Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
osamu morimoto
2,572 views
tokyo webmining3 2010.04.17.
Business
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 33 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
Tokyo r6 sem3
by
osamu morimoto
PDF
Tokyo webmining5
by
osamu morimoto
PDF
Tokyo r7 sem_20100724
by
osamu morimoto
PDF
クラスタ数の決め方(Tokyo.r#60)
by
osamu morimoto
PDF
Tokyo.R8 brand positioning 2010.08.28.
by
osamu morimoto
PPTX
野村データ分析コンテスト完成版
by
Shun Nakashio
PDF
ビジネス活用事例で学ぶデータサイエンス入門 #6
by
you shimajiro
PDF
マーケティング技術
by
haji mizu
Tokyo r6 sem3
by
osamu morimoto
Tokyo webmining5
by
osamu morimoto
Tokyo r7 sem_20100724
by
osamu morimoto
クラスタ数の決め方(Tokyo.r#60)
by
osamu morimoto
Tokyo.R8 brand positioning 2010.08.28.
by
osamu morimoto
野村データ分析コンテスト完成版
by
Shun Nakashio
ビジネス活用事例で学ぶデータサイエンス入門 #6
by
you shimajiro
マーケティング技術
by
haji mizu
Similar to tokyo webmining3 2010.04.17.
PDF
ターゲティング【UCHiTE】
by
Mont-Riche
PDF
実践で学ぶネットワーク分析
by
Mitsunori Sato
PDF
Rでコンジョイント分析
by
osamu morimoto
PPTX
カウミープロダクト資料ver.3_株式会社マイクロアド.pptx
by
ssuser7a8771
PDF
Tokyo webmining発表資料 20111127
by
kan_yukiko
PDF
Mktg05 市場調査(2次データ)
by
Takeshi Matsui
PDF
【慶應義塾大学】データビジネス創造コンソーシアム第25回スキル養成講座 講義資料.pdf
by
keiodig
PDF
Tokyo.R #22 Association Rules
by
osamu morimoto
PDF
おしゃスタ@リクルート
by
Issei Kurahashi
PDF
ライフスタイル・インデックスを利用したユー ザー定義事例
by
Toru Enomoto
PDF
データサイエンティスト協会 木曜勉強会 #04 『クラスター分析の基礎と総合通販会社での活用例 〜 ビッグデータ時代にクラスター分析はどう変わるか 〜』
by
The Japan DataScientist Society
PPTX
【スクー】業務改善のためのデータサイエンス
by
Issei Kurahashi
PDF
20141126 wab月例セミナー 資料
by
Dennis Sugahara
PDF
おしゃスタat銀座
by
Issei Kurahashi
PPTX
SappoRoR#11 LT: Exploring the Potential of Survey Tools Using Generative AI
by
yasuhiro ishida
PPT
マーケティング 20121005a
by
SEEDx
PPTX
13.11.15_野村総研マーケティング分析コンテスト2013(佳作賞)_Facebookとtwitterの利用者に対する消費行動分析とそれに基づく広告...
by
LINE Corp.
PPTX
【schoo WEB-campus】#49業務改善のためのデータサイエンス 先生:倉橋一成
by
webcampusschoo
PDF
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
PDF
分析のリアルがここに!現場で使えるデータ分析
by
webcampusschoo
ターゲティング【UCHiTE】
by
Mont-Riche
実践で学ぶネットワーク分析
by
Mitsunori Sato
Rでコンジョイント分析
by
osamu morimoto
カウミープロダクト資料ver.3_株式会社マイクロアド.pptx
by
ssuser7a8771
Tokyo webmining発表資料 20111127
by
kan_yukiko
Mktg05 市場調査(2次データ)
by
Takeshi Matsui
【慶應義塾大学】データビジネス創造コンソーシアム第25回スキル養成講座 講義資料.pdf
by
keiodig
Tokyo.R #22 Association Rules
by
osamu morimoto
おしゃスタ@リクルート
by
Issei Kurahashi
ライフスタイル・インデックスを利用したユー ザー定義事例
by
Toru Enomoto
データサイエンティスト協会 木曜勉強会 #04 『クラスター分析の基礎と総合通販会社での活用例 〜 ビッグデータ時代にクラスター分析はどう変わるか 〜』
by
The Japan DataScientist Society
【スクー】業務改善のためのデータサイエンス
by
Issei Kurahashi
20141126 wab月例セミナー 資料
by
Dennis Sugahara
おしゃスタat銀座
by
Issei Kurahashi
SappoRoR#11 LT: Exploring the Potential of Survey Tools Using Generative AI
by
yasuhiro ishida
マーケティング 20121005a
by
SEEDx
13.11.15_野村総研マーケティング分析コンテスト2013(佳作賞)_Facebookとtwitterの利用者に対する消費行動分析とそれに基づく広告...
