Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
YD
Uploaded by
yukihiro domae
PPTX, PDF
2,856 views
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
論文「Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition」を読んでみました
Science
◦
Related topics:
Computer Vision Insights
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 23 times
1
/ 27
2
/ 27
Most read
3
/ 27
Most read
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
Most read
More Related Content
PDF
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
PDF
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
PDF
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PDF
動画像理解のための深層学習アプローチ
by
Toru Tamaki
PDF
動画像理解のための深層学習アプローチ Deep learning approaches to video understanding
by
Toru Tamaki
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
PDF
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
High-impact Papers in Computer Vision: 歴史を変えた/トレンドを創る論文
by
cvpaper. challenge
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
動画像理解のための深層学習アプローチ
by
Toru Tamaki
動画像理解のための深層学習アプローチ Deep learning approaches to video understanding
by
Toru Tamaki
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
What's hot
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
最適輸送入門
by
joisino
PPTX
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
Deep Learningによる超解像の進歩
by
Hiroto Honda
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
【論文紹介】 Spatial Temporal Graph Convolutional Networks for Skeleton-Based Acti...
by
ddnpaa
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PDF
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
最適輸送入門
by
joisino
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
【メタサーベイ】Neural Fields
by
cvpaper. challenge
近年のHierarchical Vision Transformer
by
Yusuke Uchida
【メタサーベイ】Video Transformer
by
cvpaper. challenge
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
Deep Learningによる超解像の進歩
by
Hiroto Honda
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
【論文紹介】 Spatial Temporal Graph Convolutional Networks for Skeleton-Based Acti...
by
ddnpaa
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
強化学習 DQNからPPOまで
by
harmonylab
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
モデルアーキテクチャ観点からのDeep Neural Network高速化
by
Yusuke Uchida
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
Similar to Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
PPTX
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
点群深層学習 Meta-study
by
Naoya Chiba
PPTX
Graph Neural Networks
by
tm1966
PPTX
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
PDF
大規模凸最適化問題に対する勾配法
by
京都大学大学院情報学研究科数理工学専攻
PDF
大規模ネットワークの性質と先端グラフアルゴリズム
by
Takuya Akiba
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
by
KokiTakamiya
PDF
CV勉強会@関東 3巻3章4節 画像表現
by
Yusuke Uchida
PDF
線形回帰と階層的クラスタリングの実装
by
Yuya Takashina
PDF
NIPS2013読み会: Scalable kernels for graphs with continuous attributes
by
Yasuo Tabei
PDF
第2回プログラマのための数学LT会
by
春 根上
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
Graph nuralnetwork@2021
by
embedded samurai
PPTX
FeaStNet: Feature-Steered Graph Convolutions for 3D Shape Analysis
by
yukihiro domae
DOCX
深層学習 Day1レポート
by
taishimotoda
PDF
CMSI計算科学技術特論A (2015) 第11回 行列計算における高速アルゴリズム2
by
Computational Materials Science Initiative
PDF
Taking a Deeper Look at the Inverse Compositional Algorithm
by
Mai Nishimura
PPTX
Graph conv
by
TakuyaKobayashi12
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
グラフニューラルネットワーク入門
by
ryosuke-kojima
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
点群深層学習 Meta-study
by
Naoya Chiba
Graph Neural Networks
by
tm1966
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
大規模凸最適化問題に対する勾配法
by
京都大学大学院情報学研究科数理工学専攻
大規模ネットワークの性質と先端グラフアルゴリズム
by
Takuya Akiba
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
by
KokiTakamiya
CV勉強会@関東 3巻3章4節 画像表現
by
Yusuke Uchida
線形回帰と階層的クラスタリングの実装
by
Yuya Takashina
NIPS2013読み会: Scalable kernels for graphs with continuous attributes
by
Yasuo Tabei
第2回プログラマのための数学LT会
by
春 根上
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
Graph nuralnetwork@2021
by
embedded samurai
FeaStNet: Feature-Steered Graph Convolutions for 3D Shape Analysis
by
yukihiro domae
深層学習 Day1レポート
by
taishimotoda
CMSI計算科学技術特論A (2015) 第11回 行列計算における高速アルゴリズム2
by
Computational Materials Science Initiative
Taking a Deeper Look at the Inverse Compositional Algorithm
by
Mai Nishimura
Graph conv
by
TakuyaKobayashi12
More from yukihiro domae
PPTX
Graph LSTM解説
by
yukihiro domae
PPTX
Superpixel Sampling Networks
by
yukihiro domae
PPTX
Texture-Aware Superpixel Segmentation
by
yukihiro domae
PPTX
Learning Depthwise Separable Graph Convolution from Data Manifold
by
yukihiro domae
PPTX
Graph U-Net
by
yukihiro domae
PDF
Dynamic Routing Between Capsules
by
yukihiro domae
PPTX
Graph Refinement based Tree Extraction using Mean-Field Networks and Graph Ne...
