The document discusses querying temporal databases using an interval-based query language combining conjunctive queries with temporal logic in the context of ontology-based data access. This approach aims to enhance the capabilities of querying relational databases by enabling access to temporal data similar to how OWL 2 QL operates on static data. The authors propose techniques for rewriting temporal queries into SQL while addressing key challenges such as temporal joins and coalescing overlapping intervals.



![RR 2014 Querying Temporal Databases via OWL 2 QL
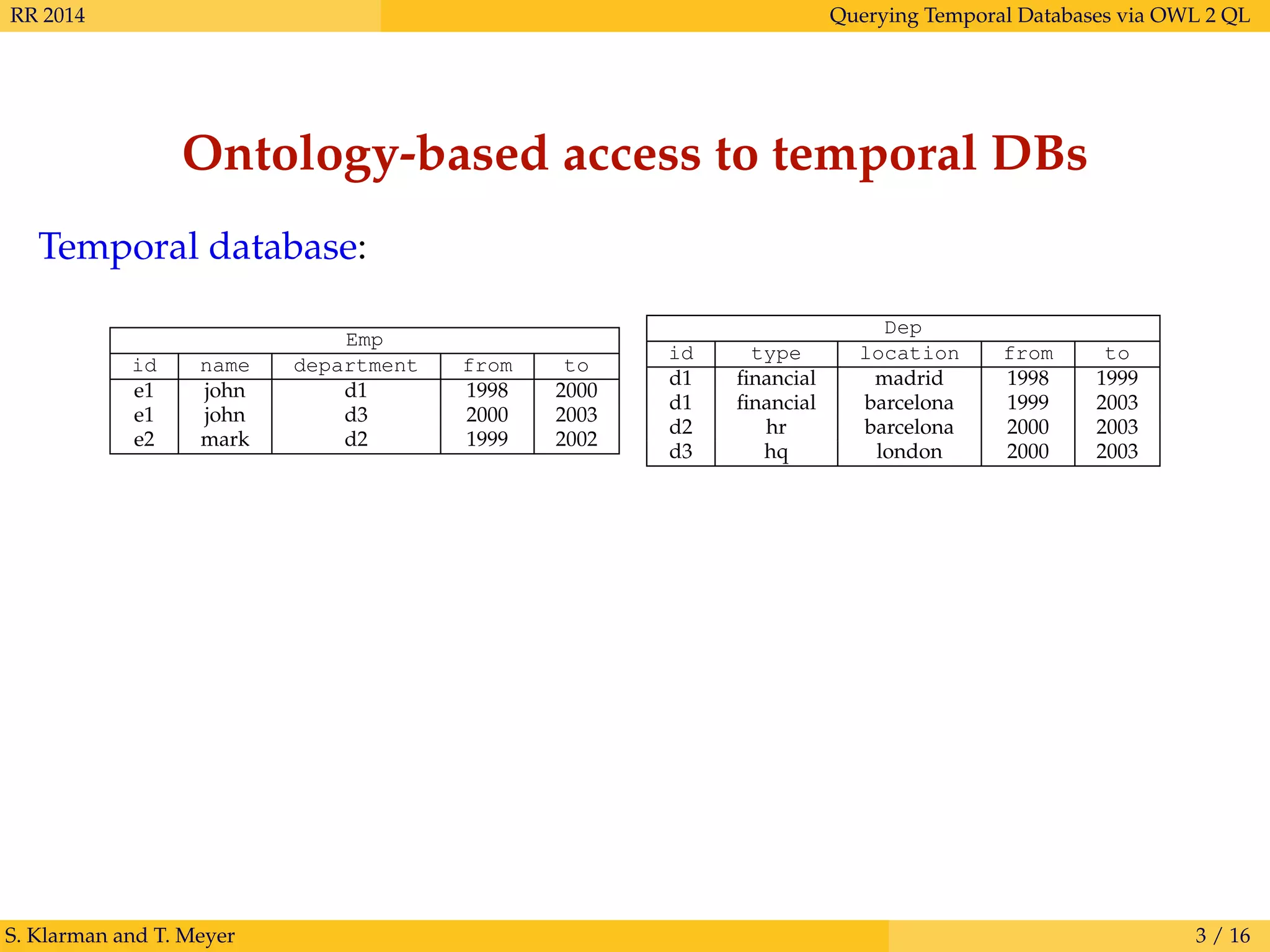
Ontology-based access to temporal DBs
Temporal database:
Emp
id name department from to
e1 john d1 1998 2000
e1 john d3 2000 2003
e2 mark d2 1999 2002
Dep
id type location from to
d1 financial madrid 1998 1999
d1 financial barcelona 1999 2003
d2 hr barcelona 2000 2003
d3 hq london 2000 2003
(Virtual) temporal ABox:
[1998, 2000] : Emp(e1)
[1998, 2000] : name(e1, john)
[1998, 2000] : department(e1, d1)
. . .
