Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Toshiyuki Shimono
PDF, PPTX
813 views
BigQueryを使ってみた(2018年2月)
Google BigQuery この資料は社内関係者の許可を得て、BigQuery を初めて使って分かったことを人に随時説明するために、補助資料として作ったものを公開するものです。
Data & Analytics
◦
Related topics:
Data Analysis Insights
•
Data Mining Insights
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 8
2
/ 8
3
/ 8
4
/ 8
5
/ 8
6
/ 8
7
/ 8
8
/ 8
More Related Content
PDF
BigQuery 使ってみよう
by
Noriko Takiguchi
PPTX
C# Database操作5 SqlDataAdapterを使用したデータの取得-
by
Hiroki Takahashi
PPTX
C# Database操作6 SqlDataAdapterを使用したデータの更新-
by
Hiroki Takahashi
PDF
これでBigQueryをドヤ顔で語れる!BigQueryの基本
by
Tomohiro Shinden
PDF
BigQueryを始めてみよう - Google Analytics データを活用する
by
Google Cloud Platform - Japan
PDF
Google Cloud ベストプラクティス:Google BigQuery 編 - 01 : BigQuery とは?
by
Google Cloud Platform - Japan
PDF
Google BigQueryを使ってみた!
by
Yusuke Wada
PDF
BigQuery + Fluentd
by
徹 上野山
BigQuery 使ってみよう
by
Noriko Takiguchi
C# Database操作5 SqlDataAdapterを使用したデータの取得-
by
Hiroki Takahashi
C# Database操作6 SqlDataAdapterを使用したデータの更新-
by
Hiroki Takahashi
これでBigQueryをドヤ顔で語れる!BigQueryの基本
by
Tomohiro Shinden
BigQueryを始めてみよう - Google Analytics データを活用する
by
Google Cloud Platform - Japan
Google Cloud ベストプラクティス:Google BigQuery 編 - 01 : BigQuery とは?
by
Google Cloud Platform - Japan
Google BigQueryを使ってみた!
by
Yusuke Wada
BigQuery + Fluentd
by
徹 上野山
Similar to BigQueryを使ってみた(2018年2月)
PDF
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
PDF
Google BigQuery 導入編
by
zuya
KEY
Google bigqueryとは
by
Junya Yamaguchi
PDF
Google bigquery導入記
by
Yugo Shimizu
PDF
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
PDF
BigQueryのちょっとした話 #phpblt
by
kunit
PDF
Google Cloud ベストプラクティス:Google BigQuery 編 - 02 : データ処理 / クエリ / データ抽出
by
Google Cloud Platform - Japan
PDF
Google Cloud ベストプラクティス:Google BigQuery 編 - 03 : パフォーマンスとコストの最適化
by
Google Cloud Platform - Japan
PDF
BigQuery で 150万円 使ったときの話
by
itkr
PPTX
BigQuery Query Optimization クエリ高速化編
by
sutepoi
PDF
弊社BigQuery節約節約事例
by
shoishihara1
PDF
普通に使える?BigQuery
by
Wasaburo Miyata
PDF
BigQueryで実現するデータ統合
by
さとる なかむら
PPTX
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
PDF
gcpug_kyoto_bigquery
by
さとる なかむら
PDF
[Cloud OnAir] BigQuery の一般公開データセットを 利用した実践的データ分析 2019年3月28日 放送
by
Google Cloud Platform - Japan
PDF
6 月 18 日 Next - Google が描く、MapReduce を超えたビッグデータの世界
by
Google Cloud Platform - Japan
PDF
Google Analytics のデータ分析ハンズオン
by
Kenichi Tatsuhama
PPTX
非エンジニアよ エクセル辞めてBigQueryを使いなさい
by
Hironari Ono
PPTX
BigQuery ハンズオン
by
さとる なかむら
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
Google BigQuery 導入編
by
zuya
Google bigqueryとは
by
Junya Yamaguchi
Google bigquery導入記
by
Yugo Shimizu