by
yukihiro domae
Graph LSTM解説
by
yukihiro domae
Superpixel Sampling Networks
by
yukihiro domae
Texture-Aware Superpixel Segmentation
by
yukihiro domae
Learning Depthwise Separable Graph Convolution from Data Manifold
by
yukihiro domae
Graph U-Net
by
yukihiro domae
Dynamic Routing Between Capsules
by
yukihiro domae
Graph Refinement based Tree Extraction using Mean-Field Networks and Graph Ne...
by
yukihiro domae
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
1.
Spatial Temporal Graph Convolutional
Networks for Skeleton-Based Action Recognition
2.
概要 • Spatial Temporal
Graph Convolutional Networks(ST-GCN)と呼ばれる 動的スケルトンの新しいモデルを提案 • データから空間パターンと時間パターンの両方を自動的に学習 • 空間時間グラフの畳み込みを行う複数の層が構築 ➡ 空間次元と時間次元の両方に沿って情報を統合することができる • ST-GCNは,スケルトンベースのアクション認識のタスクにGCNを初めて適用
3.
ST-GCNの全体の処理の簡単な流れ • 入力データに対して,空間時間グラフ畳み込み演算の複数回適用され、 グラフ上に高次の特徴マップが生成される。 • その特徴マップから,SoftMax分類器によって対応するアクションカテゴリに分類 •
backpropagationによって訓練される
4.
グラフの定義 • ノード :(X,Y,C) •
(X,Y) :ピクセル座標系の2次元座標 • C :18個の人間の関節の信頼スコア • エッジ :人体構造と時間における連結
5.
Convolutionの計算 • 𝑓𝑖𝑛(𝑣 𝑡𝑗)
:入力特徴マップのノード𝑣 𝑡𝑗の特徴ベクトル(座標と関節の信頼スコア) • 𝑙 𝑡𝑖(𝑣 𝑡𝑗) :空間的ノード𝑣 𝑡𝑗に対して該当するカーネルのインデックス番号(0~K-1) • 𝑙 𝑆𝑇(𝑣 𝑞𝑗) :𝑙 𝑡𝑖 𝑣 𝑡𝑗 の後に時間的な割り当てを追加 𝑙 𝑆𝑇(𝑣 𝑞𝑗) = 𝑙 𝑡𝑖 𝑣 𝑡𝑗 + (𝑞 − 𝑡 + Γ 2 ) × 𝐾 • 𝑤(𝑙 𝑡𝑖(𝑣 𝑡𝑗)) :ンデックス番号に合わせて重みを出力する関数 • 𝐵(𝑣 𝑡𝑖) :注目ノードに対する隣接ノードの集合 𝐵 𝑣 𝑡𝑖 = {𝑣 𝑡𝑗|𝑑(𝑣 𝑡𝑗, 𝑣 𝑡𝑖) ≤ K , |𝑞 − 𝑡| ≤ Γ 2 } • Γ :時間的カーネルサイズ • K :空間的カーネルサイズ • 𝑍𝑡𝑖(𝑣 𝑡𝑗) :正規化項(重みのインデックスが同じものどうしで行う) 𝑍𝑡𝑖 𝑣 𝑡𝑗 = | 𝑣 𝑡𝑘 | 𝑙 𝑡𝑖 𝑣 𝑡𝑘 = 𝑙 𝑡𝑖 𝑣 𝑡𝑗 | 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗)) 𝑡 :注目時刻 𝑖 :注目ノード 𝑞 :隣接時刻 𝑗 :隣接ノード
6.
