More Related Content

PDF
データサイエンティストとは? そのスキル/ナレッジレベル定義の必要性 
PDF
データサイエンティスト養成勉強会 こんな僕がデータサイエンティストになれた秘密 
PPTX
既存分析ソフトへ
データを投入する前に
簡便な分析するためのソフトの作り方の提案 
PDF
(道具としての)データサイエンティストのつかい方 
PDF
データ分析というお仕事のこれまでとこれから(HCMPL2014) 
PPTX
Microsoft Ignite 2019 最新アップデート - Azure Big Data Services を俯瞰的に眺める 
PDF
ビッグデータエコシステムとデータサイエンスのススメ 
PPTX
企業等に蓄積されたデータを分析するための処理機能の提案 Similar to Sqlgen190412.pdf

PDF

PPTX
Oracle Advanced Analytics 概要 
PDF
ChatGPTなど生成AI時代に必要なビジネスデータ分析入門(2024年1月17日) 
PDF

PDF
20151209 Oracle DDD オラクルで実現するクラウド・マシン・ラーニング 
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1 
PDF

PPTX

PPTX
More from Toshiyuki Shimono

PDF
大量の表形式データを 有効活用するための方法論 – 70個以上のソフトウェア作成からの知見– 
PPTX
インターネット等からデータを自動収集するソフトウェアに必要な補助機能とその実装 
PPTX
extracting only a necessary file from a zip file 
PPTX
A Hacking Toolset for Big Tabular Files -- JAPAN.PM 2021 
PDF
新型コロナの感染者数 全国の状況 2021年2月上旬まで 
PDF

PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K... 
PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K... 
PDF
Make Accumulated Data in Companies Eloquent by SQL Statement Constructors (PDF) 
PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX
A Hacking Toolset for Big Tabular Files (3) 
PPTX
Washingtondc b20161214 (2/3) 
PPTX

PPTX

PPTX
Sqlgen190412.pdf
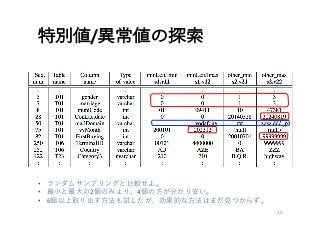
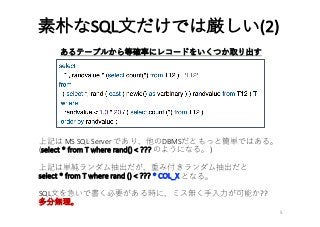
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
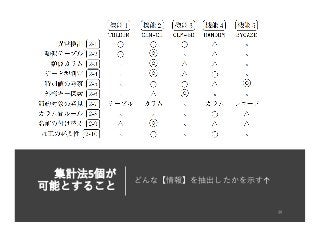
5個の集計⽅法のまとめ
① 件数⼀覧 :
多数のテーブルの混同を阻⽌できる
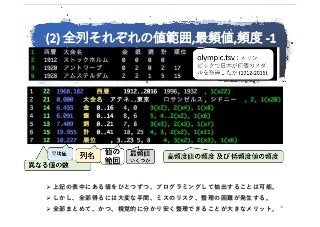
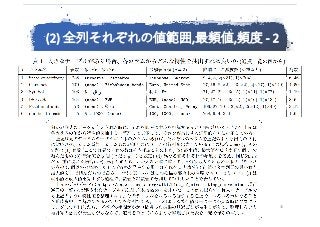
②各列(カラム)の値範囲-頻度-特性:
多数の列の意味の把握が、ワンショットで⼤きく進む
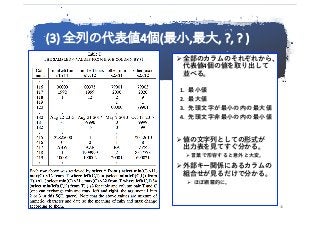
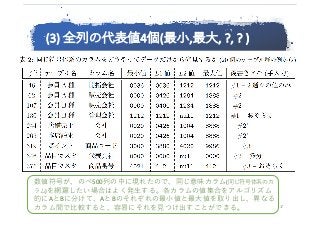
③ 各列の代表値4個 :
特別値と網羅的な外部キーの把握が容易
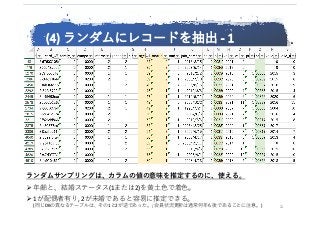
④ ランダム抽出 :
列間の関係が容易に推測できる。(不確定性は必ず残る)
符号値の意味が容易に推論できる。
⑤ 場合分けで同じテーブルの全列の値範囲-頻度-特性 :
ある列で特別値が発⽣するレコードについて、
どんな条件が他の列で起こるとそうなるかが分かる。
24
上記の集計⼿段があれば、DBの内容について殆ど何も知らない状態から、
すぐに各テーブルや各列のことが容易に網羅的に把握出来て、分析/DB移
⾏などが容易となる。
ここから3スライド
で、提案5 個で何が
できるかを整理する
- 25.
- 26.
- 27.
5個の他に考えられる集計法
Ø 各列の分位点を取り出す
Ø あるテーブルの複合キー列の候補を探索する機能
Ø複数の値集合(様々なテーブルの様々な列)からベン図を描くような機能
Ø あるテーブルで、ある列の値が別の列の値を決定する様⼦を網
羅的に決める機能(関数従属性)
Ø あるテーブルで、複数の列の前後/⼤⼩関係を決める機能
Ø ⻑すぎる識別⼦に対して先頭から最低何⽂字あれば識別できる
か決める機能
Ø 複数のテーブルで、何⼈かの同じユーザーをDBから抽出して、
トラッキングして、テーブル間で⾒やすい形で⽐較する機能。
27
集計⽅法が多すぎると、それぞれのSQL⽂⽣成器についての、
習得困難や存在忘却のデメリットが発⽣するので、
(集計⽅法とそのSQL⽂⽣成器の)厳選が必要であることに注意。
- 28.
- 29.
- 30.
- 31.





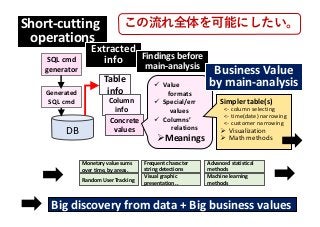



![【DBを理解する】作業⼿順の流れ
下記を把握する/把握可能にする :
1. 全てのテーブルのそれぞれ
2. それらテーブルの各カラム[キー,特別値,..]
3. 各テーブルの異カラム間の関係[関数従属性, ⼤⼩]
4. 異なるテーブル間の関係[外部キー]
5. 同じユーザー個体の複数テーブルでの挙動
6. ⽂字列値の部分⽂字列が頻出する様⼦
11
4
取り消し線は、後述する⾃動⽣成されるSQL⽂の機能が未設計という意
味で有り、完了という意味ではありません。](https://image.slidesharecdn.com/sqlgen190412-190411074710/85/Sqlgen190412-pdf-11-320.jpg?cb=1715126069)