご紹介(修正版)」
by
ManaMurakami1
Edge Computing と k8s でなんか話すよ
by
VirtualTech Japan Inc.
カスタムメモリマネージャと高速なメモリアロケータについて
by
alwei
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
CXL_説明_公開用.pdf
by
Yasunori Goto
TensorFlow XLAは、 中で何をやっているのか?
by
Mr. Vengineer
オンラインゲームの仕組みと工夫
by
Yuta Imai
YoctoをつかったDistroの作り方とハマり方
by
wata2ki
ZynqMPのブートとパワーマネージメント : (ZynqMP Boot and Power Management)
by
Mr. Vengineer
いまさら聞けないパスワードの取り扱い方
by
Hiroshi Tokumaru
GPU仮想化最前線 - KVMGTとvirtio-gpu -
by
zgock
年の瀬!リアルタイム通信ゲームサーバ勉強会
by
monobit
20111015 勉強会 (PCIe / SR-IOV)
by
Kentaro Ebisawa
Pcapngを読んでみる
by
Yagi Shinnosuke
Similar to 第11回ACRiウェビナー_インテル/竹村様ご講演資料
PDF
PCCC22:インテル株式会社 テーマ1「インテル® Agilex™ FPGA デバイス 最新情報」
by
PC Cluster Consortium
PDF
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
PDF
FPGAを用いたEdge AIの現状
by
Yukitaka Takemura
PDF
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
PDF
ACRi panel_discussion_xilinx_hayashida_rev1.0
by
直久 住川
PDF
GTC 2020 発表内容まとめ
by
Aya Owosekun
PDF
GTC 2020 発表内容まとめ
by
NVIDIA Japan
PPTX
FPGAって、何?
by
Toyohiko Komatsu
PDF
ICD/CPSY 201412
by
Takefumi MIYOSHI
PDF
CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 1
by
Computational Materials Science Initiative
PDF
Reconf_201409
by
Takefumi MIYOSHI
PDF
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
PDF
藤枝先生ご講演資料_20210824_de10
by
直久 住川
PDF
CMD2021 f01 xilinx_20210921_r1.1
by
Yoshihiro Horie
PPTX
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
PDF
Vitisのご紹介とAmazon EC2 F1体験デモ
by
Jun Ando
PDF
Intel True Scale Fabric
by
Naoto MATSUMOTO
PDF
インテルが考える次世代ファブリック
by
Naoto MATSUMOTO
PDF
BOSTON Viridis for Hadoop by ELSA Japan
by
Atsushi Suzuki
PDF
Parallel Technology
by
Visual Studio Users Group Japan
PCCC22:インテル株式会社 テーマ1「インテル® Agilex™ FPGA デバイス 最新情報」
by
PC Cluster Consortium
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
FPGAを用いたEdge AIの現状
by
Yukitaka Takemura
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
ACRi panel_discussion_xilinx_hayashida_rev1.0
by
直久 住川
GTC 2020 発表内容まとめ
by
Aya Owosekun
GTC 2020 発表内容まとめ
by
NVIDIA Japan
FPGAって、何?
by
Toyohiko Komatsu
ICD/CPSY 201412
by
Takefumi MIYOSHI
CMSI計算科学技術特論B(15) インテル Xeon Phi コプロセッサー向け最適化、並列化概要 1
by
Computational Materials Science Initiative
Reconf_201409
by
Takefumi MIYOSHI
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
藤枝先生ご講演資料_20210824_de10
by
直久 住川
CMD2021 f01 xilinx_20210921_r1.1
by
Yoshihiro Horie
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
Vitisのご紹介とAmazon EC2 F1体験デモ
by
Jun Ando
Intel True Scale Fabric
by
Naoto MATSUMOTO
インテルが考える次世代ファブリック
by
Naoto MATSUMOTO
BOSTON Viridis for Hadoop by ELSA Japan
by
Atsushi Suzuki
Parallel Technology
by
Visual Studio Users Group Japan
More from 直久 住川
PDF
第9回ACRiウェビナー_セック/岩渕様ご講演資料
by
直久 住川
PDF
公開用_講演資料_SCSK.pdf
by
直久 住川
PDF
DSF実行委員長_酒井様_講演資料
by
直久 住川
PDF
第9回ACRiウェビナー_日立/島田様ご講演資料
by
直久 住川
PDF
20th ACRi Webinar - Kyoto SU Oura-san Presentation
by
直久 住川
PDF
VCK5000_Webiner_GIGABYTE様ご講演資料
by
直久 住川
PDF
20th ACRi Webinar - Kyoto SU Presentation
by
直久 住川
PDF
17th_ACRi_Webinar_Sadasue-san_Slide_20240724
by
直久 住川
PDF
ACRiルーム副室長_安藤様_講演資料
by
直久 住川
PDF
20th ACRi Webiner - Presentation by MathWorks
by
直久 住川
PDF
20220525_kobayashi.pdf
by
直久 住川
PDF
220526_ACRi_Ando01r.pdf
by
直久 住川
PDF
18th ACRi Webinar : Presentation Slide ; Fukuda-san, ChipTip Technology
by
直久 住川
PDF
VCK5000_Webiner_Fixstars様ご講演資料
by
直久 住川
PDF
16th_ACRi_Webinar_Kumamoto-Univ_Okawa_20240308.pdf
by
直久 住川
PDF
16th_ACRi_Webiner_SEC_Takebe_20240308.pdf
by
直久 住川
PDF
ACRi-Webinar_Feb2023_agenda_20230225.pdf
by
直久 住川
PDF
ACRi事務局_住川_講演資料
by
直久 住川
PDF
2022-12-17-room.pdf
by
直久 住川
PDF
18th ACRi Webinar : Presentation Material - Prof. Yamaguchi
by
直久 住川
第9回ACRiウェビナー_セック/岩渕様ご講演資料
by
直久 住川
公開用_講演資料_SCSK.pdf
by
直久 住川
DSF実行委員長_酒井様_講演資料
by
直久 住川
第9回ACRiウェビナー_日立/島田様ご講演資料
by
直久 住川
20th ACRi Webinar - Kyoto SU Oura-san Presentation
by
直久 住川
VCK5000_Webiner_GIGABYTE様ご講演資料
by
直久 住川
20th ACRi Webinar - Kyoto SU Presentation
by
直久 住川
17th_ACRi_Webinar_Sadasue-san_Slide_20240724
by
直久 住川
ACRiルーム副室長_安藤様_講演資料
by
直久 住川
20th ACRi Webiner - Presentation by MathWorks
by
直久 住川
20220525_kobayashi.pdf
by
直久 住川
220526_ACRi_Ando01r.pdf
by
直久 住川
18th ACRi Webinar : Presentation Slide ; Fukuda-san, ChipTip Technology
by
直久 住川
VCK5000_Webiner_Fixstars様ご講演資料
by
直久 住川
16th_ACRi_Webinar_Kumamoto-Univ_Okawa_20240308.pdf
by
直久 住川
16th_ACRi_Webiner_SEC_Takebe_20240308.pdf
by
直久 住川
ACRi-Webinar_Feb2023_agenda_20230225.pdf
by
直久 住川
ACRi事務局_住川_講演資料
by
直久 住川
2022-12-17-room.pdf
by
直久 住川
18th ACRi Webinar : Presentation Material - Prof. Yamaguchi
by
直久 住川
Recently uploaded
PDF
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ...
by
dots.
PDF
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】
by
dots.
PDF
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境
by
Masahiro Takechi
PDF
krsk_aws_re-growth_aws_devops_agent_20251211
by
uedayuki
PDF
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研
by
yohakugiken
PPTX
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx
by
rintakano624
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ...
by
dots.
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】
by
dots.
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境
by
Masahiro Takechi
krsk_aws_re-growth_aws_devops_agent_20251211
by
uedayuki
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研
by
yohakugiken
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx
by
rintakano624
第11回ACRiウェビナー_インテル/竹村様ご講演資料
1.
第11回 ACRi ウェビナー ACRI
ルームにも導入! インテル®️ Agilex™ FPGA ボードを使ってみる インテル株式会社 プログラマブル・ソリューションズ営業本部 シニア・テクノロジー・スペシャリストFAE 竹村 幸尚
2.
インテル® FPGA デバイスの概要
3.
4 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® FPGA ポートフォリオ あらゆるアプリケーションに対応 低コスト 低消費電力 データ中心の時代 に向けた新製品 低コストと 低消費電力の 最適なバランス ミッドレンジ 製品 広帯域幅向けに 最適化
4.
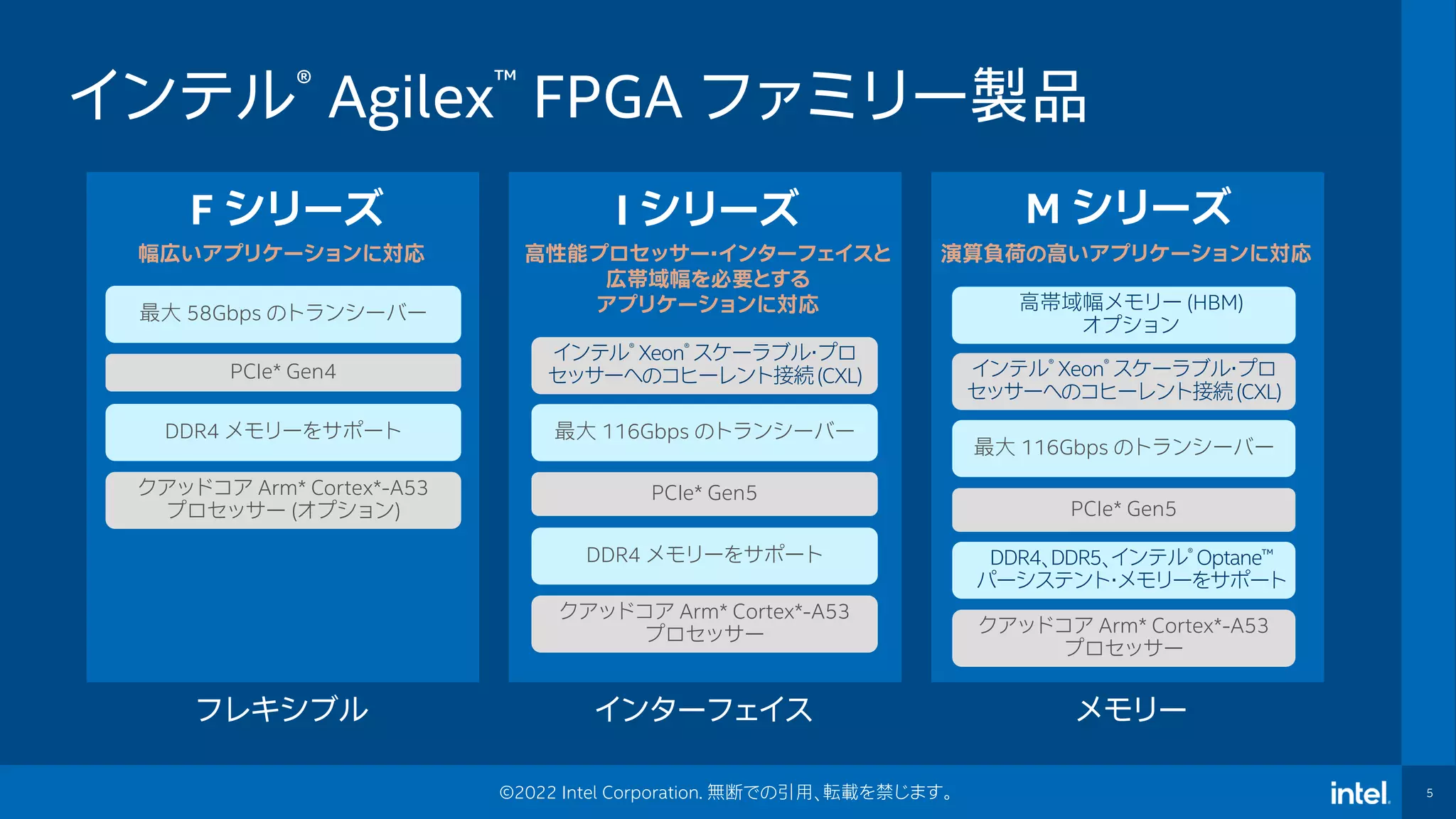
5 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® Agilex™ FPGA ファミリー製品 F シリーズ 幅広いアプリケーションに対応 クアッドコア Arm* Cortex*-A53 プロセッサー (オプション) DDR4 メモリーをサポート PCIe* Gen4 最大 58Gbps のトランシーバー I シリーズ 高性能プロセッサー・インターフェイスと 広帯域幅を必要とする アプリケーションに対応 クアッドコア Arm* Cortex*-A53 プロセッサー DDR4 メモリーをサポート PCIe* Gen5 最大 116Gbps のトランシーバー インテル® Xeon® スケーラブル・プロ セッサーへのコヒーレント接続(CXL) M シリーズ 演算負荷の高いアプリケーションに対応 クアッドコア Arm* Cortex*-A53 プロセッサー DDR4、DDR5、インテル® Optane™ パーシステント・メモリーをサポート PCIe* Gen5 最大 116Gbps のトランシーバー インテル® Xeon® スケーラブル・プロ セッサーへのコヒーレント接続(CXL) 高帯域幅メモリー (HBM) オプション フレキシブル インターフェイス メモリー
5.
