Download as PDF, PPTX






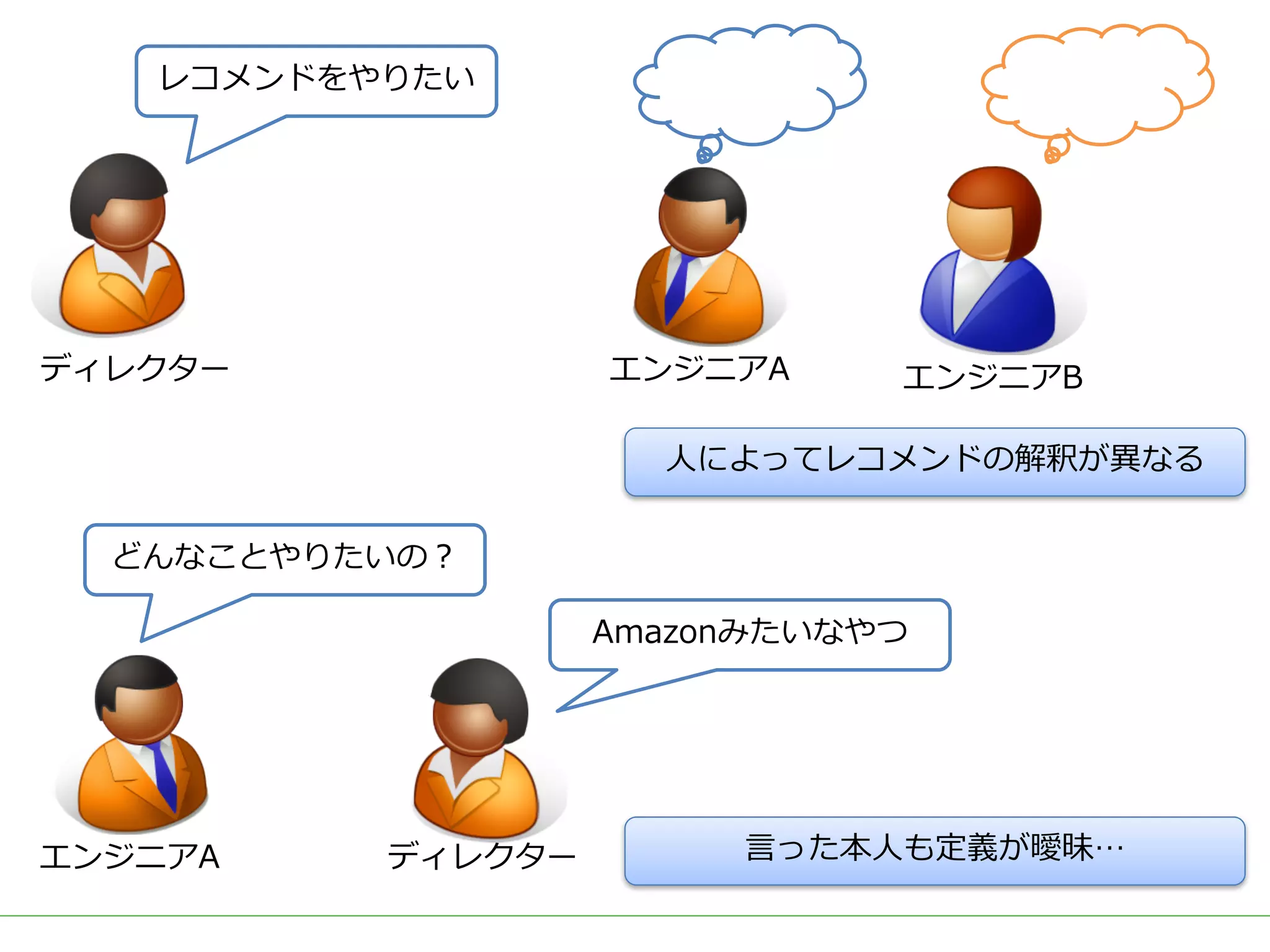
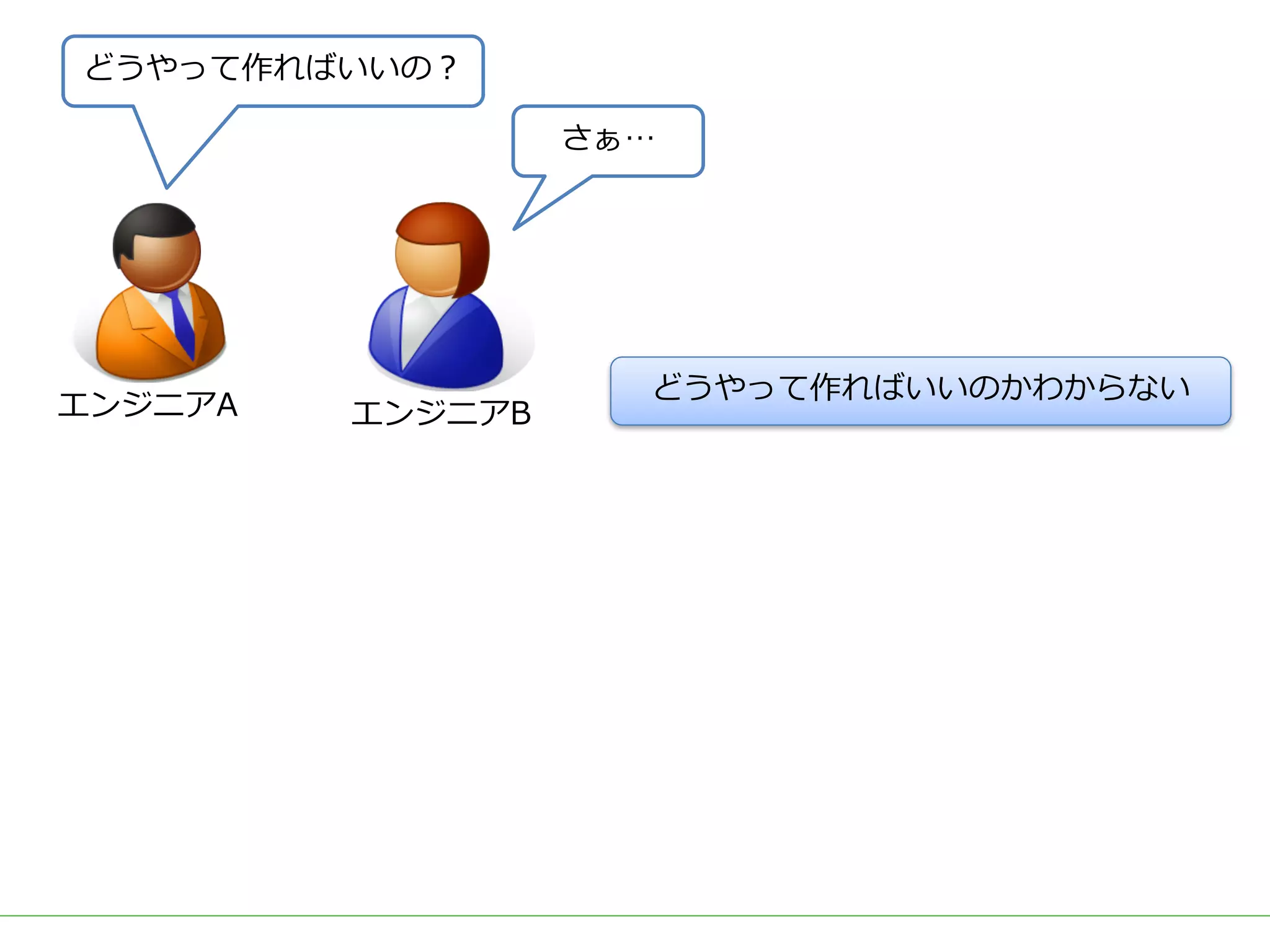

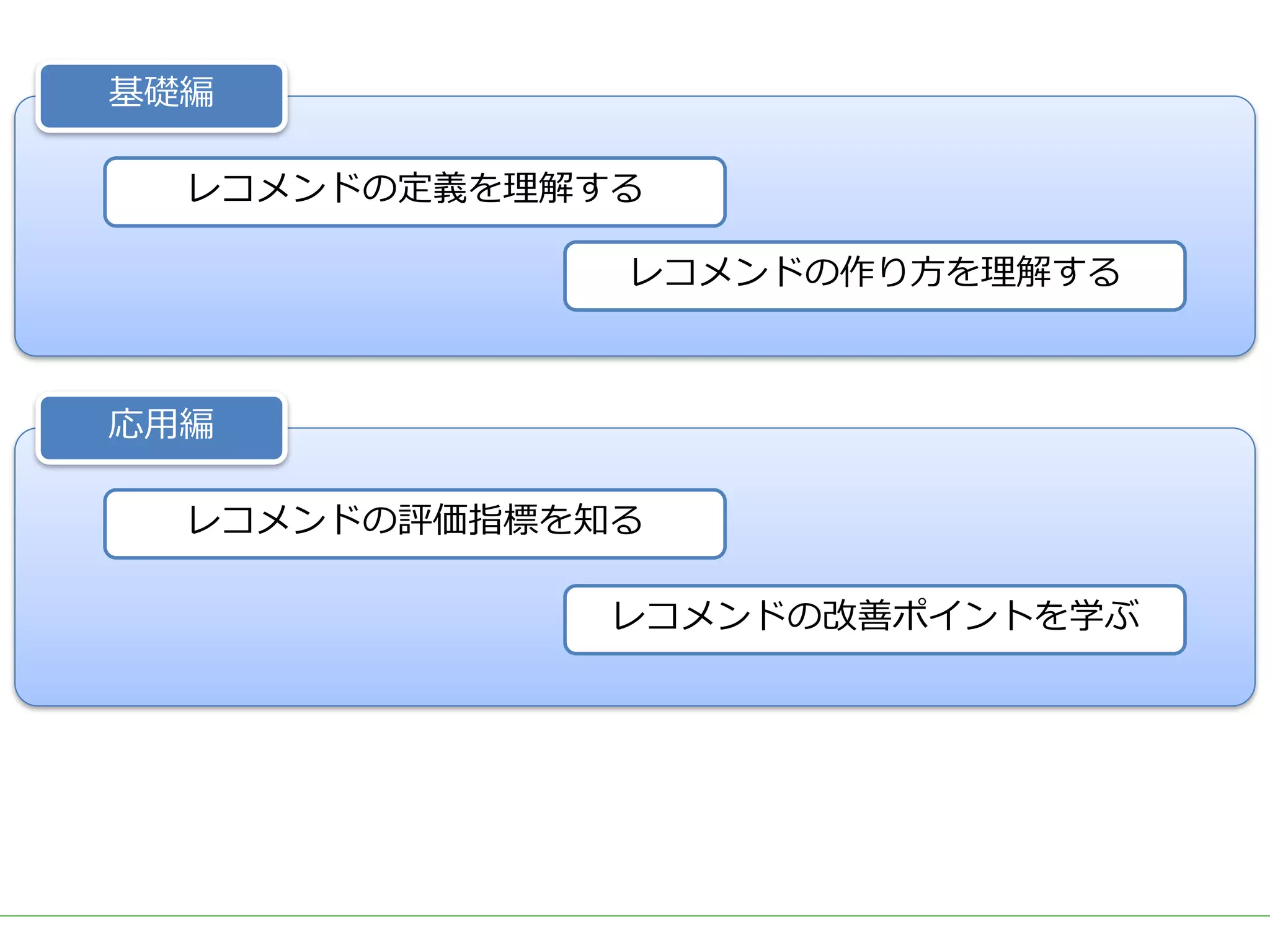






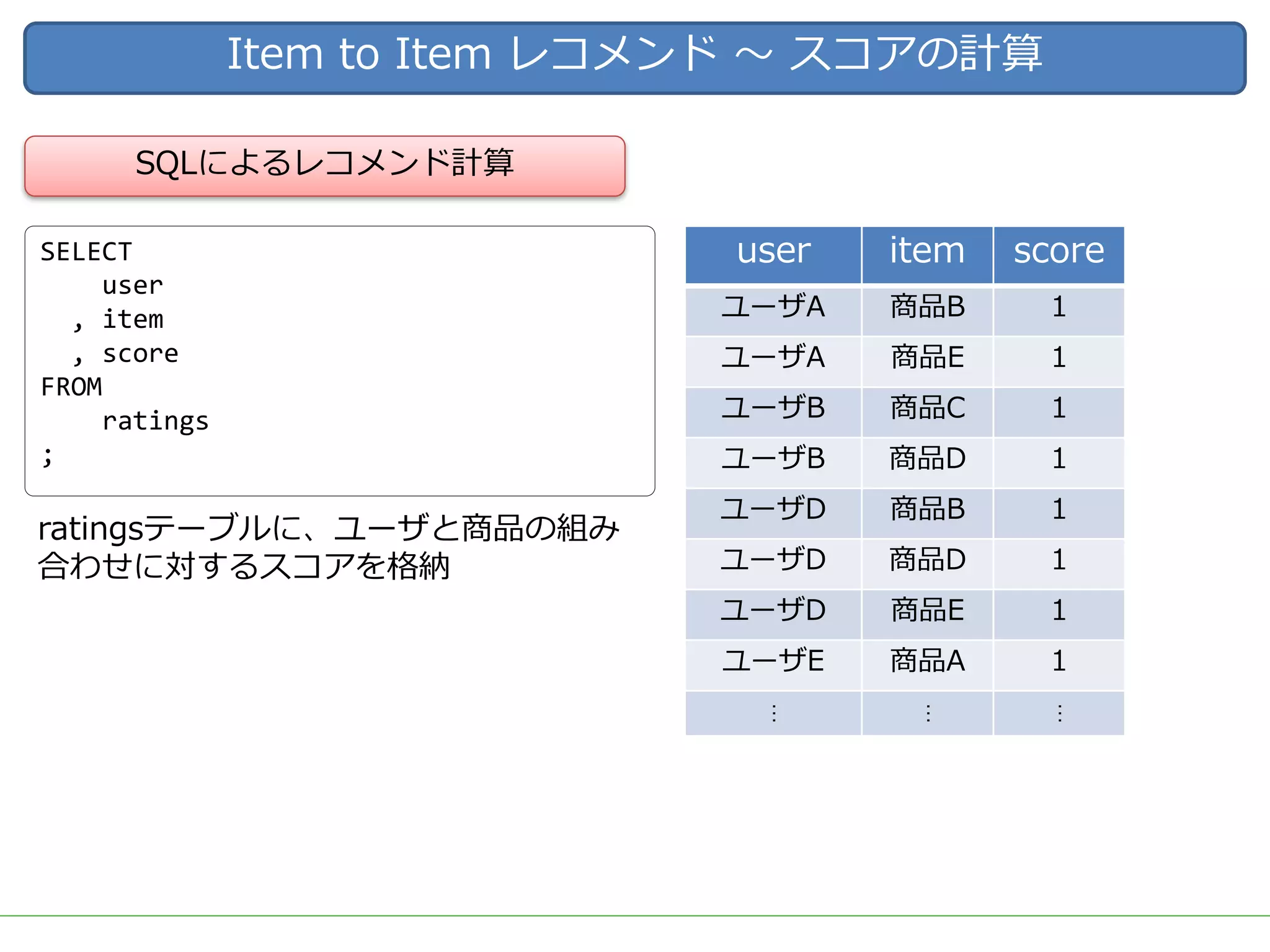