by
LINE Corp.
【schoo WEB-campus】#49業務改善のためのデータサイエンス 先生:倉橋一成
by
webcampusschoo
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
分析のリアルがここに!現場で使えるデータ分析
by
webcampusschoo
Recently uploaded
PPTX
★【dodaキャンパス】27卒向け【交換できるくん】会社紹介説明資料_vol3★
by
ytajima3
PDF
【プロマネ仕事術】コミュニケーションスキル② - "報告" の5つのルール ~戦略を最大化する「戦略的報告」の技術~
by
Shunnosuke Ebina
PPTX
株式会社できるくんHP_CV最大化サイト監査レポート_主要ページ分析と改善提案
by
kotatajiri
PDF
【採用ピッチ資料】ランド・ジャパンの未来の仲間たちへ 2026年度改訂版.pdf
by
kurehanishio
PDF
#42_10.OWASPTop10_2025:An Overview and How Security Risks Have Evolved Since ...
by
OWASP Nagoya
PDF
合同会社エンジニアリングマネージメント会社説明資料_2026-02 Engineering Management LLC
by
Tsuyoshi Hisamatsu
★【dodaキャンパス】27卒向け【交換できるくん】会社紹介説明資料_vol3★
by
ytajima3
【プロマネ仕事術】コミュニケーションスキル② - "報告" の5つのルール ~戦略を最大化する「戦略的報告」の技術~
by
Shunnosuke Ebina
株式会社できるくんHP_CV最大化サイト監査レポート_主要ページ分析と改善提案
by
kotatajiri
【採用ピッチ資料】ランド・ジャパンの未来の仲間たちへ 2026年度改訂版.pdf
by
kurehanishio
#42_10.OWASPTop10_2025:An Overview and How Security Risks Have Evolved Since ...
by
OWASP Nagoya
合同会社エンジニアリングマネージメント会社説明資料_2026-02 Engineering Management LLC
by
Tsuyoshi Hisamatsu
tokyo webmining3 2010.04.17.
1.
Tokyo.Webmining #3 『市場細分化とクラスター分析』
Bob#3 2010/04/17
2.
自己紹介 ●
【はてな】 id:bob3 ● 【 Twitter 】 @bob3bob3 ● バリバリの文系です。 ● 仕事はマーケティング・リサーチャー。 ● 本日はマーケティングの中で「クラスター分析」が、どのよ うに使われているか、その一例をお話します。
3.
STP戦略 ●
市場が成熟し消費者の行動や価値観も多様化し た今日にあって、ひとつの製品やサービスで市場 のすべてのニーズを満たすことはできない。 ● そこで必要になるのが「STP戦略」というフレーム ワーク。 ● Segmentation – 市場(消費者)をいくつかのグループに細分化。 ● Targeting – ターゲットとなるグループを選択。 ● Positioning – どんな価値を提供するのかを明確にする。
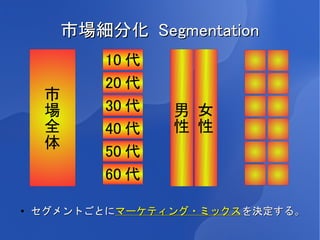
4.
市場細分化 Segmentation
10 代 20 代 市 場 30 代 男 女 全 40 代 性 性 体 50 代 60 代 ● セグメントごとにマーケティング・ミックスを決定する。
5.