Spatial Temporal Graph
Convolutional Networks for Skeleton-Based Action Recognition • 𝑙 𝑡𝑖(𝑣 𝑡𝑗) :ノード𝑣 𝑡𝑗に対して該当するカーネルのインデックス番号(0~K-1) ➡ つまり𝑤(𝑙 𝑡𝑖(𝑣 𝑡𝑗))はインデックス番号が𝑙 𝑡𝑖(𝑣 𝑡𝑗)の重みを取り出す どうやってインデックス番号を割り当てられているのか • いくつか方法がある • (B)すべて同じ重み(K=1) • (C)エッジの距離が0(緑)か1(青)かで分ける(K=2) • (D)スケルトン全体の重心に対して,注目ノードより距離が短いものと長いもので分ける 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑡𝑖(𝑣 𝑡𝑗))
7.
Spatial Temporal Graph
Convolutional Networks for Skeleton-Based Action Recognition 学習可能なエッジ重み • 人がアクションを実行しているとき,隣接する関節ノードが連動する • 連動に関係のあるノードとないノードがある • 連動しているノード間のエッジに重要度に合わせて重みづけをする
8.
Spatial Temporal Graph
Convolutional Networks for Skeleton-Based Action Recognition • ST-GCNの実装(スペクトルアプローチで行う) (B)の割り当ての場合 • 𝒇 𝒐𝒖𝒕 = 𝜦− 𝟏 𝟐(𝑨 + 𝑰) ⊗ 𝑴𝜦− 𝟏 𝟐 𝒇𝒊𝒏 𝑾 • 𝛬𝑖𝑖 = 𝑗(𝛬𝑖𝑗 + 𝐼 𝑖𝑗) • 𝑨 :隣接行列 • 𝑰 :単位行列 (C)(D)の割り当ての場合 • 𝒇 𝒐𝒖𝒕 = 𝑗 𝜦𝑗 − 𝟏 𝟐 𝑨𝑗 ⊗ 𝑴𝜦𝑗 − 𝟏 𝟐 𝒇𝒊𝒏 𝑾𝑗 • 𝛬𝑗 𝑖𝑖 = 𝑘(𝛬𝑗 𝑖𝑘 ) + 𝛼 • 𝑨𝑗の空の行を避けるために,α= 0.001を設定 • ⊗は要素積
10.
Convolutionの計算 • 注目ノード:𝑣 𝑡𝑖 •
𝑡:注目時刻 • 𝑖:注目位置 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗))
11.
Convolutionの計算 • 注目ノード:𝑣 𝑡𝑖 •
𝑡:注目時刻 • 𝑖:注目位置 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗)) 隣接ノードの求めかた • 隣接ノードの集合:𝐵(𝑣 𝑡𝑖) • 𝐵 𝑣 𝑡𝑖 = {𝑣 𝑡𝑗|𝑑(𝑣 𝑡𝑗, 𝑣 𝑡𝑖) ≤ 𝐾 , |𝑞 − 𝑡| ≤ 𝛤 2 } • 𝑑 𝑣 𝑡𝑗, 𝑣 𝑡𝑖 ≤ 𝐾 (注目ノード𝑣 𝑡𝑖と隣接ノード𝑣 𝑡𝑗の距離がK以下) • |𝑞 − 𝑡| ≤ 𝛤 2 (現在の時刻tと時間隣接ノードの時刻qの差が 𝛤 2 以下) • 𝐾と𝛤はカーネルの最大サイズ • 最も短いエッジの距離
12.
隣接ノードの求めかた • 隣接ノードの集合:𝐵(𝑣 𝑡𝑖) •
𝐵 𝑣 𝑡𝑖 = {𝑣 𝑡𝑗|𝑑(𝑣 𝑡𝑗, 𝑣 𝑡𝑖) ≤ 𝐾 , |𝑞 − 𝑡| ≤ 𝛤 2 } • 𝑑 𝑣 𝑡𝑗, 𝑣 𝑡𝑖 ≤ 𝐾 (注目ノード𝑣 𝑡𝑖と隣接ノード𝑣 𝑡𝑗の距離がK以下) • |𝑞 − 𝑡| ≤ 𝛤 2 (現在の時刻𝑡と時間隣接ノードの時刻𝑞の差が 𝛤 2 以下) • 𝐾と𝛤はカーネルの最大サイズ • 2つのノードの最短のエッジの距離 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗)) 𝛤 2 𝛤 2 K
13.
重み割り当て • 重み割り当て関数によって与えられたインデックスによって,重みが与えられる • 割り当ての決定方法 •
(B)すべて同じ重み(K=1) • (C)エッジの距離が0(緑)か1(青)かで分ける(K=2) • (D)スケルトン全体の重心に対して,注目ノードより距離が短いものと長いもので分ける 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗))
14.