[1998, 1999] : Dep(d1)
[1998, 1999] : type(d1, financial)
[1998, 1999] : location(d1, madrid)
. . .
S. Klarman and T. Meyer 3 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-5-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Ontology-based access to temporal DBs
Temporal database:
Emp
id name department from to
e1 john d1 1998 2000
e1 john d3 2000 2003
e2 mark d2 1999 2002
Dep
id type location from to
d1 financial madrid 1998 1999
d1 financial barcelona 1999 2003
d2 hr barcelona 2000 2003
d3 hq london 2000 2003
(Virtual) temporal ABox:
[1998, 2000] : Emp(e1)
[1998, 2000] : name(e1, john)
[1998, 2000] : department(e1, d1)
. . .
[1998, 1999] : Dep(d1)
[1998, 1999] : type(d1, financial)
[1998, 1999] : location(d1, madrid)
. . .
TBox: {Emp Person, department worksAt, location basedIn}
S. Klarman and T. Meyer 3 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-6-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Ontology-based access to temporal DBs
Temporal database:
Emp
id name department from to
e1 john d1 1998 2000
e1 john d3 2000 2003
e2 mark d2 1999 2002
Dep
id type location from to
d1 financial madrid 1998 1999
d1 financial barcelona 1999 2003
d2 hr barcelona 2000 2003
d3 hq london 2000 2003
Query:
Find all persons X and times Y, such that X worked at a department based in
Barcelona during Y and in a department based in Madrid some time earlier.
Answers, e.g.:
X = e1 as Y = [1999, 2000].
S. Klarman and T. Meyer 3 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-7-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Temporal data
Time:
A time domain is a pair (T, <) (linear, point-based). An interval
τ = [τ−, τ+], for τ− ≤ τ+ ∈ T, is the set {t ∈ T | τ− ≤ t ≤ τ+}.
Temporal ABoxes:
A concrete temporal ABox is a set A of time-stamped ABox axioms:
τ : α
where τ is an interval and α is an ABox axiom, e.g.:
[1, 2] : Employee(john), [2, 2] : worksAt(john, dep1)
Every A corresponds to some abstract temporal ABox via a mapping
· , such that A = (At)t∈T, where
At = {α | τ : α ∈ A and t ∈ τ}.
S. Klarman and T. Meyer 4 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-8-2048.jpg)
 | u∗ < v∗ | ¬ψ | ψ1 ∧ ψ2 | ∃y.ψ
where:
• q is a CQ,
• u, v, y are temporal interval terms,
• ∗ ∈ {−, +}.
Example:
ψ(x, y) := [∃z.(Person(x) ∧ worksAt(x, z) ∧ basedIn(z, barcelona))](y) ∧
∃v.(v+
< y−
∧ [∃z.(worksAt(x, z) ∧ basedIn(z, madrid))](v))
S. Klarman and T. Meyer 5 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-9-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Temporal query language: semantics
For a (temporal) substitution π:
T , A, π |= u∗
< v∗
iff π(u)∗
< π(v)∗
,
T , A, π |= ¬ψ iff T , A, π |= ψ,
T , A, π |= ψ1 ∧ ψ2 iff T , A, π |= ψ1 and T , A, π |= ψ2,
T , A, π |= ∃y.ψ iff there exists τ ∈ I, such that
T , A, π[y → τ] |= ψ.
CQs are embedded in TQL using epistemic semantics.
T , A, π |= [q](u) iff T , At |= q, for every t ∈ π(u)
Therefore...
• read [q](τ) as: it is true that q is entailed in all time points in τ.
• ¬[q](τ) interpreted via negation-as-failure: it is not true that...
• CQ rewriting can be directly applied:
T , At |= q iff tdb(At) |= qT
S. Klarman and T. Meyer 6 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-10-2048.jpg)

![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
Temporal semantics is not effectively supported by SQL:2011 systems:
tdb(A) RA(a, t1, t2) iff (a, t1, t2) ∈ RD
A
E.g., for A = {[1, 2] : A(a), [2, 3] : A(a)} we get:
tdb(A) RA(a, 1, 3)
Key problems:
• computing temporal joins, i.e., identifying maximal time intervals
over which conjunctions of atoms are satisfied,
• applying coalescing, i.e., merging overlapping and adjacent
intervals for the (intermediate) query results.