マーケティング・ミックス ●
製品( Product ) – 仕様、機能、性能、パッケージなど ● 価格( Price ) – 小売価格、値引き、特売など ● 流通( Place ) – 販売経路など ● プロモーション( Promotion ) – 広告、PR、パブリシティ、イベント、キャンペーンなど
6.
ダニエル・ヤンケロビッチ曰く ●
「年齢、性別、学歴、年収など、従来のデモグラ フィックスは、すでにマーケティング戦略の拠りどこ ろとしては不十分である。」 ● 「それよりも、価値観や嗜好、選好といった特性の ほうが、消費者の購買行動への影響が大きい。」 ● 「適切なマーケティング戦略を立案するには、まず 特定のブランドや商品カテゴリーを受け入れそうな 市場セグメントを特定することである。」 ● 社会心理学者。 ● 1964年のお話。
7.
市場細分化の基準 ●
客観的基準 ● デモグラフィック(人口統計学的基準) – 年齢、性別、所得、家族構成、職業、ライフステージなど ● ジオグラフィック(地理的基準) – 居住地、気候、文化など ● 主観的基準 ● サイコグラフィック(心理的基準) – 価値観、嗜好、性格、ライフスタイルなど ● ビヘイビアル(行動的基準) – 使用頻度、使用の仕方、求めるベネフィットなど
8.
今回使うデータ ●
『経済・経営のための統計学』 ● 有斐閣 ● Rを使った分析例も一部載って ます。 ● 第8章「マーケティング」で使わ れているデータを使わせていた だきます。
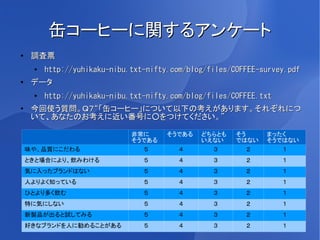
9.
缶コーヒーに関するアンケート ●
調査票 ● http://yuhikaku-nibu.txt-nifty.com/blog/files/COFFEE-survey.pdf ● データ ● http://yuhikaku-nibu.txt-nifty.com/blog/files/COFFEE.txt ● 今回使う質問。Q7“「缶コーヒー」について以下の考えがあります。それぞれにつ いて、あなたのお考えに近い番号に○をつけてください。” 非常に そうである どちらとも そう まったく そうである いえない ではない そうではない 味や、品質にこだわる 5 4 3 2 1 ときと場合により、飲みわける 5 4 3 2 1 気に入ったブランドはない 5 4 3 2 1 人よりよく知っている 5 4 3 2 1 ひとより多く飲む 5 4 3 2 1 特に気にしない 5 4 3 2 1 新製品が出ると試してみる 5 4 3 2 1 好きなブランドを人に勧めることがある 5 4 3 2 1
10.
分析の手順 1.次元縮約 ●
7つの質問項目を少数の変数に要約する。 ● 因子分析、主成分分析、 SEM などを使う。 ● 理由:解釈のしやすさ、“次元の呪い”。 2.グループ分け ● ブランド、製品などには階層型クラスター分析。 ● 消費者をグループ分けするときは分割型。 ● 決定木、潜在クラスモデルなども使われる。
11.
R にデータを読み込む # ワーキングディレクトリの設定と確認。
COFFEE.txt を置いておく。 setwd("C:/R/dat") getwd() # タブ区切りのテキストファイル。欠損値は“ .” で入力されている。 COFFEE <- read.delim("COFFEE.txt", na.strings=".") # 対象者番号と Q7 の回答を取り出す。欠損値のある対象者は除く。 Q7 <- na.omit(COFFEE[, c(1, 34:41)]) # 変数名を付ける。 colnames(Q7) <- c(" 対象者番号 ", " 味や品質にこだわる ", " 時と場合により飲みわける ", " 気に入ったブランドはない ", " 人よりよく知っている ", " ひとより多く飲む ", " 特に気にしない ", " 新製品が出ると試してみる ", " 好きなブランドを人に勧めることがある ") # 属性。ただし Q7 で欠損値のある人を除く。対象者番号は連番になっていること。 FACE <- COFFEE[Q7[, 1], c(8, 75, 76)] # 変数名を付ける。 colnames(FACE) <- c(" 飲用頻度 ", " 年齢 ", " 性別 ")
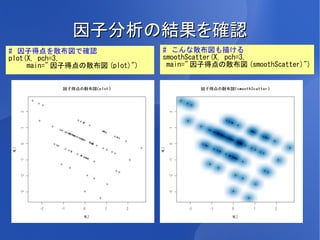
12.