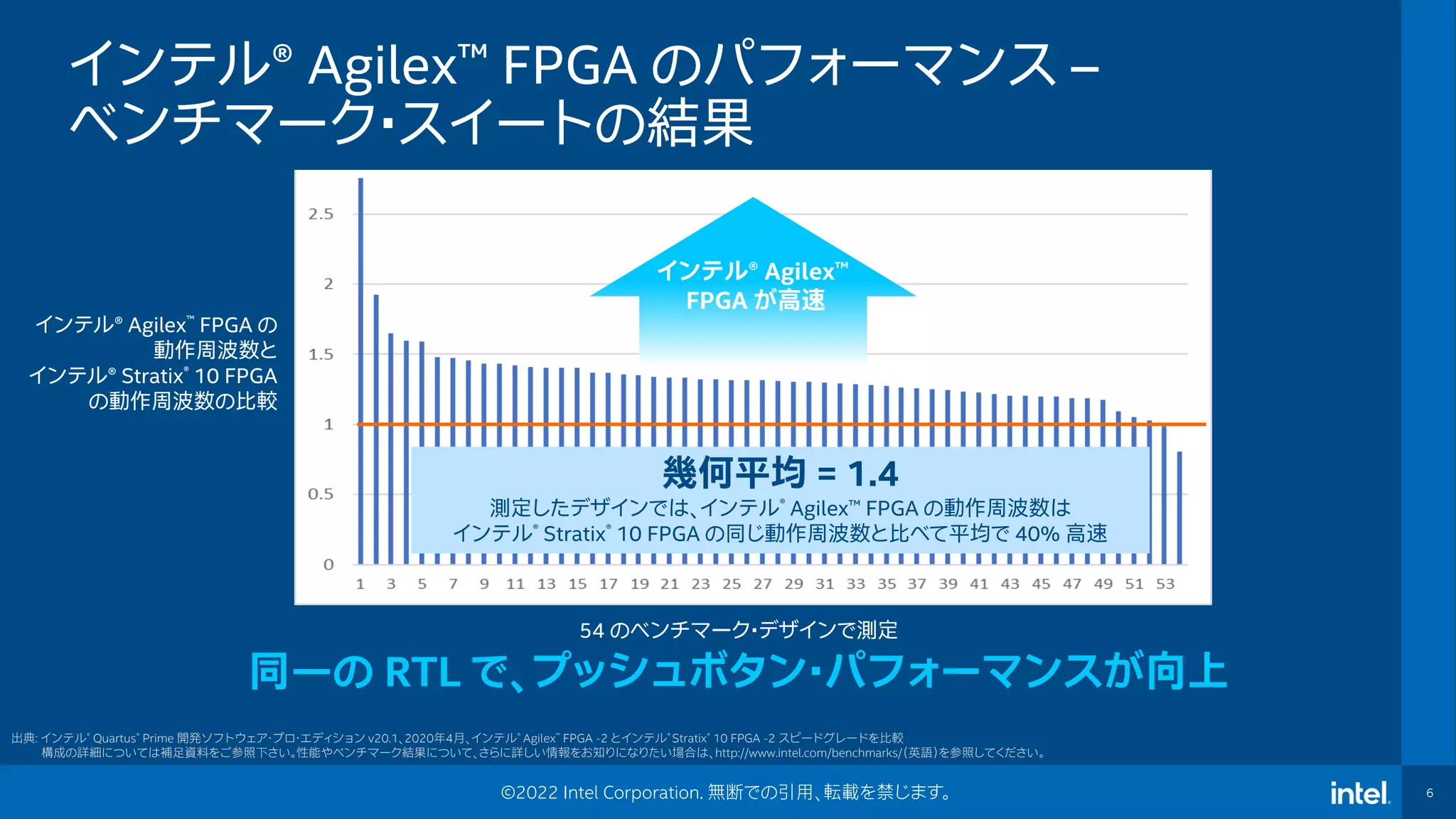
6 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® Agilex™ FPGA のパフォーマンス – ベンチマーク・スイートの結果 出典: インテル® Quartus® Prime 開発ソフトウェア・プロ・エディション v20.1、2020年4月、インテル® Agilex™ FPGA -2 とインテル® Stratix® 10 FPGA -2 スピードグレードを比較 構成の詳細については補足資料をご参照下さい。性能やベンチマーク結果について、さらに詳しい情報をお知りになりたい場合は、http://www.intel.com/benchmarks/(英語)を参照してください。 インテル® Agilex™ FPGA の 動作周波数と インテル® Stratix® 10 FPGA の動作周波数の比較 インテル® Agilex™ FPGA が高速 幾何平均 = 1.4 測定したデザインでは、インテル® Agilex™ FPGA の動作周波数は インテル® Stratix® 10 FPGA の同じ動作周波数と比べて平均で 40% 高速 同一の RTL で、プッシュボタン・パフォーマンスが向上 54 のベンチマーク・デザインで測定
6.
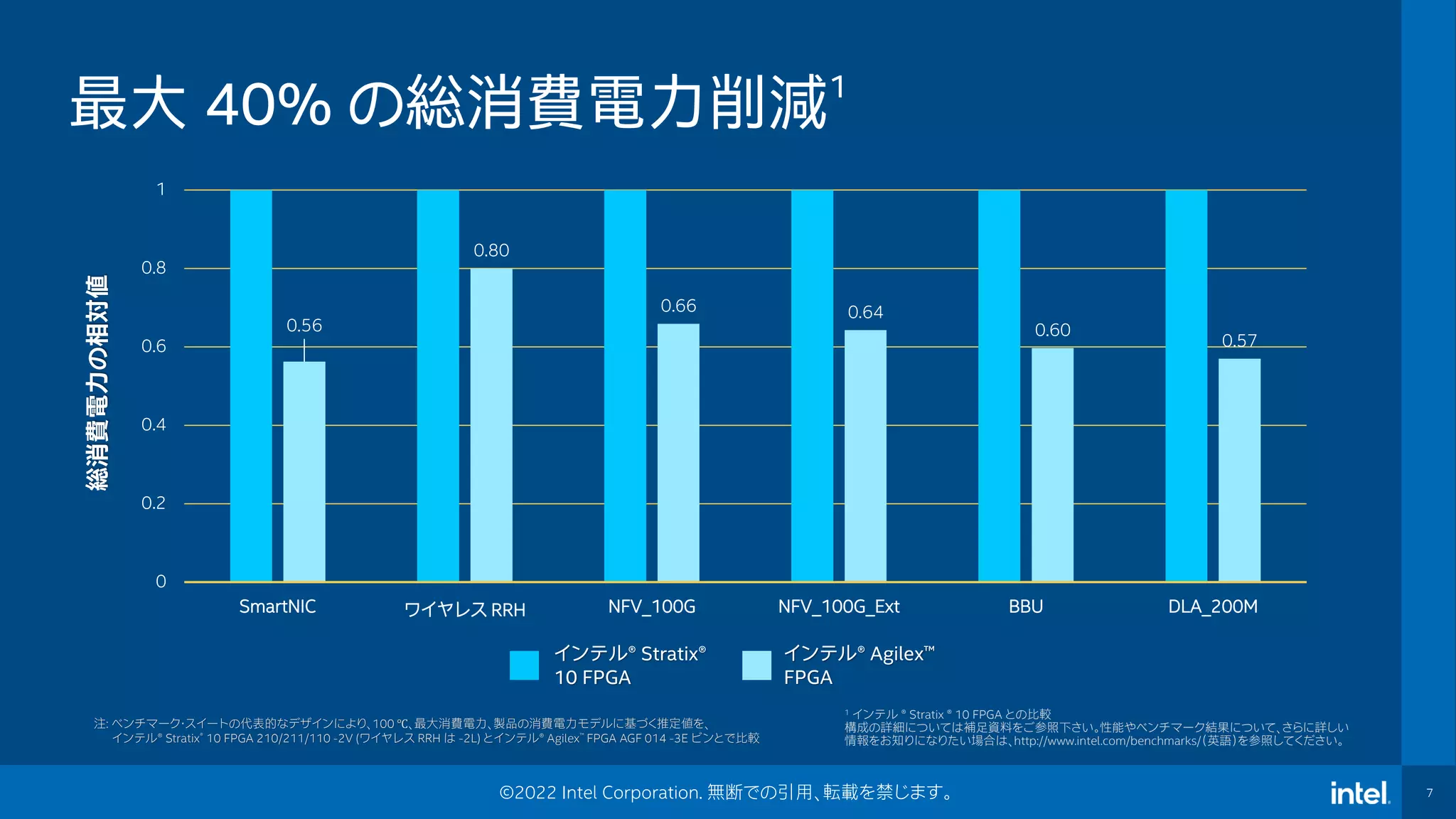
7 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 最大 40% の総消費電力削減1 0.56 0.80 0.66 0.64 0.60 0.57 0 0.2 0.4 0.6 0.8 1 SmartNIC ワイヤレス RRH NFV_100G NFV_100G_Ext BBU DLA_200M 総消費電力の相対値 インテル® Agilex™ FPGA インテル® Stratix® 10 FPGA 注: ベンチマーク・スイートの代表的なデザインにより、100 ℃、最大消費電力、製品の消費電力モデルに基づく推定値を、 インテル® Stratix® 10 FPGA 210/211/110 -2V (ワイヤレス RRH は -2L) とインテル® Agilex™ FPGA AGF 014 -3E ビンとで比較 1 インテル ® Stratix ® 10 FPGA との比較 構成の詳細については補足資料をご参照下さい。性能やベンチマーク結果について、さらに詳しい 情報をお知りになりたい場合は、http://www.intel.com/benchmarks/(英語)を参照してください。
7.
8 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® Agilex™ FPGA の DSP 性能 新機能: 半精度浮動小数点 (FP16) と BFLOAT16 (BF16) • 画像 / オブジェクト検出用のマシンラーニング、畳み込み ニューラル・ネットワーク (CNN) エンジンをサポート • 単精度浮動小数点 (FP32) から 50% の消費電力削減1 • FP16、BF16 演算は効率が 2 倍2 9x9 乗算器を DSP ブロック当たり 4 つに増加 • 低精度の固定小数点演算効率が 2 倍 受賞歴のある DSP アーキテクチャー を強化 1 データシートの仕様に基づく、インテル® Agilex™ FPGA の DSP ブロック FP16 とインテル® Stratix® 10 FPGA の DSP ブロック FP32 の比較 2 データシートの仕様に基づくと、インテル® Agilex™ FPGA の DSP ブロックは、インテル® Stratix® 10 FPGA の DSP ブロックに比べて、実装できるブロック当たりの FP16 または BFLOAT16 の数が 2 倍 構成の詳細については補足資料をご参照下さい。性能やベンチマーク結果について、さらに詳しい情報をお知りになりたい場合は、http://www.intel.com/benchmarks/(英語)を参照してください。
8.