S. Klarman and T. Meyer 8 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-12-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-13-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
RC(a, 1, 3)
1 2 3 4 5 6 7 8 9 10 11 12](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-14-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
RC(a, 1, 3)
1 2 3 4 5 6 7 8 9 10 11 12
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-15-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
Rq1
(a, 3, 7)
Rq2
(a, 6, 10)
RC(a, 1, 3)
Rq1
(a, 1, 3)
Rqi
1 2 3 4 5 6 7 8 9 10 11 12
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-16-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
Rq1
(a, 3, 7)
Rq2
(a, 6, 10)
RC(a, 1, 3)
Rq1
(a, 1, 3)
Rqi
1 2 3 4 5 6 7 8 9 10 11 12 qT
(x) = q1(x) ∨ q2(x)
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-17-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
Rq1
(a, 3, 7)
Rq2
(a, 6, 10)
RC(a, 1, 3)
Rq1
(a, 1, 3)
RqT (a, 1, 3)
RqT (a, 3, 7)
RqT (a, 6, 10)
Rqi
RqT
1 2 3 4 5 6 7 8 9 10 11 12 qT
(x) = q1(x) ∨ q2(x)
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-18-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
Rq1
(a, 3, 7)
Rq2
(a, 6, 10)
RqT (a, 1, 10)coal
RC(a, 1, 3)
Rq1
(a, 1, 3)
RqT (a, 1, 3)
RqT (a, 3, 7)
RqT (a, 6, 10)
Rqi
RqT
RqT
coal
1 2 3 4 5 6 7 8 9 10 11 12 qT
(x) = q1(x) ∨ q2(x)
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-19-2048.jpg)
![RR 2014 Querying Temporal Databases via OWL 2 QL
Query answering
temp. ABox: {[1, 7] : B(a), [1, 3] : C(a), [3, 10] : C(a), [6, 12] : D(a)}
TBox: {D B}
TQL query: [q(a)]([2, 9]), where q(x) = B(x) ∧ C(x)
S. Klarman and T. Meyer 9 / 16
RB(a, 1, 7)
RD(a, 6, 12)
RC(a, 3, 10)
Rq1
(a, 3, 7)
Rq2
(a, 6, 10)
RqT (a, 1, 10)coal
RC(a, 1, 3)
Rq1
(a, 1, 3)
RqT (a, 1, 3)
RqT (a, 3, 7)
RqT (a, 6, 10)
Rqi
RqT
RqT
coal
1 2 3 4 5 6 7 8 9 10 11 12
coal
[q(a)]([2,9])
qT
(x) = q1(x) ∨ q2(x)
q2(x) = D(x) ∧ C(x)
q1(x) = B(x) ∧ C(x)](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-20-2048.jpg)
, where q1(a) = B(a) ∧ C(a) and q2(a) = D(a) ∧ C(a):
[q(a)]([2, 9]) 2FO
∃t1, t2.(Rcoal
qT (a, t1, t2) ∧ t1 ≤ 2 ∧ 9 ≤ t2)
Rcoal
qT (a, t1, t2) ∃t3, t4.RqT (a, t1, t3) ∧ RqT (a, t4, t2) ∧
¬∃t5, t6.(RqT (a, t5, t6) ∧ t5 < t1 ∧ t1 ≤ t6) ∧
¬∃t5, t6.(RqT (a, t5, t6) ∧ t5 ≤ t2 ∧ t2 < t6) ∧
¬∃t5, t6.(RqT (a, t5, t6) ∧ t1 < t5 ∧ t6 ≤ t2 ∧
¬∃t7, t8.(RqT (a, t7, t8) ∧ t7 < t5 ∧ t5 ≤ t8))
RqT (a, u, v) Rq1
(a, u, v) ∨ Rq2
(a, u, v)
Rq1
(a, u, v) ∃t1, . . . , t4.(RB(a, t1, t2) ∧ RC(a, t3, t4)) ∧
u = max(t1, t3) ∧ v = min(t2, t4) ∧ u ≤ v
Rq2
(a, u, v) ∃t1, . . . , t4.(RD(a, t1, t2) ∧ RC(a, t3, t4)) ∧
u = max(t1, t3) ∧ v = min(t2, t4) ∧ u ≤ v
S. Klarman and T. Meyer 10 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-21-2048.jpg)





A potentially better-behaved approach based on materialized view
maintenance: incremental, more responsive to updates.
S. Klarman and T. Meyer 15 / 16](https://image.slidesharecdn.com/klamey-rr14-170821074136/75/Querying-Temporal-Databases-via-OWL-2-QL-26-2048.jpg)















































