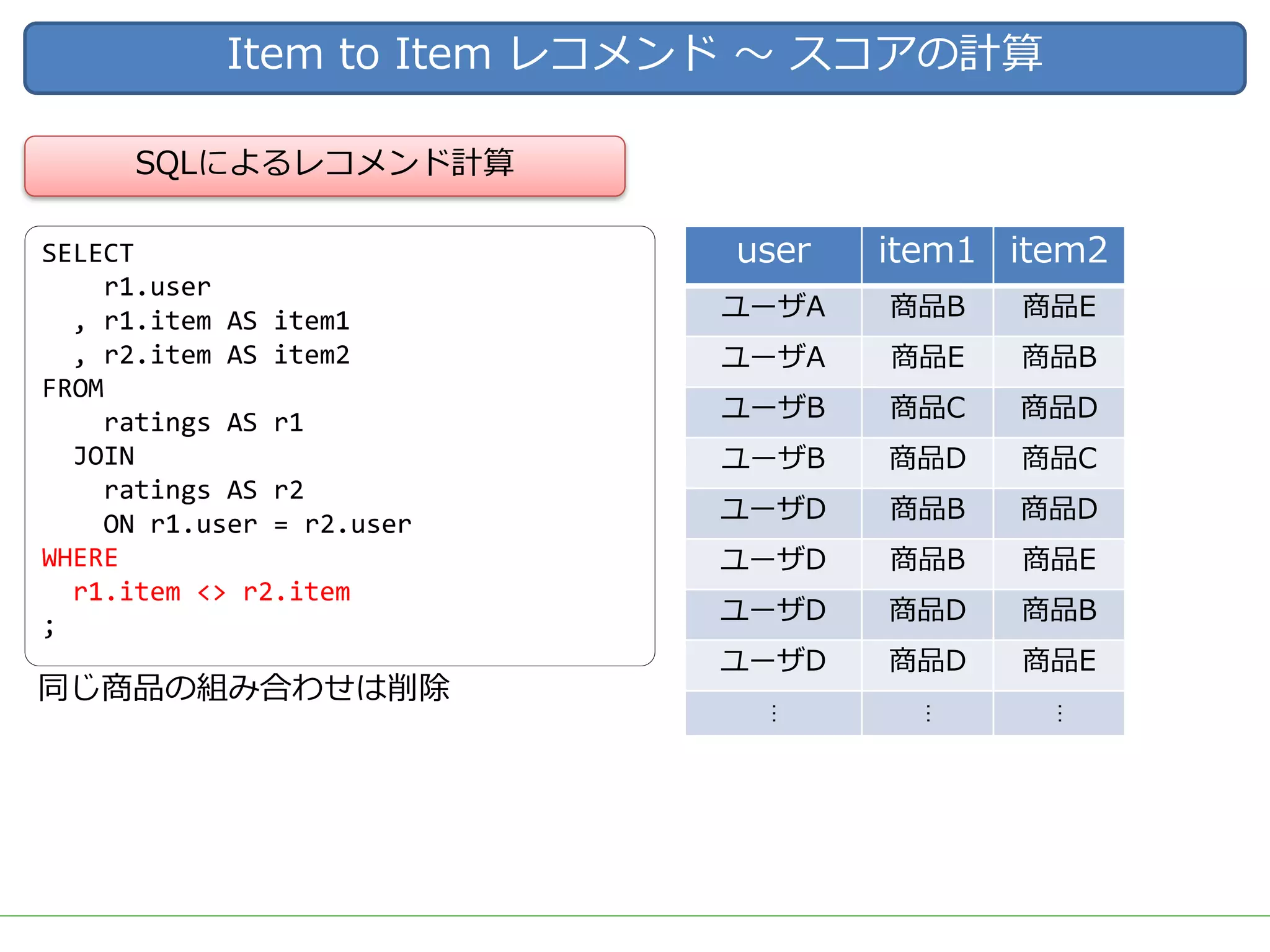

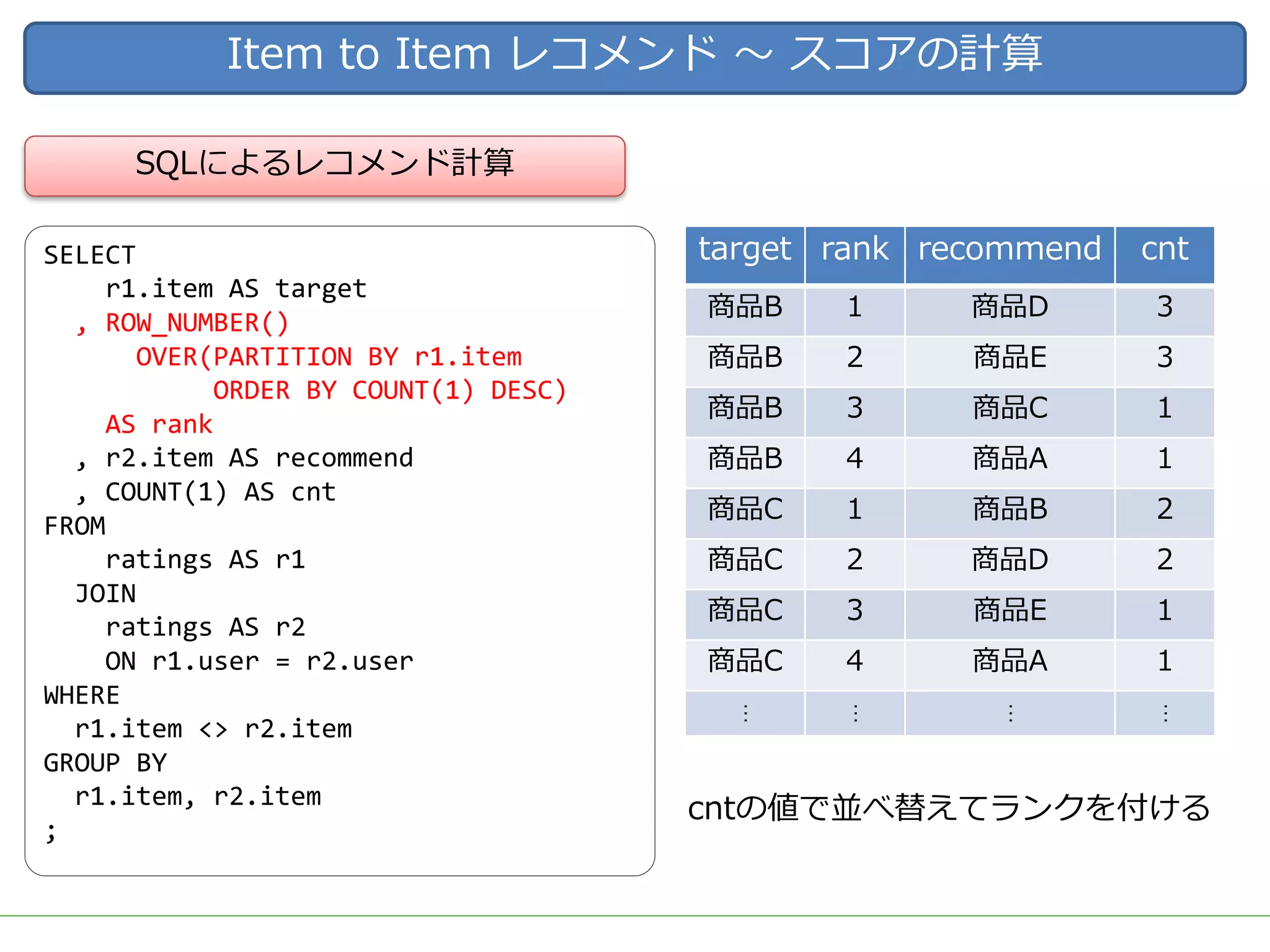
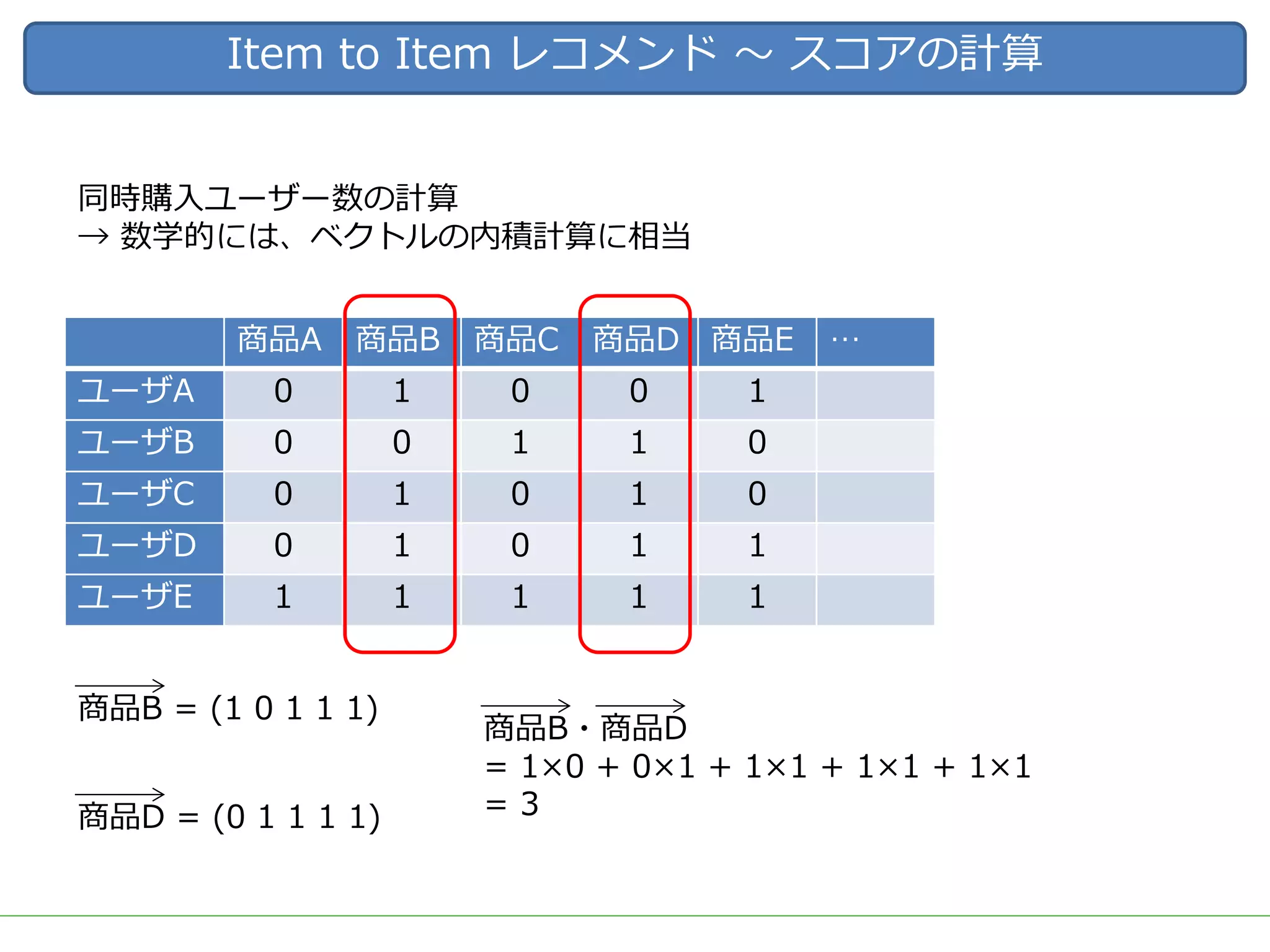
















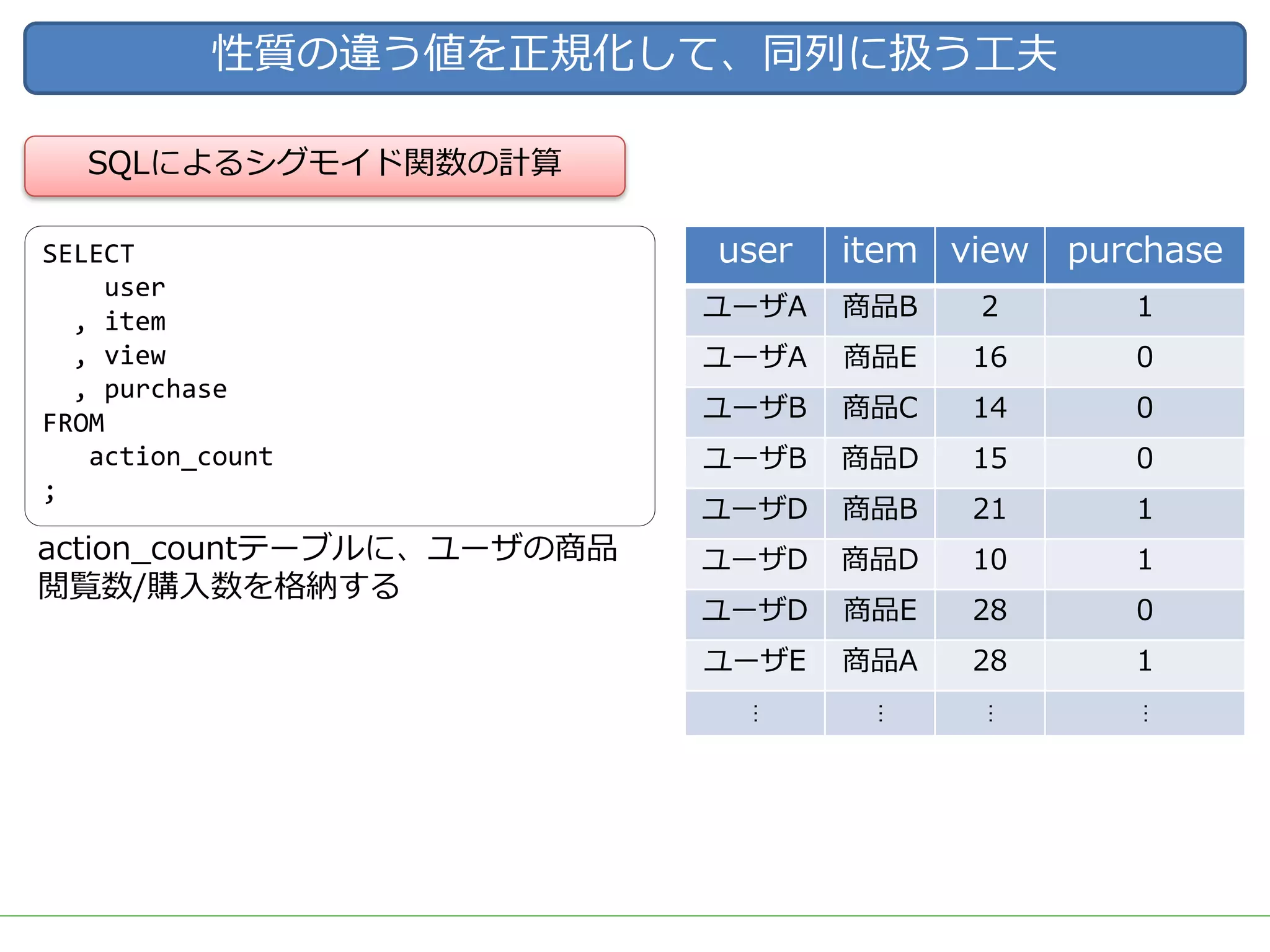