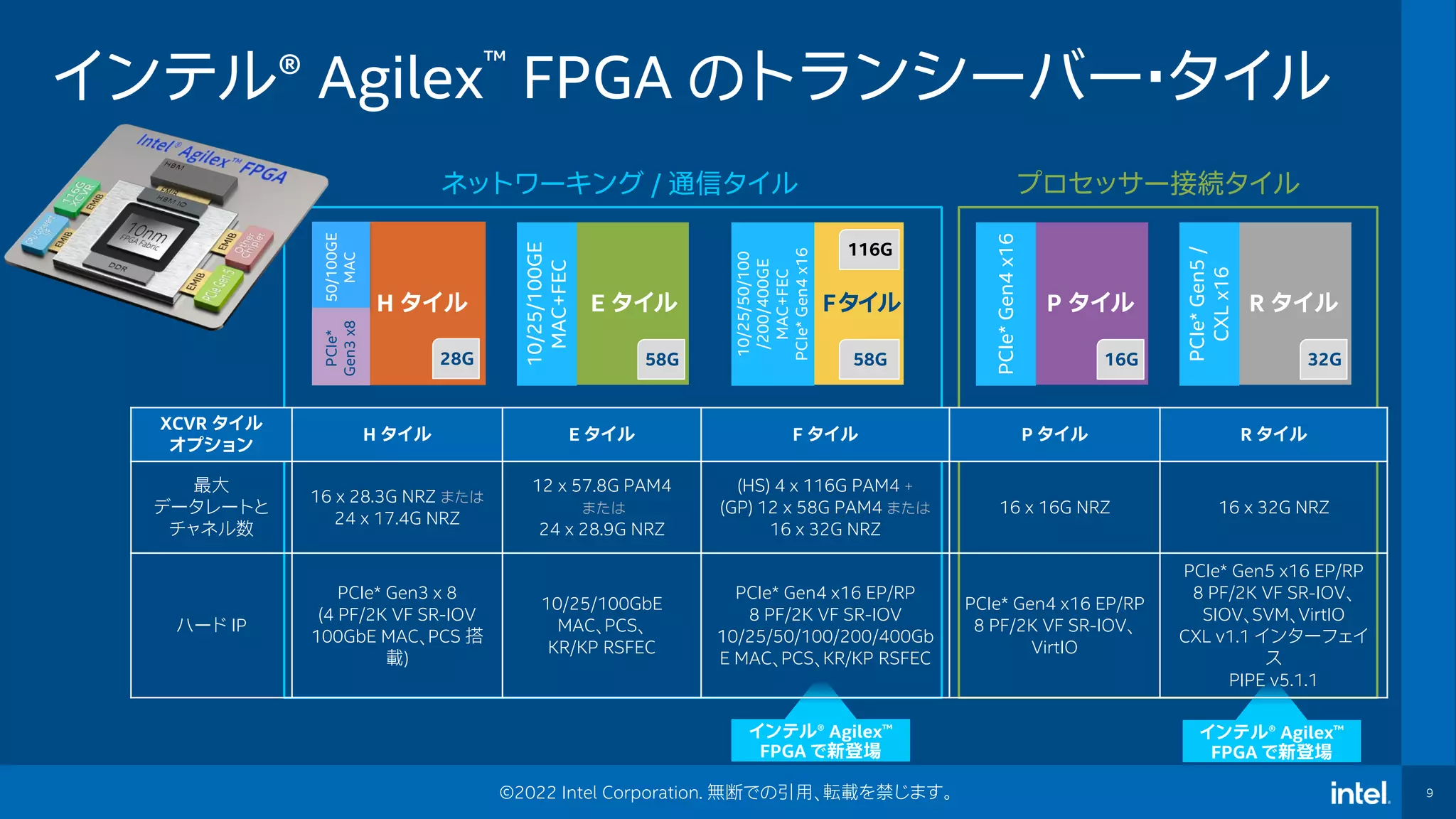
9 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® Agilex™ FPGA のトランシーバー・タイル H タイル 28G 50/100GE MAC PCIe* Gen3 x8 E タイル 58G 10/25/100GE MAC+FEC P タイル 16G PCIe* Gen4 x16 R タイル 32G PCIe* Gen5 / CXL x16 Fタイル 58G 10/25/50/100 /200/400GE MAC+FEC PCIe* Gen4 x16 116G プロセッサー接続タイル ネットワーキング / 通信タイル インテル® Agilex™ FPGA で新登場 インテル® Agilex™ FPGA で新登場 XCVR タイル オプション H タイル E タイル F タイル P タイル R タイル 最大 データレートと チャネル数 16 x 28.3G NRZ または 24 x 17.4G NRZ 12 x 57.8G PAM4 または 24 x 28.9G NRZ (HS) 4 x 116G PAM4 + (GP) 12 x 58G PAM4 または 16 x 32G NRZ 16 x 16G NRZ 16 x 32G NRZ ハード IP PCIe* Gen3 x 8 (4 PF/2K VF SR-IOV 100GbE MAC、PCS 搭 載) 10/25/100GbE MAC、PCS、 KR/KP RSFEC PCIe* Gen4 x16 EP/RP 8 PF/2K VF SR-IOV 10/25/50/100/200/400Gb E MAC、PCS、KR/KP RSFEC PCIe* Gen4 x16 EP/RP 8 PF/2K VF SR-IOV、 VirtIO PCIe* Gen5 x16 EP/RP 8 PF/2K VF SR-IOV、 SIOV、SVM、VirtIO CXL v1.1 インターフェイ ス PIPE v5.1.1
9.
Intel Confidential Department or
Event Name 10 10 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 F タイル – ネットワーキングと通信 • 3 つのハード IP ブロック • 最大 116Gbps のトランシーバー • PCIe 4.0 ハード IP • 400GbE ハード IP • マルチプロトコルに対応 • イーサネット、PCIe 4.0、CPRI、 OTN、JESD204B/C、FlexE、 Interlaken、ファイバーチャネル、 InfiniBand、SRIO、Serial Lite、 GPON、FlexO、SDI、Vby1、HDMI、 DisplayPort 4.0
10.
Intel Confidential Department or
Event Name 11 11 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 新しい標準規格やアプリケーションに対応 • 進化は続く • 800Gb / 1600Gb イーサネットと OTN 規格 • 将来的な運用を見込んで、現在インテルは テストチップを 224Gbps で稼動中 224Gbps テストチップのアイ・ダイアグラム
11.
12 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 Intel 7 プロセス技術 第 12 世代インテル® Core™ プロセッサー・ファミリー で採用 * グラフィックスは例示のみを目的としており、実際の縮尺どおりではありません。 インテル社内での推定値。結果は異なる場合があります。プロセス技術の準備完了時期は、必ずしも製品の生産時期を示すものではありません。詳細については、http://www.Intel.com/PerformanceIndex/ (英語) を参照してください。結果は異なる場合があります。 ▪ 消費電力当たりの性能が最大 10% 向上 ▪ 地理的に異なる世界中の複数の製造施設から供給する ことでサプライチェーンの耐障害性を確保
12.
13 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 新しいインテル® Agilex™ FPGA (開発コード名: Sundance Mesa) エッジ / 組込みアプリケーション向けに 業界トップレベルの電力効率を Intel 7 プロセス技術で実現 ▪ 消費電力当たりの性能が競合 16nm FPGA に比べて約1.6 倍1 ▪ Cyclone® V FPGA に比べて消費電力が最大 50% 低減、または性能が 2.5 倍向上 エッジ / 組込み機器のイノベーションを推進する数々の新機能 ▪ AI Tensor ブロックを統合した拡張DSP機能 ▪ 低レイテンシー、広帯域幅の AI 推論向けに、高密度の INT8 コンピューティングを比類のない使いやすさで実現 ▪ アシンメトリックなアプリケーション・プロセッサー・クラスターによるワークロードの最適化 (高性能の Arm A76 x2 + 電力効率に優れた A55 x2) ▪ セキュア・デバイス・マネージャー (SDM) による高度なセキュリティー エッジに最適 ▪ 低集積でコンパクトなフォームファクター (最小で50K-LE 、 15mm角パッケージより提供) ▪ 複数の接続規格に対応: SDI、DP、HDMI、MIPI、TSN ▪ 長いライフサイクル: 15 年以上利用可能 ▪ インダストリー 4.0、ビジョン、通信、防衛、データセンター、医療、テストなどに最適 電力効率に優れた 性能で エッジを駆動 注 (1): 1 免責条項: ワークロードと構成については補足資料を参照してください。結果は異なる場合があります (開発コード名: Sundance Mesa)
13.
Intel Confidential Department or
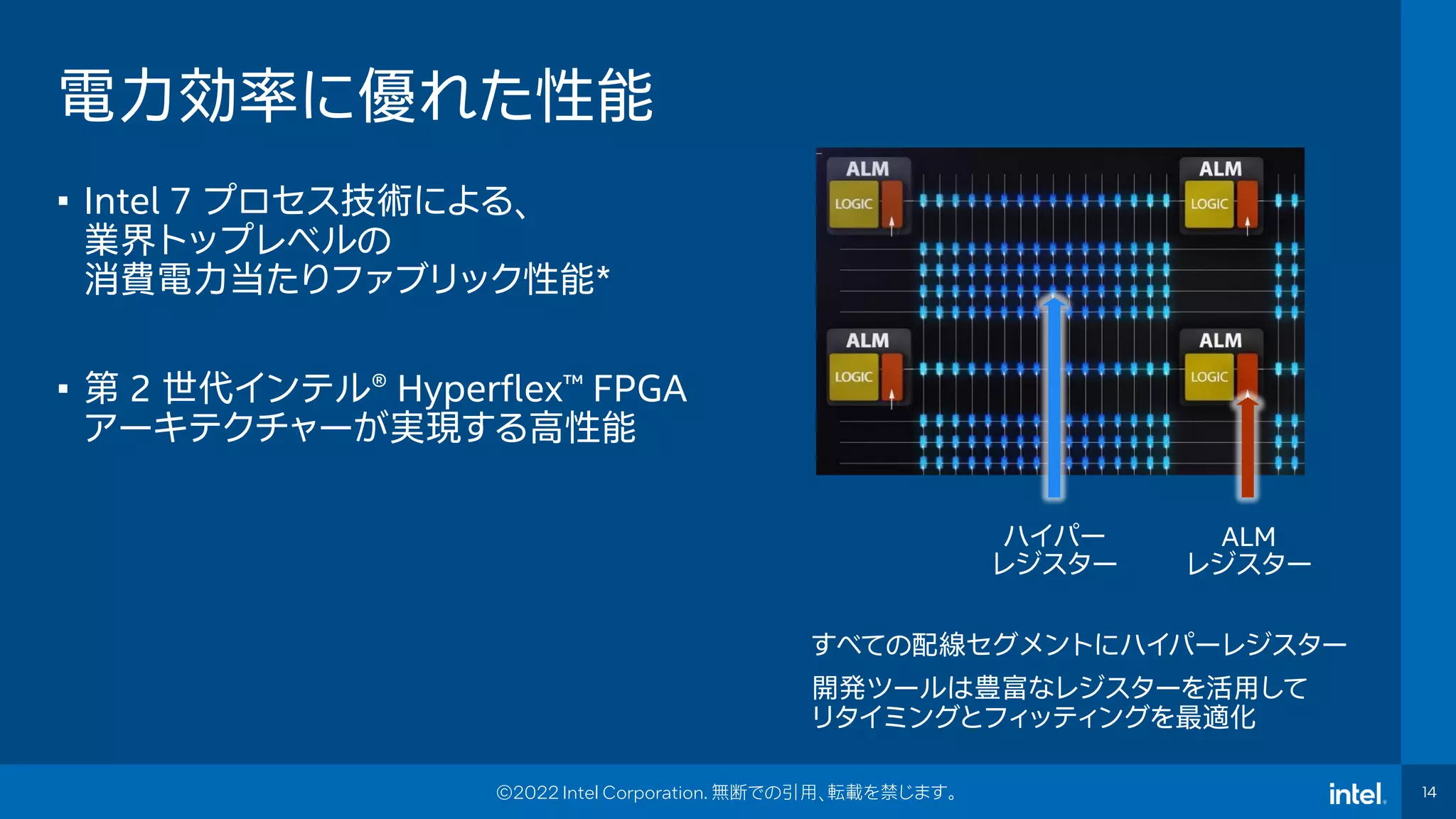
Event Name 14 14 Intel® FPGA Technology Day 14 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 電力効率に優れた性能 • Intel 7 プロセス技術による、 業界トップレベルの 消費電力当たりファブリック性能* • 第 2 世代インテル® Hyperflex™ FPGA アーキテクチャーが実現する高性能 ハイパー レジスター ALM レジスター すべての配線セグメントにハイパーレジスター 開発ツールは豊富なレジスターを活用して リタイミングとフィッティングを最適化
14.
