Downloaded 25 times





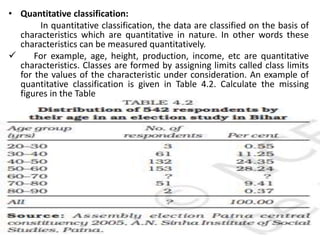
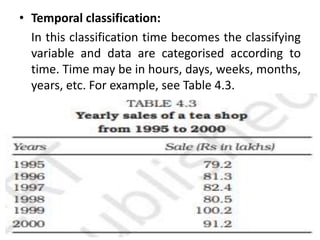
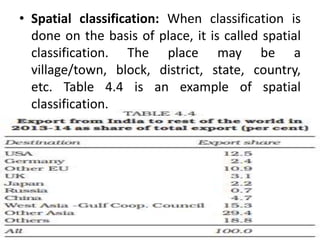



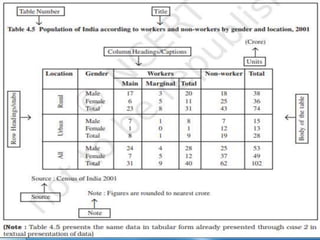






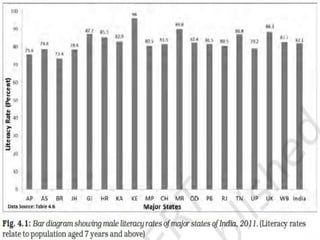



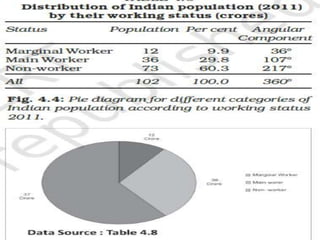


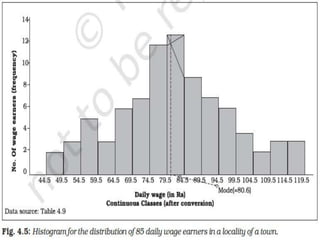







Dr. Jitendra Patel's presentation outlines three primary forms of data presentation: textual, tabular, and diagrammatic, emphasizing their utility in making voluminous data comprehensible. It details methods for tabulating data, including types of classification (qualitative, quantitative, temporal, and spatial), and describes various diagrammatic methods for visual data representation. The aim is to equip individuals with the knowledge to select the appropriate presentation form and diagram type for effective data communication.