More Related Content

PDF

PDF

PDF

PDF

PPTX

PDF

PDF

PDF
深層自己符号化器+混合ガウスモデルによる教師なし異常検知 What's hot

PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展 
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012) 
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会 
PPT

PDF

PDF

PPTX
Sliced Wasserstein距離と生成モデル ![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant... 
PDF

PDF

PDF

PDF
続・わかりやすいパターン認識 第7章「マルコフモデル」 
PDF

PDF
Anomaly detection 系の論文を一言でまとめた 
PDF

PDF

PDF
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv... 
PPTX

PPTX
More from osamu morimoto

PDF

PDF

PDF

PDF
Tokyo.R #22 Association Rules 
PDF

PPTX

PDF
tokyo webmining3 2010.04.17. 
PDF
Tokyo.R8 brand positioning 2010.08.28. 
PDF

PDF
Tokyo r 11_self_organizing_map コサインクラスタリング
- 1.
- 2.
- 3.
- 4.
- 5.
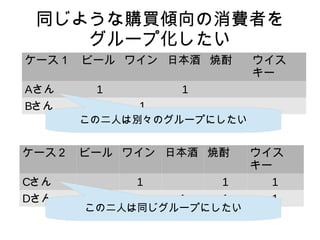
1-コサイン類似度だと
ケース1 ビール ワイン日本酒 焼酎 ウイス
キー
Aさん 1 1
Bさん 1
ケース1 ビール ワイン 日本酒 焼酎 ウイス
キー
Aさん 1 1 1
Bさん 1 1 1 1
1−コサイン類似度:1.000
1−コサイン類似度:0.423
- 6.
- 7.
- 8.