R で因子分析 #
因子分析。 factanal 関数を使うのが一般的だと思いますが、ここでは出力が親切な # psych パッケージの fa 関数を使ってみます。 # 2因子、最尤法、プロマックス回転で因子分析。 # 実際にはいくつかのパターンを試して最終的な結果を決めます。 library(psych) Q7.fa <- fa(Q7[, -1], nfactors=2, rotate = "promax", scores=TRUE, fm="ml") print(Q7.fa, sort=TRUE) # Factor Analysis using method = ml # Call: fa(r = Q7[, -1], nfactors = 2, rotate = "promax", scores = TRUE, # fm = "ml") # item ML2 ML1 h2 u2 # 好きなブランドを人に勧めることがある 8 0.78 1.00 0.00 # 新製品が出ると試してみる 7 0.67 0.16 0.84 # 人よりよく知っている 4 0.63 0.26 0.74 # ひとより多く飲む 5 0.59 0.55 0.45 # 特に気にしない 6 -0.51 0.27 0.73 # 気に入ったブランドはない 3 -0.50 0.26 0.74 # 味や品質にこだわる 1 0.93 0.47 0.53 # 時と場合により飲みわける 2 0.39 0.66 0.34 # (以下略) # ML1 、 ML2 が因子負荷量、 h2 が共通性、 u2 が独自性 # ここでは仮に ML1 を「機能的関与因子」、 ML2 を「情緒的関与因子」と名づけてみます。
13.
因子分析の結果を確認 # 因子得点を X
に付値 X <- Q7.fa$scores # 因子得点をヒストグラムで確認。 # hist 関数でも良いのですが、ここでは # MASS パッケージの truehist 関数を # 使ってみます。 library(MASS) par(mfrow=c(2,1)) truehist(X[,1], main=" 情緒的関与因子 (ML2)", col="lightgreen") truehist(X[,2], main=" 機能的関与因子 (ML1)", col="lightblue") par(mfrow=c(1,1))
14.
因子分析の結果を確認 # 因子得点を散布図で確認
# こんな散布図も描ける plot(X, pch=3, smoothScatter(X, pch=3, main=" 因子得点の散布図 (plot)") main=" 因子得点の散布図 (smoothScatter)")
15.
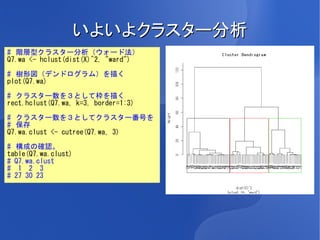
いよいよクラスター分析 # 階層型クラスター分析(ウォード法) Q7.wa <-
hclust(dist(X)^2, "ward") # 樹形図(デンドログラム)を描く plot(Q7.wa) # クラスター数を3として枠を描く rect.hclust(Q7.wa, k=3, border=1:3) # クラスター数を3としてクラスター番号を # 保存 Q7.wa.clust <- cutree(Q7.wa, 3) # 構成の確認。 table(Q7.wa.clust) # Q7.wa.clust # 1 2 3 # 27 30 23
16.
結果の確認 # クラスターごとの平均値 aggregate(X, by=list(Q7.wa.clust),
FUN=mean) # Group.1 ML2 ML1 # 1 1 1.0042568 -0.0564751 # 2 2 -0.6966410 0.8983492 # 3 3 -0.2702479 -1.1054630 # 箱髭図(3変数以上ならレーダーチャート) par(mfrow=c(1, 2)) boxplot(X[, 1] ~ Q7.wa.clust, main=" 情緒的関与因子 (ML2)", xlab=" クラスタ ", col="lightgreen") boxplot(X[, 2] ~ Q7.wa.clust, main=" 機能的関与因子 (ML1)", xlab=" クラスタ ", col="lightblue") par(mfrow=c(1, 1))
17.