Intel Confidential Department or
Event Name 15 15 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 ▪ 新しいインテル® Agilex™ FPGA (開発コード名: Sundance Mesa) の INT8 性能 は最大 26TOPS ▪ エッジ AI アプリケーションに最適な、AI Tensor ブロックを搭載した新しい FPGA シリーズ ▪ インテル® FPGA AI スイートでサポート ▪ インテル® FPGA AI スイートは業界標準フレームワークから FPGA ビットスト リームまでのワンクリック・フローを実現 [例: Caffe、PyTorch、TensorFlow] AI Tensor ブロックを搭載した初のエッジセントリック FPGA デバイス 最大 INT8 TOPS 新しいインテル® Agilex™ FPGA での向上 Cyclone® V FPGA 1 26 倍 インテル® Arria® 10 FPGA 13 2 倍 インテル® Stratix® 10 FPGA (2.8M) 23 1.1 倍 SUNDANCE MESA AI Tensor ブロック 2- 18X19 MAC 1 INT16 CMULT 20 INT8 OPS
15.
16 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 インテル® Agilex™ D シリーズ FPGA インテル® Agilex™ デバイスの 性能をミッドレンジの FPGA アプリケーションに拡張 Intel 7 プロセス技術が実現する業界トップレベルの性能と消費電力 ▪ 消費電力当たりのファブリック性能が競合デバイスの約 2 倍1 ▪ インテル® Agilex™ F/I シリーズ FPGA と比べて総消費電力を最大 15% 削減 高度な機能 ▪ AI Tensor ブロックを統合した拡張 DSP を搭載した初の FPGA ▪ 比類のない使いやすさで、低レイテンシー、広帯域幅の AI 推論向けに最大 56.5 TOPS (INT8) を実現 ▪ 1 つの FPGA 内で初のアシンメトリック・アプリケーション・プロセッサー・クラスターに よりワークロードを最適化 (高性能の Arm A76 x2 + 電力効率に優れた A55 x2) ▪ 業界初の LPDDR5 メモリー I/F のサポート 組込み、通信、放送、その他幅広い市場にわたる ミッドレンジ FPGA アプリケーションに最適 ▪ 最小で100k LE、わずか 23 mm2のフォームファクター ▪ トランシーバー転送速度は最大 28G、 PCIe 4.0や25GbE をサポート ▪ 複数の接続規格に対応: SDI、DP、HDMI、MIPI、TSN 注 (1): 1 免責条項: ワークロードと構成については補足資料を参照してください。結果は異なる場合があります
16.
17 ©2022 Intel Corporation.
無断での引用、転載を禁じます。 最速の FPGA ハード・プロセッサー・サブシステム • 初の Arm v8.2 DynamIQ HPS • 各コアに初の専用 L2 キャッシュ • クラスターで共有される初の L3 キャッシュ • 電力効率の高い最適化を実現する初のアシ ンメトリックなクラスター • 初の Arm Cortex-A55 プロセッサー • Cortex-A53 と比べて効率が 15% 向上 • 初の Arm Cortex-A76 プロセッサー • 高性能と優れた電力効率 • 初の Arm v8.2-A NEON • IEEE FP16 のサポート • INT8 ドット積 HPS の優位性 • Cortex-A72 より高性能 • Cortex-A53 より高効率 • 最大容量のオンチップメモリー (512KB) • 最速の TSN イーサネット MAC (2.5Gbps) Arm DynamIQ の詳細については、https://www.arm.com/technologies/dynamiq/ (英語) を参照
17.
18 インテル® Agilex™ D
シリーズ FPGA と新しいインテル® Agilex™ FPGA (開発コード名: Sundance Mesa) の比較 インテル® Agilex™ D シリーズ FPGA 新しいインテル® Agilex™ FPGA (開発コード名: Sundance Mesa) 集積度 100k~644, LE 50k~656k LE パッケージサイズ 小型 (わずか 23mm2) さらに小型 (わずか 15mm2) 消費電力 インテル® Stratix® 10 FPGA より 40% 削減 Cyclone® V FPGA より 50% 削減 ファブリック性能 インテル® Stratix® 10 FPGA の 1.5 倍 Cyclone® V FPGA の 2.5 倍 DSP の 18x19 乗算器の最大数 3,680 1,692 最大 XCVR レート 28G 17G & 28G アプリケーションの特性 高性能、低消費電力、小型フォームファクター、低集積度 中程度の性能、さらに低い消費電力、 より小型のフォームファクター 使用例 8K ビデオカメラ / ビデオ転送、無線マクロセル、無線ユニット、 xHaul、安全な通信、航空電子 / 航空宇宙システム 産業用途 (ドライブ、PLC、モーター制御、ロボット)、ビデオ会 議 & コンパクト・ビデオカメラ、医療 / テスト / 計測用などの ポータブル機器 共通の特長 複数の接続規格: SDI、DP、HDMI、MIPI、TSN アシンメトリックHPS クラスター (2x Arm Cortex A76 + 2x Arm Cortex A55) PCIe 4.0、DDR4、DDR5、LPDDR4、LPDDR5 高性能 / 多機能 低集積 / 低消費電力
18.
インテル® FPGA デバイス 搭載ボード例
19.
Intel Confidential Department or
Event Name 20 20 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 汎用コンピューティング向けインテル®️ Agilex™ FPGA カード Molex 社 (Bittware) IA-860mカード IA-640iカード、IA-440iカード Terasic社 Terasic DE10-Agilex 開発ボード インテル®️ FPGA AI スイートで動作する PCIe オフロード・アクセラレーション デザインとデモを用意 PCIe 5.0/CXL対応、HBM2サポート インテル®️ Agilex™ M シリーズ カード PCIe 5.0/CXL 対応 インテル®️ Agilex™ I シリーズ カード Hitek社 インテル® Agilex™ AG014 ロープロファイル PCIe カード HiPrACC インテル®️ Agilex™ FPGA で インテル®️ OFS、OpenCL、 oneAPI をサポートする 完全ポーティング ハードウェア検証済みボード
20.
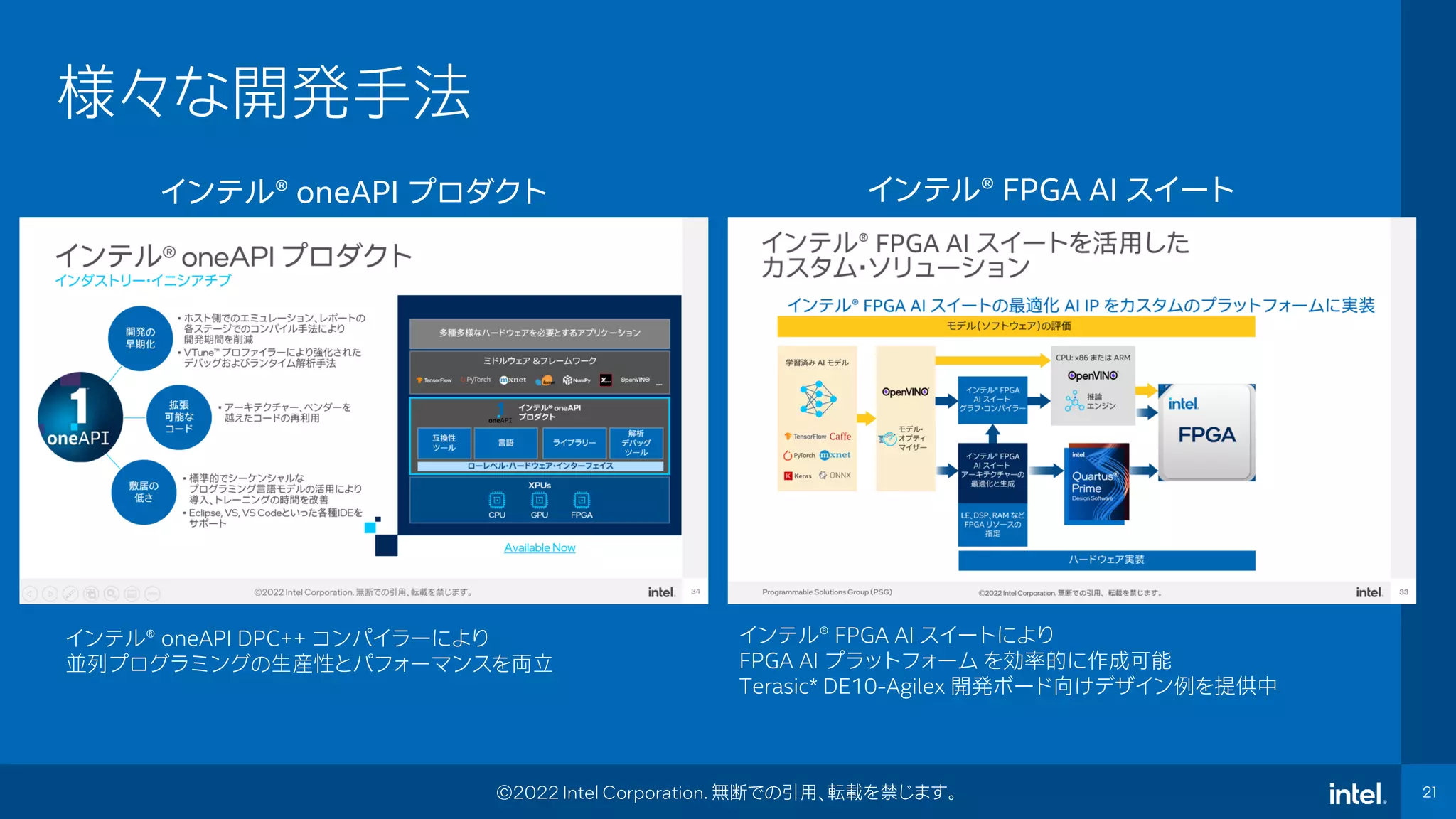
Intel Confidential Department or
Event Name 21 21 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 様々な開発手法 インテル® oneAPI プロダクト インテル®️ oneAPI DPC++ コンパイラーにより 並列プログラミングの生産性とパフォーマンスを両立 インテル®️ FPGA AI スイートにより FPGA AI プラットフォーム を効率的に作成可能 Terasic* DE10-Agilex 開発ボード向けデザイン例を提供中 インテル® FPGA AI スイート
21.