ビッグデータをビジネスに応用する上で需要の高いアウトプットとして、ユーザーの興味・関心に適した商品を自動的にオススメする「レコメンド」システムが挙げられます。 DMM.comラボでも、2015年のビッグデータ部立ち上げ後、Hadoop/Sparkを用いた内製レコメンドの導入を続け、2017年3月には400を越える箇所(Webページ、メルマガ等)で利用されています。 一口にレコメンドといっても、ユーザーの行動ログを用いた相関分析や協調フィルタリング、アイテムのメタデータを用いたコンテンツベースレコメンド、機械学習/ディープラーニングを用いた類似度計算など、要素技術は多岐に渡ります。 また、実際にレコメンドシステムを運用していくためには、レコメンドのロジックだけでなく、レコメンドを表示する際の工夫や、サービスに特化した精度のチューニング、パフォーマンスやセキュリティの考慮なども必要となってきます。 レコメンドの計算を簡単にできるツールやライブラリも多く公開されていますが、そのツールやライブラリで計算されている内容を理解しないままブラックボックスとして扱っていると、上記のような細かなチューニングや運用が難しくなります。 今回は、レコメンドのためのツールやライブラリを一切使用せず、データの前処理からレコメンドの計算、レコメンド結果の精度評価やチューニングなど、レコメンドにまつわる基本的な技術や手法を幅広く紹介し、それらの処理をSQLだけで実装した例を解説します。 データ加工の流れをステップごとに確認しながらレコメンドのロジックを理解することで、細かなチューニングや工夫を独自に考えることができるようになります。 使用するSQLも、特別なUDFなどは使用せず、標準SQLの機能を用いて実装するため、PostgreSQL, Hive, Redshift, BigQuery, SparkSQLなど多くの処理基盤で実行可能です。 今回紹介する技術や手法は、ツールやライブラリで提供されているものと比較すれば非常にシンプルなものですが、レコメンド計算以外の前処理や精度評価なども含め、レコメンドシステムを提供するための知識を一通り網羅していますので、エンジニアだけでなく、データ活用に関わる多くの人に役立てていただければ幸いです。



























 Variational Autoencoders for Collaborative Filtering](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0207hozumi-200207030936-thumbnail.jpg?width=640&height=640&fit=bounds)



