結果の確認 # 飲用頻度のモザイクプロット FREQ <-
table(Q7.wa.clust, FACE[, 1]) rownames(FREQ) <- c("clust1", "clust2", "clust3") colnames(FREQ) <- c(" 毎日 ", " 週に数回 ", " 月に数回 ", " 年に数回 ") mosaicplot(FREQ, main=" クラスタ毎の飲用頻度 ", ylab=" 飲用頻度 ", xlab=" クラスタ ", col=TRUE)
18.
結果の確認 # 年代のモザイクプロット AGE <-
table(Q7.wa.clust, FACE[, 2]) rownames(AGE) <- c("clust1", "clust2", "clust3") colnames(AGE) <- c(" ~ 20", "21 ~ 25", "26 ~ 30", "31 ~ 35", "36 ~ 40", "41 ~ 60", "61 ~ ") mosaicplot(AGE, main=" クラスタ毎の年齢 ", ylab=" 年齢 ", xlab=" クラスタ ", col=TRUE, las=1)
19.
結果の確認 # 性別のモザイクプロット SEX <-
table(Q7.wa.clust, FACE[, 3]) rownames(SEX) <- c("clust1", "clust2", "clust3") colnames(SEX) <- c(" 男性 ", " 女性 ") mosaicplot(SEX, main=" クラスタ毎の性別 ", ylab=" 性別 ", xlab=" クラスタ ", col=TRUE)
20.
実例の紹介
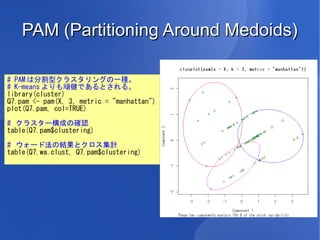
21.
PAM (Partitioning Around
Medoids) # PAM は分割型クラスタリングの一種。 # K-means よりも頑健であるとされる。 library(cluster) Q7.pam <- pam(X, 3, metric = "manhattan") plot(Q7.pam, col=TRUE) # クラスター構成の確認 table(Q7.pam$clustering) # ウォード法の結果とクロス集計 table(Q7.wa.clust, Q7.pam$clustering)
Download










![R にデータを読み込む
# ワーキングディレクトリの設定と確認。 COFFEE.txt を置いておく。
setwd("C:/R/dat")
getwd()
# タブ区切りのテキストファイル。欠損値は“ .” で入力されている。
COFFEE <- read.delim("COFFEE.txt", na.strings=".")
# 対象者番号と Q7 の回答を取り出す。欠損値のある対象者は除く。
Q7 <- na.omit(COFFEE[, c(1, 34:41)])
# 変数名を付ける。
colnames(Q7) <- c(" 対象者番号 ", " 味や品質にこだわる ",
" 時と場合により飲みわける ", " 気に入ったブランドはない ",
" 人よりよく知っている ", " ひとより多く飲む ", " 特に気にしない ",
" 新製品が出ると試してみる ",
" 好きなブランドを人に勧めることがある ")
# 属性。ただし Q7 で欠損値のある人を除く。対象者番号は連番になっていること。
FACE <- COFFEE[Q7[, 1], c(8, 75, 76)]
# 変数名を付ける。
colnames(FACE) <- c(" 飲用頻度 ", " 年齢 ", " 性別 ")](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-11-320.jpg)
![R で因子分析
# 因子分析。 factanal 関数を使うのが一般的だと思いますが、ここでは出力が親切な
# psych パッケージの fa 関数を使ってみます。
# 2因子、最尤法、プロマックス回転で因子分析。
# 実際にはいくつかのパターンを試して最終的な結果を決めます。
library(psych)
Q7.fa <- fa(Q7[, -1], nfactors=2, rotate = "promax", scores=TRUE, fm="ml")
print(Q7.fa, sort=TRUE)