Intel Confidential Department or
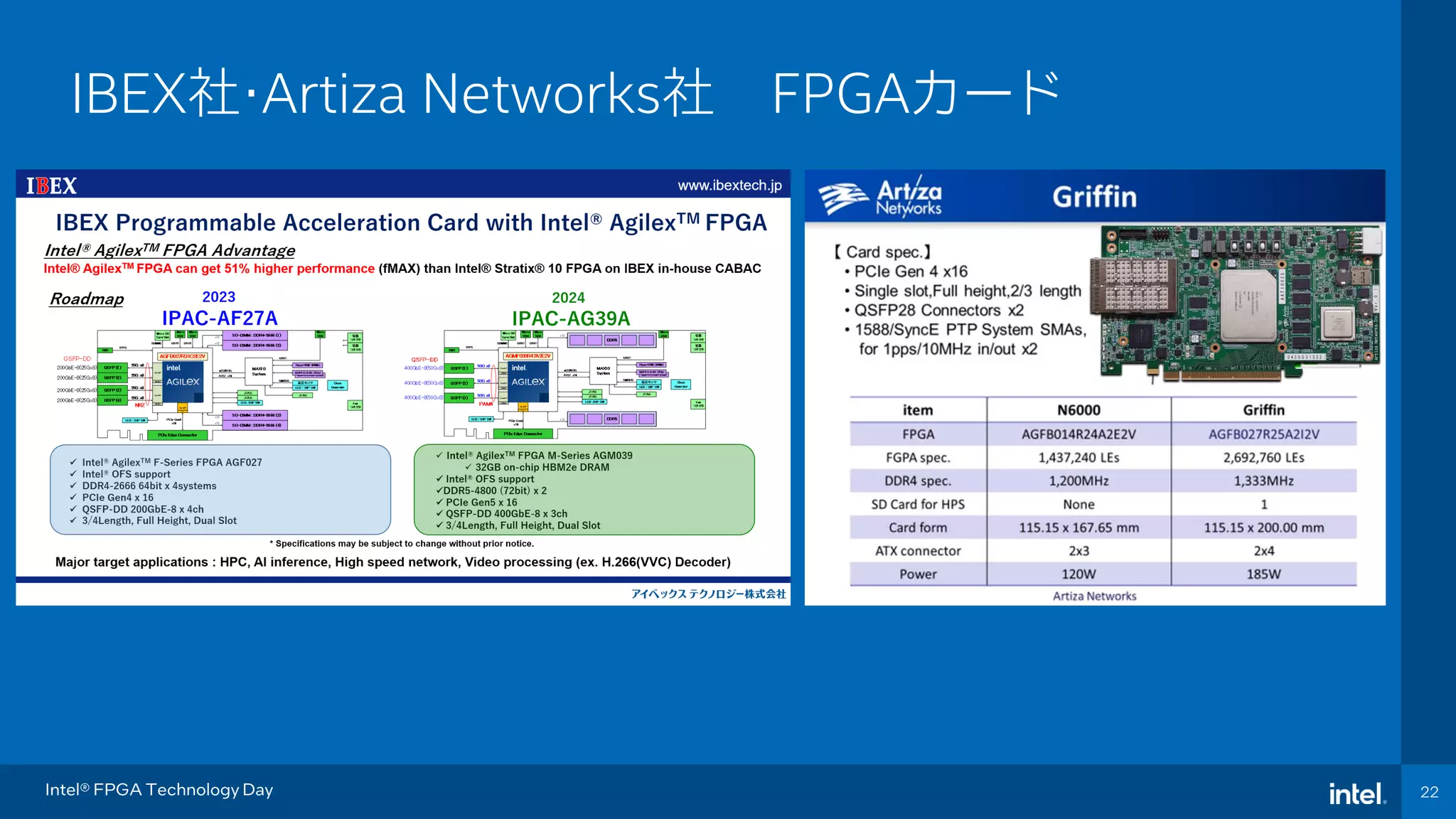
Event Name 22 22 Intel® FPGA Technology Day IBEX社・Artiza Networks社 FPGAカード
22.
oneAPI
23.
Intel Confidential Department or
Event Name 24 24 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 インテル®️ oneAPI の概要 オープンな業界仕様
24.
Intel Confidential Department or
Event Name 25 25 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 複数のアーキテクチャーで 構築する際のプログラミングの課題 スカラー ベクトル 空間 マトリクス ミドルウェア & フレームワーク アプリケーション・ワークロードには多様なハードウェアが必要 CPU プログラミング・ モデル GPU プログラミング・ モデル FPGA プログラミング・ モデル その他の アクセラレーター・ プログラミング・ モデル CPU GPU FPGA その他の アクセラレーター • 特殊なワークロードの増加 • 多種多様なデータセントリック・ハードウェアが必要 • 現時点ではアーキテクチャーごとに異なる プログラミング・モデルとツールチェーンが必要 • ソフトウェア開発の複雑さによって、選択できる アーキテクチャーが限られてしまう 開発者の 40% が、複数の種類のプロセッサー、プロセッサー・コア、 コプロセッサーを使用するヘテロジニアス・システムに照準を当てている 出典: Evans Data、「Global Development Survey Report 2020, Volume 2」
25.
Intel Confidential Department or
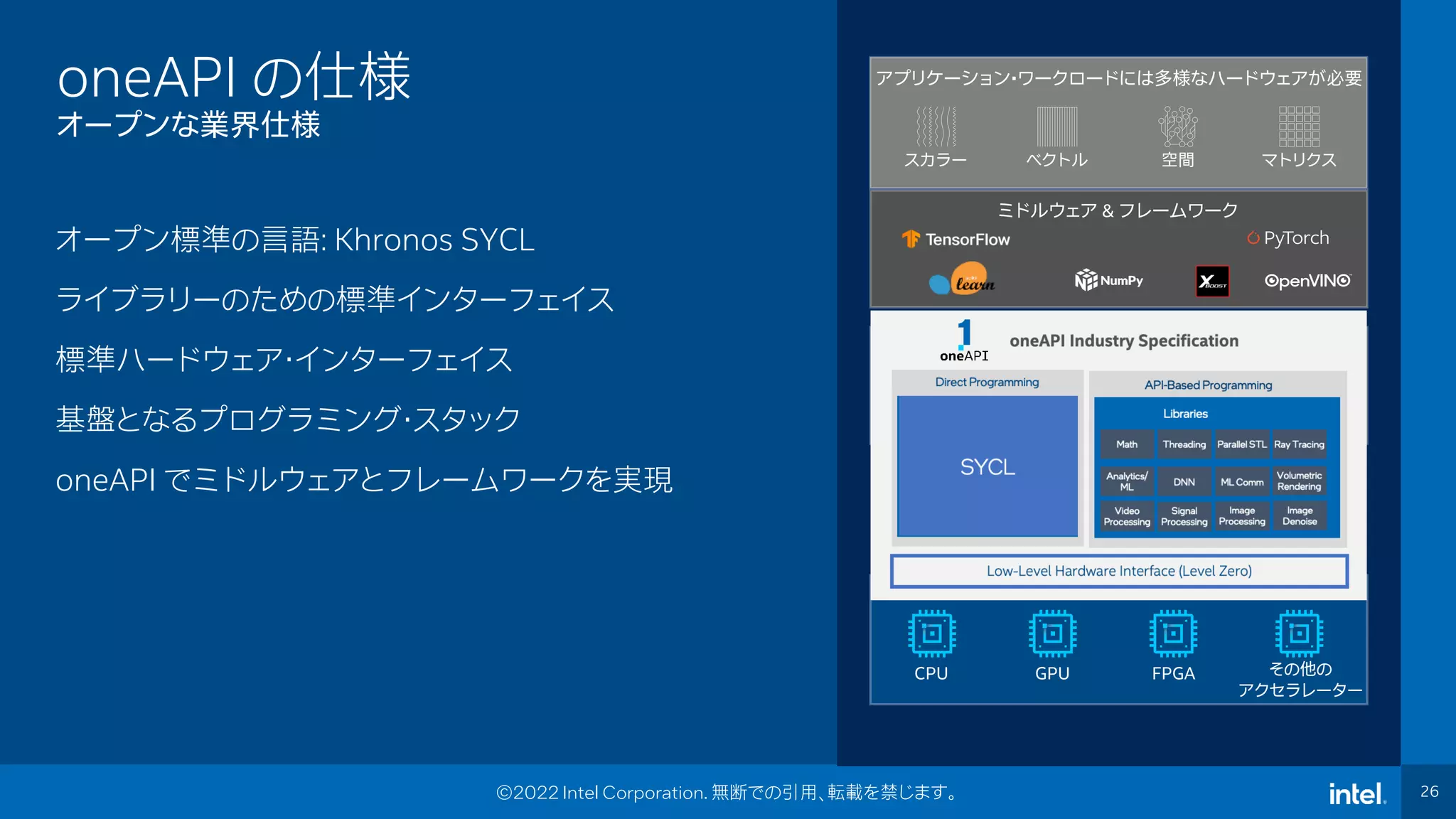
Event Name 26 26 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI の仕様 オープンな業界仕様 スカラー ベクトル 空間 マトリクス Middleware & Frameworks アプリケーション・ワークロードには多様なハードウェアが必要 CPU GPU FPGA その他の アクセラレーター ミドルウェア & フレームワーク オープン標準の言語: Khronos SYCL ライブラリーのための標準インターフェイス 標準ハードウェア・インターフェイス 基盤となるプログラミング・スタック oneAPI でミドルウェアとフレームワークを実現
26.
Intel Confidential Department or
Event Name 27 27 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI 製品 万全の FPGA サポート スカラー ベクトル 空間 マトリクス ミドルウェア & フレームワーク アプリケーション・ワークロードには多様なハードウェアが必要 CPU GPU FPGA その他の アクセラレーター 下位層のハードウェア・インターフェイス ライブラリー 言語 互換ツール 分析 & デバッグツール インテル® oneAPI 製品 開発 サイクルの 短縮 • エミュレーションによるソフトウェアの検証 • FPGA 最適化レポート • デバッグとランタイム分析 • 業界で広く利用されている インテル® VTune™ プロファイラー 拡張性のある ユーザー コード • ハードウェア並列処理のネイティブサポート • 複数のアーキテクチャー間でコードの再利用 が可能 • コミュニティー主導の言語 デザイン エントリーの 使いやすさ • 短期間でのランプアップ / トレーニング: • インテル® DevCloud で開始 • 共通のシーケンシャル・プログラミング言語 • 業界最先端の IDE であるVS、VS Code、Eclipse を サポート
27.
Intel Confidential Department or
Event Name 28 Intel® Programmable Solutions Group 28 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI インテルの実装 ▪ オープンな業界標準 ▪ Khronos Group が定義した仕様 ▪ コミュニティー主導 ▪ マルチベンダーの実装及び異なるハード ウェア間での機能移植性 SYCL (「シクル」と発音) は、ロイヤリティー・フリーのクロスプラットフォーム抽象化レイヤー です。アプリケーションのホストコードとカーネルコードを同一のソースファイル内に含め、 標準の ISO C++ 言語で記述する異種プロセッサーのコーディングを可能にします。 アクセラレーション / オフロード機能を C++ を使用して 単一ソースのヘテロジニアス・プログラミングで記述 ▪ オープンな業界仕様 ▪ オープンソースのリポジトリ-と開発 ▪ コミュニティー主導 ▪ マルチベンダーの実装をサポート ▪ インテルの実装 ▪ インテルのハードウェアに最適化された ツールキット ▪ 無償ダウンロードで入手可能 ▪ インテルで進行中の SYCL の実装 ▪ 使いやすい機能: ラムダ式、ユニファイド共有 メモリー (USM)、サブグループ、構文の簡略化、 ハードウェアのサポート ▪ SYCL 2020 仕様で取り入れられた多数の SYCL 拡張機能、SYCLサポートを LLVM/Clangにアップストリーム DPC++
28.