重み割り当ての式 𝑙 𝑆𝑇(𝑣 𝑞𝑗)
= 𝑙 𝑡𝑖 𝑣 𝑡𝑗 + (𝑞 − 𝑡 + 𝛤 2 ) × 𝐾 • 𝑙 𝑡𝑖 𝑣𝑡𝑗 は単一フレームの場合のラベルマップ • 前ページの割り当ての決定方法がここに当たる • 𝑙 𝑡𝑖 𝑣 𝑡𝑗 が0~𝐾 − 1までとすると, 𝑞 = 𝑡以外の時は𝐾以降の重みを参照 • 以下のように重みが入っていることになる • [注目ノードと同じフレームの重み][𝑞 = 𝑡以外の時は𝐾以降の重み] 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗))
15.
重み・正規化項 重み 𝑤 𝑙 𝑆𝑇
𝑣 𝑡𝑗 • インデックス番号に合わせて重みを出力する関数 正規化項 𝑍𝑡𝑖(𝑣 𝑡𝑗) • 重みのインデックスが同じものどうしで行う 𝑍𝑡𝑖 𝑣 𝑡𝑗 = | 𝑣 𝑡𝑘 | 𝑙 𝑡𝑖 𝑣 𝑡𝑘 = 𝑙 𝑡𝑖 𝑣 𝑡𝑗 | • 結局,隣接ノード数で割ることと同じ 𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) = 𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖) 1 𝑍𝑡𝑖 𝑣 𝑡𝑗 𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗))
16.
学習可能なエッジ重み • 人がアクションを実行しているとき,隣接する関節ノードが連動する • 連動に関係のあるノードとないノードがある •
連動しているノード間のエッジに重要度に合わせて重みづけをする • マスクは,その注目ノード対する隣接ノード特徴の寄与度をスケーリングする • このマスクを追加することにより、ST-GCNの認識性能をさらに向上させることができることを経 験的に見出した
17.
(B)の割り当ての場合(重みがすべて同じ場合) • 𝒇 𝒐𝒖𝒕
= 𝜦− 𝟏 𝟐(𝑨 + 𝑰)𝜦− 𝟏 𝟐 𝒇𝒊𝒏 𝑾 • 𝑨 :隣接行列 • 𝑰 :単位行列 • 𝛬𝑖𝑖 = 𝑗(𝛬𝑖𝑗 + 𝐼 𝑖𝑗) 行列𝛬のインデックスiiがそろってる部分は実数値、その他は0(次数行列)
18.
(C)(D)の割り当ての場合 • 𝒇 𝒐𝒖𝒕
= 𝑗 𝜦𝑗 − 𝟏 𝟐 𝑨𝑗 𝜦𝑗 − 𝟏 𝟐 𝒇𝒊𝒏 𝑾𝑗 • 隣接行列𝑨 + 𝑰はいくつかの行列𝑨𝑗に分解され、 𝑨 + 𝑰 = 𝑗(𝑨𝑗)となる ➡ 例:(B)の場合,𝑨0 = 𝑰および𝑨1 = 𝑨 • 𝜦𝒋 𝒊𝒊 = 𝑘(𝜦𝒋 𝒊𝒌 ) + 𝛼 • 𝑨𝑗の空の行を避けるために,α= 0.001を設定
19.
学習可能なエッジ重み • (B)の割り当ての場合 𝒇 𝒐𝒖𝒕
= 𝜦− 𝟏 𝟐(𝑨 + 𝑰) ⊗ 𝑴𝜦− 𝟏 𝟐 𝒇𝒊𝒏 𝑾 • (C)(D)の割り当ての場合 𝒇 𝒐𝒖𝒕 = 𝑗 𝜦𝑗 − 𝟏 𝟐 𝑨𝑗 ⊗ 𝑴𝜦𝑗 − 𝟏 𝟐 𝒇𝒊𝒏 𝑾𝑗 • ⊗は2つの行列間の要素的な積を表す • マスクMはオール1マトリックスとして初期化
20.
ST-GCNアーキテクチャ • ST-GCNモデルは、ST-GCNユニットが9つの層から構成されている • 64ch→
64ch→ 64ch→ 128ch→ 128ch→ 128ch→ 256ch→ 256ch→ 256ch • 4と7層目だけストライド2にすることでプーリングを行う • 各ST-GCNユニットの後に、オーバーフィットを回避するために, 確率が0.5でランダムにドロップアウト • 最後、得られたテンソルに対してグローバルプーリングを行う ➡アクションの数に合わせて最終層のチャンネル変更 • 最後に、それらをSoftMax分類器に送る
21.
