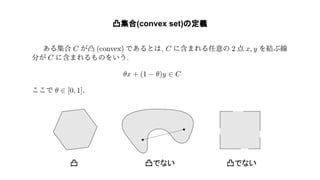
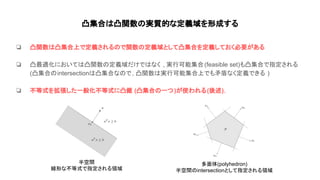
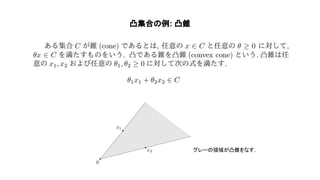
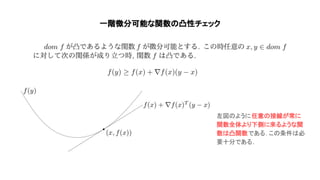
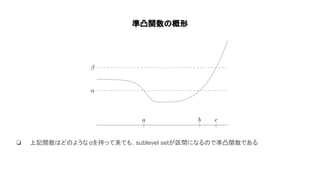
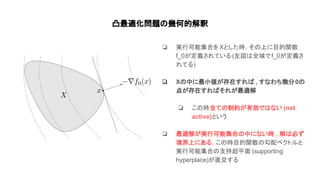
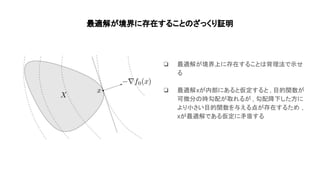
Convex optimization(https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf)の1~4章の内容を紹介した. 主に扱ったトピックは凸集合, 凸関数, 凸最適化の定義や例で内容は初心者向け. 気になった人は是非原著に当たって欲しい.








![錐 ベクトル 大小関係を規定するためにも使われる
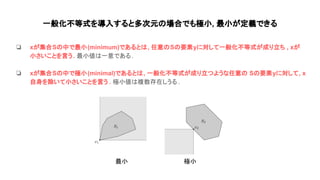
❏ 最適化問題において目的関数 戻り値がベクトル 時 , ベクトル 良さを比較する必要 がある
❏ ベクトル間 大小関係 非自明
ex) [3, 3, 3]と[1, 1, 1]なら前者が大きそうだが , [1, 3, 4]と[2, 1, 4] …?
❏ 凸錐 概念 一般化不等式に直接使われる . 厳密に 凸錐より強い 真錐(proper cone)を使う
一般化不等式を使って大小関係を比較する](https://image.slidesharecdn.com/convexoptimization1-190126031512/85/Convex-optimization-11-320.jpg)
































![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)






