Intel Confidential Department or
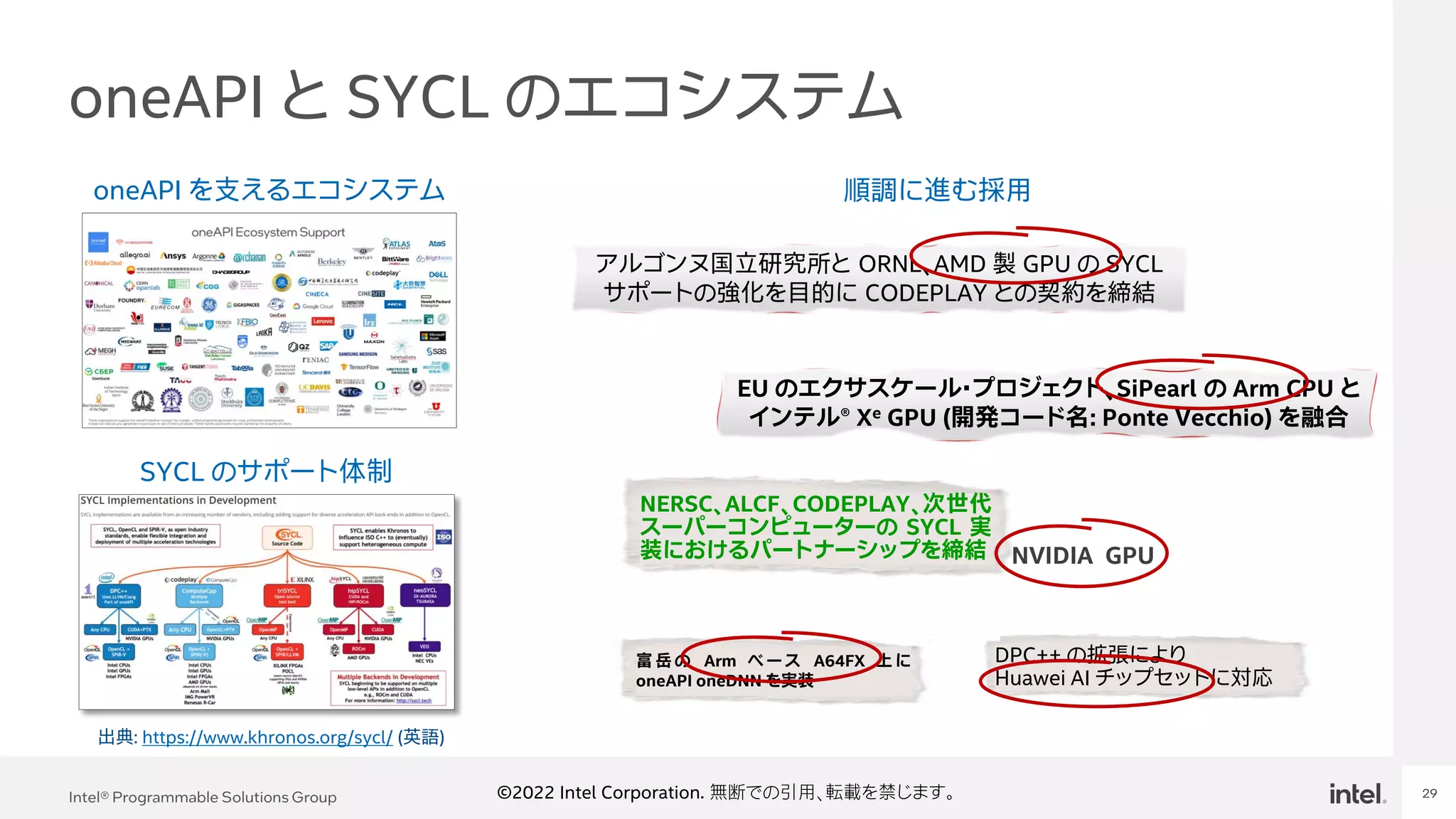
Event Name 29 Intel® Programmable Solutions Group 29 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI と SYCL のエコシステム 出典: https://www.khronos.org/sycl/ (英語) oneAPI を支えるエコシステム SYCL のサポート体制 アルゴンヌ国立研究所と ORNL、AMD 製 GPU の SYCL サポートの強化を目的に CODEPLAY との契約を締結 EU のエクサスケール・プロジェクト、SiPearl の Arm CPU と インテル® Xe GPU (開発コード名: Ponte Vecchio) を融合 順調に進む採用 富 岳 の Arm ベ ース A64FX 上 に oneAPI oneDNN を実装 NERSC、ALCF、CODEPLAY、次世代 スーパーコンピューターの SYCL 実 装におけるパートナーシップを締結 NVIDIA GPU DPC++ の拡張により Huawei AI チップセットに対応
29.
oneAPI FPGA 開発フロー SYCL
+ oneAPI
30.
Intel Confidential Department or
Event Name 31 Intel® Programmable Solutions Group 31 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI FPGA 開発フロー ▪ FPGA エミュレーション • FPGA を CPU 上で正確にエミュレーション • アルゴリズムを数秒で検証 ▪ ハードウェア(RTL)とレポートを生成 • 数分以内に、ハードウェア・モデルを正確なサイクルの 性能レポートとともに作成 ▪ FPGA 上にハードウェアを実装 • このステップは数時間で完了 • 性能要件に達している場合にこのステップを実行 • 正確なサイクルの出力結果 • 完了タイミングを予測し、前回との差を +/-10% の範囲で推定 FPGA 開発フロー コード記述 エミュレーション 静的レポート 全体コンパイル デプロイ 数秒 数分 数時間
31.
Intel Confidential Department or
Event Name 32 Intel® Programmable Solutions Group 32 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 エミュレーション ▪ CPU でのコンパイルとエミュレーションを介して機能を検証 • シンタックスとポインターの実装エラーを素早く特定 • FPGA 拡張機能を使用した SYCL コードの機能デバッグ • FPGA の機能が検証される ▪ 業界標準の IDE • Microsoft Visual Studio に対応 • VS Codeに対応 • Eclipse に対応 • インテル® ディストリビューションの GDB によるデバッグ ▪ 生産性の高い開発環境を実現 短期間での開発と検証 FPGA 開発フロー コード記述 エミュレーション 静的レポート 全体コンパイル デプロイ 数秒 数分 数時間
32.
Intel Confidential Department or
Event Name 33 Intel® Programmable Solutions Group 33 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 ハードウェアの詳細なレポート出力: ▪ メモリー、性能、データフローのボトルネックを特定 ▪ エリアとタイミングの見積もり ▪ ボトルネックを解消するための最適化手法の提案 • エリア/リソース使用率、ループ構成、システムのデータフロー • メモリー使用率、タイミング見積もり レポート出力 データフロー & 制御フロー デザインのサマリー 進捗のグラフ表示 FPGA 開発フロー コード記述 エミュレーション 静的レポート 全体コンパイル デプロイ 数秒 数分 数時間
33.
Intel Confidential Department or
Event Name 34 Intel® Programmable Solutions Group 34 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 FPGA ビットストリームのコンパイル • ハードウェア・モデルを FPGA ハードウェアにマッピング • 自動化されたタイミング・クロージャー • ハードウェアでの検証が可能 ▪ FPGA 上で実行 ▪ デザインのリアルタイム分析にインテル® VTune™ プロファイラーを活用 ビットストリームのコンパイル インテル® Quartus® Prime 開発ソフトウェアのインストールが必要 FPGA 開発フロー コード記述 エミュレーション 静的レポート 全体コンパイル デプロイ 数秒 数分 数時間
34.
Intel Confidential Department or
Event Name 35 Intel® Programmable Solutions Group 35 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 インテル® VTune™ プロファイラー ランタイム分析 開発者がアクセスできるメリットは以下: データ並列 C++ (DPC++) の分析 ▪ 開発時間の大部分を占める DPC++ コードの確認 インテルの CPU、GPU、FPGA に合わせてチューニング ▪ すべての対応ハードウェア・アクセラレーターに最適化 ▪ ソースビュー形式とタイムラインフォーマットの両方でメモリーとパイプへの アクセスに関する統計データの詳細を表示 オフロードの最適化 ▪ CPU/FPGA のインタラクション・ビューをパフォーマンス情報の確認に活用 ▪ ホストとデバイス両方のイベントを含めたカーネルプログラム実行プロセスの 全体をグラフ表示で確認 幅広いパフォーマンス・プロファイル ▪ CPU、GPU、FPGA、スレッディング、メモリー、キャッシュ、ストレージ…
35.
Intel Confidential Department or
Event Name 36 Intel® Programmable Solutions Group 36 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 FPGA 開発フロー ▪ SYCL/DPC++ で開発 • ヘテロジニアス・コンピューティングのための、最先端かつ業界全体で共通 の言語 • 業界標準の C++17 ベース ▪ 3 段階の手法 • エミュレーション • アルゴリズムを迅速に反復して検証 • レポートの生成 • ハードウェアの推定性能を確認、実装をリファイン・最適化 • パフォーマンスの目標値を満たしているか確認 • フルコンパイル • FPGA ハードウェアの実装 • このステップには時間を要するため、パフォーマンスの目標値が確実に満たされて から実行 FPGA 開発フロー コード記述 エミュレーション 静的レポート 全体コンパイル デプロイ 数秒 数分 数時間
36.
Intel Confidential Department or
Event Name 37 37 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 OpenCL AFU shim のポーティング • インテル® OFS をサポートするプラットフォーム上で OpenCL カーネル と oneAPI カーネルをコンパイルして実行するには、 OpenCL AFU shim が必要 • OpenCL AFU shim は、プラットフォーム・デザイナー IP とビルド スクリプトの集合 • IP 内と XML ファイル内のメモリーバンク数に応じて調整が必要 になる場合もあり
37.
Intel® Programmable Solutions
Group 38 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 参考)I/O Pipes サンプルカーネルコード#1 ▪ パケット受信カーネル例 • read_iopipe関数を使用 • UDPパケットのペイロードをストリーム状に読み出す q_recv.submit([&](handler& h) { auto a = obuf_a.get_access<access::mode::discard_write>(h); auto b = obuf_b.get_access<access::mode::discard_write>(h); h.single_task<class udp_recv>([=]() [[intel::kernel_args_restrict]] { ch_udp buf; uint ptr = 0; while(1) { buf = read_iopipe::read(); uint valid_cnt = 32 - (buf.sop_eop & EMPTY_MASK); #pragma unroll 32 for(int i = 0; i < 32; i++) // for(int i = 0; i < valid_cnt; i++) a[ptr + i] = buf.dat[i]; ptr += valid_cnt; if (buf.sop_eop & ENDOFPACKET) break; } b[0] = ptr; }); }); typedef struct { uchar dat[32]; // in order to lower the Fmax, the bus width is doubled. uchar sop_eop; // [6]: start of packet [5]: end of packet [4:0] empty signal of AVST } ch_udp;
38.
Intel® Programmable Solutions
Group 39 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 参考)I/O Pipes サンプルカーネルコード#2 ▪ パケット送信カーネル例 • write_iopipe関数を使用 • UDPパケットのペイロードをストリーム状に書き出す q_send.submit([&](handler& h) { auto a = ibuf_b.get_access<access::mode::read>(h); size_t size = datasize; h.single_task<class udp_send>([=]() [[intel::kernel_args_restrict]] { for(int i = 0; i < size; i+=32) { ch_udp tmp; #pragma unroll 32 for(int j = 0; j < 32; j++) tmp.dat[j] = a[i+j]; bool is_last = ((size - i) <= 32); uchar empty = is_last ? (size - i): 0; if (i == 0) tmp.sop_eop = STARTOFPACKET; // empty == 0 else if (is_last) tmp.sop_eop = ENDOFPACKET | (empty & EMPTY_MASK); else tmp.sop_eop = 0; write_iopipe::write(tmp); } }); });
39.
開発リソース 多くの学習手段
40.
Intel Confidential Department or
Event Name 41 Intel® Programmable Solutions Group 41 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 SYCL/DPC++ Book ▪ SYCL と DPC++ 言語の網羅的な解説 ▪ 主要アクセラレーター・アーキテクチャーとして FPGA 全 体に焦点 ▪ 著者である Michael Kinsner は PSG oneAPI チームのメンバーの 1 人 ▪ 製品のスペック自体よりも、わかりやすさ優先で記述 ▪ 無償ダウンロード link.springer.com/book/10.1007%2F978-1-4842-5574-2 (英語)
41.