実験 • Deepmind Kineticsの人間行動データセット •
YouTubeから取得した約30万のビデオクリップ • 毎日の活動、スポーツシーン、インタラクションを伴う複雑なアクションなど, 400種類のヒューマンアクションクラスをカバー • このデータセットに対して,OpenPoseツールボックスを使用して, ビデオクリップのすべてのフレームで18個の関節の位置を推定 • top1およびtop5分類精度による認識性能を評価
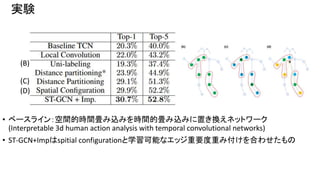
22.
実験 • ベースライン:空間的時間畳み込みを時間的畳み込みに置き換えネットワーク (Interpretable 3d
human action analysis with temporal convolutional networks) • ST-GCN+Impはspitial configurationと学習可能なエッジ重要度重み付けを合わせたもの (B) (C) (D)
23.
実験 スケルトンベースでのアクション認識 • 認識性能をトップ1とトップ5の精度で比較
24.
実験 スケルトンベースでのアクション認識 • 使用するデータセット:NTU-RGB +
D • 人間の行動認識タスクのための3Dジョイントアノテーションを持つ最大のデータセット • 制約のあるラボ環境でキャプチャされた40人のアクション • 60個のアクションクラス • 56,000個のアクションクリップ • Kinectにより取得された位置(X,Y,Z)がノード情報 • 1人当たりのノード数は25個
25.
実験 スケルトンベースでのアクション認識 • X-Sub • 1人のデータで学習 •
評価は残りの二人のデータで行う • X-View • 2方向のカメラのビデオから学習 • 上以外の方向のカメラのビデオで評価
26.
実験 • スケルトンベースの方法の精度は、ビデオフレームベースのモデルに劣るっている (The kinetics
human action video dataset) ➡ビデオフレームベースは周りのオブジェクトやシーンを認識しているから 実験 • 体の動きに強く関連しているクラスのみで,モデルの平均クラス精度を比較 ➡この場合パフォーマンスの差が少なくなる
27.
実験 • RGBモデル,オプティカルフローモデル,STGCNの3つを組み合わせて アクション認識の精度を比較 ➡ ST-GCNは、RGBおよびオプティカルフローによる最先端のモデルの精度を 達成することはできないが、そのようなモデルとお互いに補い合うことがわかる。
Editor's Notes
#21
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#22
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#23
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#24
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#25
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#26
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#27
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
#28
グローバルプーリングは最終層の層のそれぞれのチェンネルごとに平均をとったものになる
Download













![重み割り当ての式
𝑙 𝑆𝑇(𝑣 𝑞𝑗) = 𝑙 𝑡𝑖 𝑣 𝑡𝑗 + (𝑞 − 𝑡 +
𝛤
2
) × 𝐾
• 𝑙 𝑡𝑖 𝑣𝑡𝑗 は単一フレームの場合のラベルマップ
• 前ページの割り当ての決定方法がここに当たる
• 𝑙 𝑡𝑖 𝑣 𝑡𝑗 が0~𝐾 − 1までとすると, 𝑞 = 𝑡以外の時は𝐾以降の重みを参照
• 以下のように重みが入っていることになる
• [注目ノードと同じフレームの重み][𝑞 = 𝑡以外の時は𝐾以降の重み]
𝑓𝑜𝑢𝑡(𝑣 𝑡𝑖) =
𝑣 𝑡𝑗∈𝐵(𝑣 𝑡𝑖)
1
𝑍𝑡𝑖 𝑣 𝑡𝑗
𝑓𝑖𝑛(𝑣 𝑡𝑗) ∙ 𝑤(𝑙 𝑆𝑇(𝑣 𝑞𝑗))](https://image.slidesharecdn.com/st-gcn-190321054643/85/Spatial-Temporal-Graph-Convolutional-Networks-for-Skeleton-Based-Action-Recognition-14-320.jpg)




















![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)










![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)