# Factor Analysis using method = ml
# Call: fa(r = Q7[, -1], nfactors = 2, rotate = "promax", scores = TRUE,
# fm = "ml")
# item ML2 ML1 h2 u2
# 好きなブランドを人に勧めることがある 8 0.78 1.00 0.00
# 新製品が出ると試してみる 7 0.67 0.16 0.84
# 人よりよく知っている 4 0.63 0.26 0.74
# ひとより多く飲む 5 0.59 0.55 0.45
# 特に気にしない 6 -0.51 0.27 0.73
# 気に入ったブランドはない 3 -0.50 0.26 0.74
# 味や品質にこだわる 1 0.93 0.47 0.53
# 時と場合により飲みわける 2 0.39 0.66 0.34
# (以下略)
# ML1 、 ML2 が因子負荷量、 h2 が共通性、 u2 が独自性
# ここでは仮に ML1 を「機能的関与因子」、 ML2 を「情緒的関与因子」と名づけてみます。](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-12-320.jpg)
![因子分析の結果を確認
# 因子得点を X に付値
X <- Q7.fa$scores
# 因子得点をヒストグラムで確認。
# hist 関数でも良いのですが、ここでは
# MASS パッケージの truehist 関数を
# 使ってみます。
library(MASS)
par(mfrow=c(2,1))
truehist(X[,1], main=" 情緒的関与因子 (ML2)",
col="lightgreen")
truehist(X[,2], main=" 機能的関与因子 (ML1)",
col="lightblue")
par(mfrow=c(1,1))](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-13-320.jpg)
![結果の確認
# クラスターごとの平均値
aggregate(X, by=list(Q7.wa.clust), FUN=mean)
# Group.1 ML2 ML1
# 1 1 1.0042568 -0.0564751
# 2 2 -0.6966410 0.8983492
# 3 3 -0.2702479 -1.1054630
# 箱髭図(3変数以上ならレーダーチャート)
par(mfrow=c(1, 2))
boxplot(X[, 1] ~ Q7.wa.clust,
main=" 情緒的関与因子 (ML2)",
xlab=" クラスタ ", col="lightgreen")
boxplot(X[, 2] ~ Q7.wa.clust,
main=" 機能的関与因子 (ML1)",
xlab=" クラスタ ", col="lightblue")
par(mfrow=c(1, 1))](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-16-320.jpg)
![結果の確認
# 飲用頻度のモザイクプロット
FREQ <- table(Q7.wa.clust, FACE[, 1])
rownames(FREQ) <- c("clust1", "clust2",
"clust3")
colnames(FREQ) <- c(" 毎日 ",
" 週に数回 ",
" 月に数回 ",
" 年に数回 ")
mosaicplot(FREQ,
main=" クラスタ毎の飲用頻度 ",
ylab=" 飲用頻度 ",
xlab=" クラスタ ",
col=TRUE)](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-17-320.jpg)
![結果の確認
# 年代のモザイクプロット
AGE <- table(Q7.wa.clust, FACE[, 2])
rownames(AGE) <- c("clust1", "clust2",
"clust3")
colnames(AGE) <- c(" ~ 20", "21 ~ 25",
"26 ~ 30", "31 ~ 35",
"36 ~ 40", "41 ~ 60",
"61 ~ ")
mosaicplot(AGE, main=" クラスタ毎の年齢 ",
ylab=" 年齢 ", xlab=" クラスタ ",
col=TRUE, las=1)](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-18-320.jpg)
![結果の確認
# 性別のモザイクプロット
SEX <- table(Q7.wa.clust, FACE[, 3])
rownames(SEX) <- c("clust1", "clust2",
"clust3")
colnames(SEX) <- c(" 男性 ", " 女性 ")
mosaicplot(SEX, main=" クラスタ毎の性別 ",
ylab=" 性別 ", xlab=" クラスタ ",
col=TRUE)](https://image.slidesharecdn.com/cfakepathtokyowebmining3201004-100416230437-phpapp02/85/tokyo-webmining3-2010-04-17-19-320.jpg)