Intel Confidential Department or
Event Name 42 Intel® Programmable Solutions Group 42 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 インテル® oneAPI DPC++ コンパイラ-の仕様 インテル® oneAPI DPC++ FPGA 最適化ガイド インテル® oneAPI プログラミング・ガイド https://software.intel.com/content/www/us/en/develop/documen tation/oneapi-fpga-optimization-guide/top.html (英語) https://software.intel.com/content/www/us/en/develop/documentati on/oneapi-programming-guide/top.html (英語) https://jp.xlsoft.com/documents/intel/oneapi/download/programmin g-guide.pdf (日本語)
42.
Intel Confidential Department or
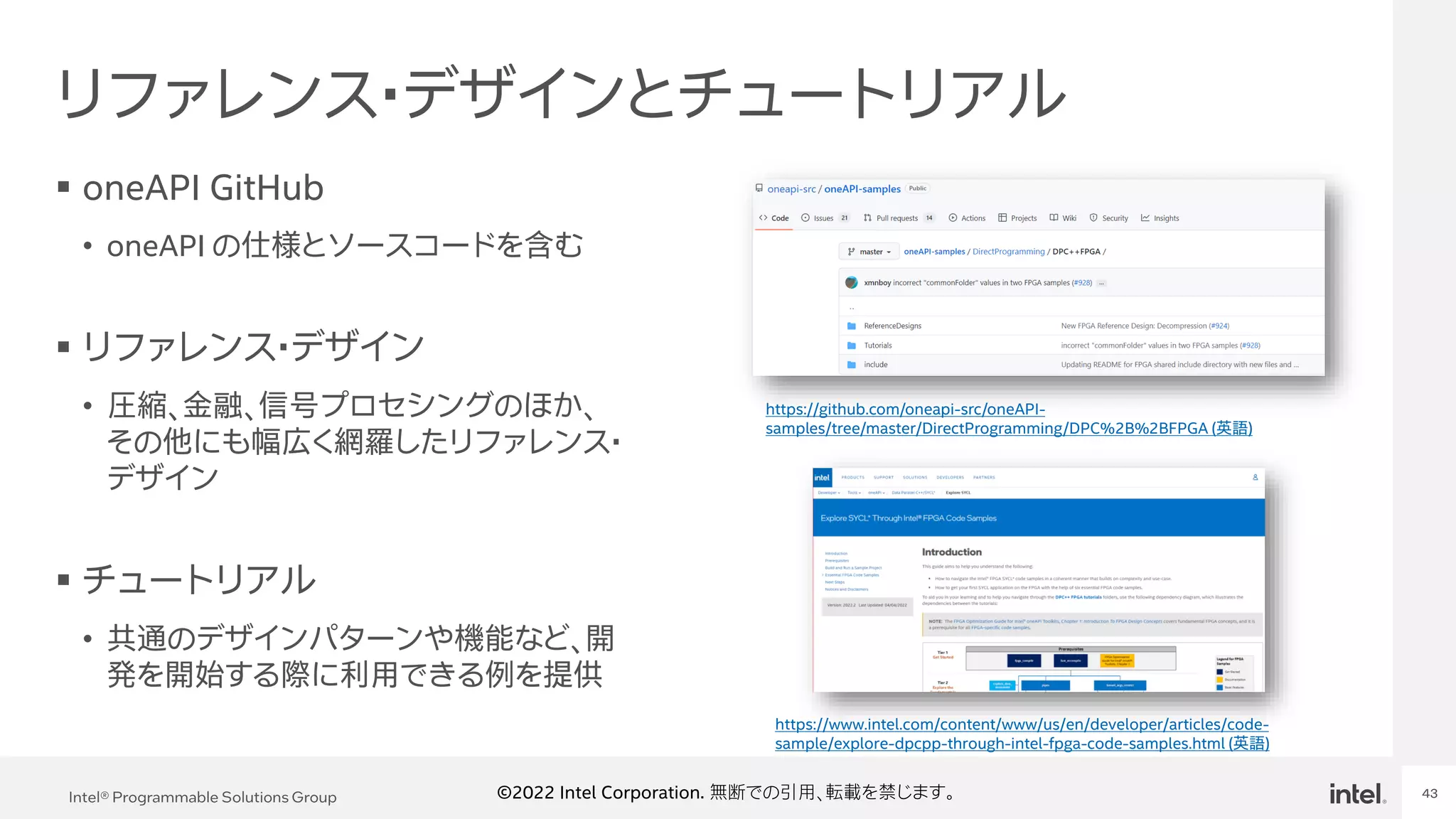
Event Name 43 Intel® Programmable Solutions Group 43 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 リファレンス・デザインとチュートリアル ▪ oneAPI GitHub • oneAPI の仕様とソースコードを含む ▪ リファレンス・デザイン • 圧縮、金融、信号プロセシングのほか、 その他にも幅広く網羅したリファレンス・ デザイン ▪ チュートリアル • 共通のデザインパターンや機能など、開 発を開始する際に利用できる例を提供 https://github.com/oneapi-src/oneAPI- samples/tree/master/DirectProgramming/DPC%2B%2BFPGA (英語) https://www.intel.com/content/www/us/en/developer/articles/code- sample/explore-dpcpp-through-intel-fpga-code-samples.html (英語)
43.
Intel Confidential Department or
Event Name 44 Intel® Programmable Solutions Group 44 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 Agilexでのリファレンス・デザインコンパイル例 ▪ Terasic社DE10-Agilexボード用に以下の リファレンス・デザインをコンパイル • https://github.com/oneapi-src/oneAPI- samples/tree/master/DirectProgramming/DPC%2 B%2BFPGA/ReferenceDesigns • Seedは振らず、1回のみのコンパイルによる結果 • 搭載FPGAはAGF014(Core Speed -2V)シリーズ • ALM: 487,200 • RAM block: 7,110 • DSP block: 4,510 リファレンス・デザイン名 Kernel Fmax ALM使用数 M20K使用数 DSP使用数 Adaptive Noise Reduction (anr) 550.35MHz 99,946 743 31 CRR Binomial Tree Model for Option Pricing (crr) 502.51MHz 428,613 2,863 1,280 Database Query Acceleration (db) 531.34MHz 245,081 1,238 120 GZIP Compression (gzip) 526.31MHz 279,238 4,002 0 Merge Sort (merge_sort) 243.19MHz 249,381 1,245 0 MVDR Beamforming (mvdr_beamforming) 406.0MHz 166,815 1,187 615 QR Decomposition of Matrices (qrd) 525.21MHz 239,409 2,854 2,083
44.
Intel Confidential Department or
Event Name 45 45 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 oneAPI FPGA IP開発フロー
45.
Intel Confidential Department or
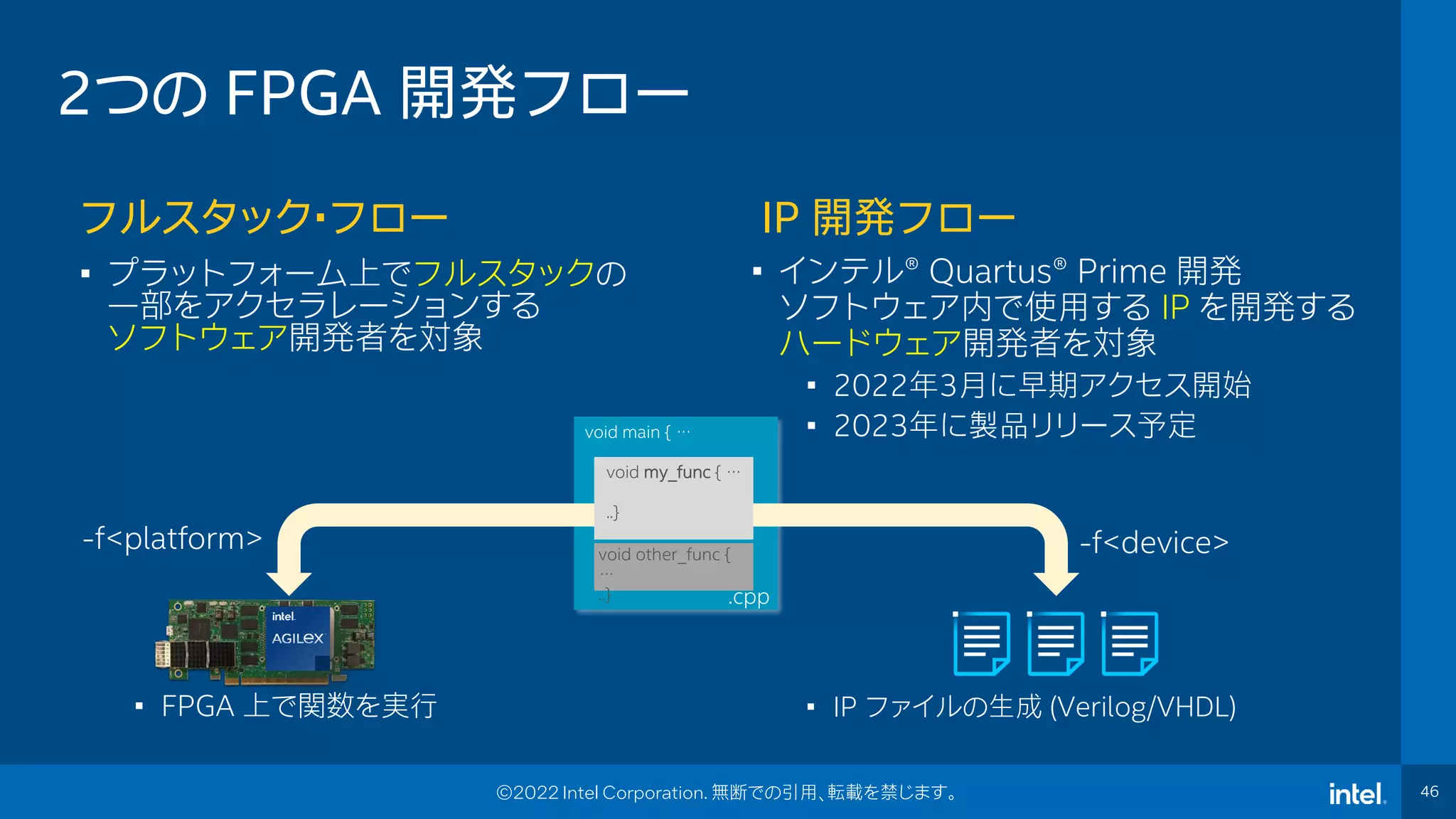
Event Name 46 46 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 2つの FPGA 開発フロー フルスタック・フロー IP 開発フロー void main { … .cpp void my_func { … ..} void other_func { … ..} • インテル®️ Quartus®️ Prime 開発 ソフトウェア内で使用する IP を開発する ハードウェア開発者を対象 • 2022年3月に早期アクセス開始 • 2023年に製品リリース予定 • IP ファイルの生成 (Verilog/VHDL) • プラットフォーム上でフルスタックの 一部をアクセラレーションする ソフトウェア開発者を対象 • FPGA 上で関数を実行 -f<platform> -f<device>
46.
Intel Confidential Department or
Event Name 47 47 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 生成 • 生産性の高いハードウェア生成 • 新規デザインを数分で生成 • スループットに対して自動的に最適化 • RTLを自動生成 • Verilog、VHDL • I/O インターフェイスの指定 • レポートと解析ビューのレビュー • エリアとタイミング見積もりをレビュー • 詳細なシステムビュー • メモリー、パフォーマンスのボトルネックの推定 • ボトルネック解消のための最適化方法に関する 推奨内容をレビュー
47.
Intel Confidential Department or
Event Name 48 48 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 検証 • プッシュボタン検証 • RTL テストベンチの自動生成 • ソフトウェアから抽出されたテストベクタ • 出力結果の比較と検証 • 詳細な解析 • オプションで RTL 波形および解析を表示
48.
時間があれば インテル® FPGA IPUの概要
49.
Intel Confidential Department or
Event Name 50 50 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 200G FPGA + インテル・アーキテクチャー インテル®️ FPGA IPU プラットフォーム 50G FPGA + インテル・アーキテクチャー ハイパフォーマンス FPGAベースのクラウド・インフラストラクチャー・ アクセラレーション・プラットフォーム インテルの第2世代 FPGAベース IPU プラットフォーム • ワークロードとストレージ機能のネットワーク仮想化機能オフロード Ex: OvS, NVMe over fabric, RoCE v2 • インテル®️ オープン FPGA スタック • x86に最適化された DPDK と SPDK によるプログラミング • ハードエンドの暗号化ブロックを持つ高速な 2x 100GE インターフェイス • VirtIO をハードウェアでサポートし、Linux のネイティブサポートを実現 インテル® IPU プラットフォーム F2000X-PL • ワークロードとストレージ機能のネットワーク仮想化機能オフロード Ex: OvS, NVMe over fabric, RoCE v2 • x86に最適化された DPDK and SPDK によるプログラミング • 2x 25GE インターフェイス • VirtIO をハードウェアでサポートし、Linux のネイティブサポートを実現 • 量産可能なソリューションを ODMパートナー様から提供 インテル® FPGA IPU プラットフォーム C5000X-PL
50.
Intel Confidential Department or
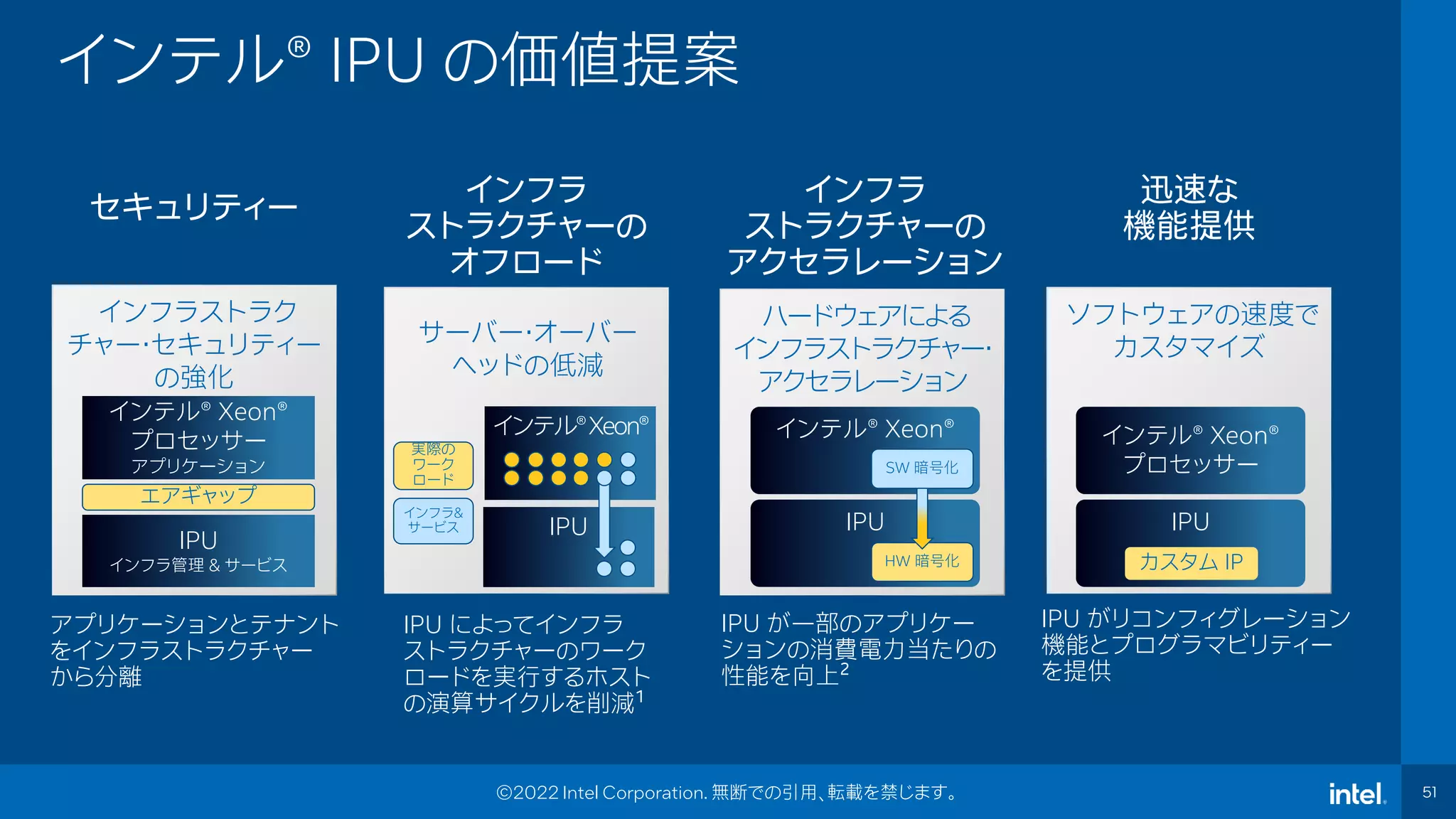
Event Name 51 51 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 インフラ ストラクチャーの オフロード インテル®️Xeon®️ 実際の ワーク ロード インフラ& サービス IPU によってインフラ ストラクチャーのワーク ロードを実行するホスト の演算サイクルを削減1 ハードウェアによる インフラストラクチャー・ アクセラレーション IPU が一部のアプリケー ションの消費電力当たりの 性能を向上2 ソフトウェアの速度で カスタマイズ 迅速な 機能提供 IPU がリコンフィグレーション 機能とプログラマビリティー を提供 インフラ ストラクチャーの アクセラレーション インテル®️ Xeon®️ プロセッサー IPU カスタム IP インテル®️ Xeon®️ IPU HW 暗号化 SW 暗号化 サーバー・オーバー ヘッドの低減 IPU インフラストラク チャー・セキュリティー の強化 セキュリティー アプリケーションとテナント をインフラストラクチャー から分離 インテル®️ Xeon®️ プロセッサー アプリケーション IPU インフラ管理 & サービス エアギャップ インテル®️ IPU の価値提案
51.
Intel Confidential Department or
Event Name 52 52 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 バージョン: 2022年第 3 四半期 オープンなコミュニティー オープンな ソフトウェア・ エコシステム エコシステムの主導と拡大により、幅広い採用を促進 クラウド、通信、 エンタープライズなど 幅広い分野と領域で 導入 リーダーシップ・ ポートフォリオ 2025年以降 2023年~2024年 第 2 世代 第 3 世代 第 4 世代 プラットフォーム 開発コード名: Hot Springs Canyon ASIC 開発コード名: Mount Morgan プラットフォーム 次世代 ASIC 次世代 現時点の リーダーシップ製品 発表済み 次世代 2022年 200G 400G 800G ASIC E2000 プラットフォーム F2000X-PL インテル®️ IPU のロードマップ
52.
Intel Confidential Department or
Event Name 53 53 ©2022 Intel Corporation. 無断での引用、転載を禁じます。 IPUの利用方法の拡張 ホスト 仮想 スイッチ ストレージ 管理、 セキュリ ティー、監視 カーネル / ハイパーバイザー アプリ / VM アプリ / VM アプリ / VM アプリ / VM ネットワークの高速化 • 帯域幅の拡大 • レイテンシーの低減 • パフォーマンス変動を低減 ホスト 仮想 スイッチ ストレージ 管理、 セキュリ ティー、監視 カーネル / ハイパーバイザー アプリ / VM アプリ / VM アプリ / VM アプリ / VM ストレージの高速化 • ブロックストレージ容量の増加 • レイテンシーの低減 • パフォーマンス変動を低減 ホスト 仮想 スイッチ ストレージ 管理、 セキュリ ティー、監視 カーネル / ハイパーバイザー アプリ / VM アプリ / VM アプリ / VM アプリ / VM 管理とセキュリティーの負荷軽減 • ほぼ 100% の演算リソースを 利用可能 • セキュリティーの強化 仮想 スイッチ ストレージ 管理、 セキュリ ティー、監視 インフラストラクチャー・サービス ホスト カーネル アプリ / VM アプリ / VM アプリ / VM アプリ / VM インフラストラクチャーの処理 • ベアメタルのサービス • IPU でのセキュリティー IPU IPU IPU IPU * 絶対的なセキュリティーを提供できる製品やコンポーネントはありません。
53.
54
Download








![Intel Confidential
Department or Event Name 15
15
©2022 Intel Corporation. 無断での引用、転載を禁じます。
▪ 新しいインテル® Agilex™ FPGA (開発コード名: Sundance Mesa) の INT8 性能
は最大 26TOPS
▪ エッジ AI アプリケーションに最適な、AI Tensor ブロックを搭載した新しい
FPGA シリーズ
▪ インテル® FPGA AI スイートでサポート
▪ インテル® FPGA AI スイートは業界標準フレームワークから FPGA ビットスト
リームまでのワンクリック・フローを実現 [例: Caffe、PyTorch、TensorFlow]
AI Tensor ブロックを搭載した初のエッジセントリック FPGA
デバイス 最大 INT8 TOPS
新しいインテル® Agilex™
FPGA での向上
Cyclone® V FPGA 1 26 倍
インテル® Arria® 10 FPGA 13 2 倍
インテル® Stratix® 10 FPGA
(2.8M)
23 1.1 倍
SUNDANCE MESA
AI Tensor ブロック
2- 18X19 MAC
1 INT16 CMULT
20 INT8 OPS](https://image.slidesharecdn.com/intel2022121420221212-221216034102-0b2f053f/75/11-ACRi-_-14-2048.jpg)


















 {
auto a = obuf_a.get_access<access::mode::discard_write>(h);
auto b = obuf_b.get_access<access::mode::discard_write>(h);
h.single_task<class udp_recv>([=]() [[intel::kernel_args_restrict]] {
ch_udp buf;
uint ptr = 0;
while(1) {
buf = read_iopipe::read();
uint valid_cnt = 32 - (buf.sop_eop & EMPTY_MASK);
#pragma unroll 32
for(int i = 0; i < 32; i++)
// for(int i = 0; i < valid_cnt; i++)
a[ptr + i] = buf.dat[i];
ptr += valid_cnt;
if (buf.sop_eop & ENDOFPACKET) break;
}
b[0] = ptr;
});
});
typedef struct {
uchar dat[32]; // in order to lower the Fmax, the bus width is doubled.
uchar sop_eop; // [6]: start of packet [5]: end of packet [4:0] empty signal of AVST
} ch_udp;](https://image.slidesharecdn.com/intel2022121420221212-221216034102-0b2f053f/75/11-ACRi-_-37-2048.jpg)
 {
auto a = ibuf_b.get_access<access::mode::read>(h);
size_t size = datasize;
h.single_task<class udp_send>([=]() [[intel::kernel_args_restrict]] {
for(int i = 0; i < size; i+=32) {
ch_udp tmp;
#pragma unroll 32
for(int j = 0; j < 32; j++)
tmp.dat[j] = a[i+j];
bool is_last = ((size - i) <= 32);
uchar empty = is_last ? (size - i): 0;
if (i == 0)
tmp.sop_eop = STARTOFPACKET; // empty == 0
else if (is_last)
tmp.sop_eop = ENDOFPACKET | (empty & EMPTY_MASK);
else
tmp.sop_eop = 0;
write_iopipe::write(tmp);
}
});
});](https://image.slidesharecdn.com/intel2022121420221212-221216034102-0b2f053f/75/11-ACRi-_-38-2048.jpg)