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
BigQueryのちょっとした話 #phpblt
by
kunit
Google Cloud ベストプラクティス:Google BigQuery 編 - 02 : データ処理 / クエリ / データ抽出
by
Google Cloud Platform - Japan
Google Cloud ベストプラクティス:Google BigQuery 編 - 03 : パフォーマンスとコストの最適化
by
Google Cloud Platform - Japan
BigQuery で 150万円 使ったときの話
by
itkr
BigQuery Query Optimization クエリ高速化編
by
sutepoi
弊社BigQuery節約節約事例
by
shoishihara1
普通に使える?BigQuery
by
Wasaburo Miyata
BigQueryで実現するデータ統合
by
さとる なかむら
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
gcpug_kyoto_bigquery
by
さとる なかむら
[Cloud OnAir] BigQuery の一般公開データセットを 利用した実践的データ分析 2019年3月28日 放送
by
Google Cloud Platform - Japan
6 月 18 日 Next - Google が描く、MapReduce を超えたビッグデータの世界
by
Google Cloud Platform - Japan
Google Analytics のデータ分析ハンズオン
by
Kenichi Tatsuhama
非エンジニアよ エクセル辞めてBigQueryを使いなさい
by
Hironari Ono
BigQuery ハンズオン
by
さとる なかむら
More from Toshiyuki Shimono
PDF
大量の表形式データを 有効活用するための方法論 – 70個以上のソフトウェア作成からの知見–
by
Toshiyuki Shimono
PPTX
インターネット等からデータを自動収集するソフトウェアに必要な補助機能とその実装
by
Toshiyuki Shimono
PPTX
extracting only a necessary file from a zip file
by
Toshiyuki Shimono
PPTX
A Hacking Toolset for Big Tabular Files -- JAPAN.PM 2021
by
Toshiyuki Shimono
PDF
新型コロナの感染者数 全国の状況 2021年2月上旬まで
by
Toshiyuki Shimono
PDF
Sqlgen190412.pdf
by
Toshiyuki Shimono
PPTX
既存分析ソフトへ データを投入する前に 簡便な分析するためのソフトの作り方の提案
by
Toshiyuki Shimono
PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
PPTX
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
PDF
Make Accumulated Data in Companies Eloquent by SQL Statement Constructors (PDF)
by
Toshiyuki Shimono
PPTX
企業等に蓄積されたデータを分析するための処理機能の提案
by
Toshiyuki Shimono
PPTX
新入社員の頃に教えて欲しかったようなことなど
by
Toshiyuki Shimono
PPTX
ページャ lessを使いこなす
by
Toshiyuki Shimono
PPTX
Guiを使わないテキストデータ処理
by
Toshiyuki Shimono
PPTX
データ全貌把握の方法170324
by
Toshiyuki Shimono
PPTX
Macで開発環境を整える170420
by
Toshiyuki Shimono
PPTX
大きなテキストデータを閲覧するには
by
Toshiyuki Shimono
PPTX
A Hacking Toolset for Big Tabular Files (3)
by
Toshiyuki Shimono
PPTX
Washingtondc b20161214 (2/3)
by
Toshiyuki Shimono
PPTX
耐巨大性を備えた表データ分析用コマンド群
by
Toshiyuki Shimono
大量の表形式データを 有効活用するための方法論 – 70個以上のソフトウェア作成からの知見–
by
Toshiyuki Shimono
インターネット等からデータを自動収集するソフトウェアに必要な補助機能とその実装
by
Toshiyuki Shimono
extracting only a necessary file from a zip file
by
Toshiyuki Shimono
A Hacking Toolset for Big Tabular Files -- JAPAN.PM 2021
by
Toshiyuki Shimono
新型コロナの感染者数 全国の状況 2021年2月上旬まで
by
Toshiyuki Shimono
Sqlgen190412.pdf
by
Toshiyuki Shimono
既存分析ソフトへ データを投入する前に 簡便な分析するためのソフトの作り方の提案
by
Toshiyuki Shimono
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
To Make Graphs Such as Scatter Plots Numerically Readable (PacificVis 2018, K...
by
Toshiyuki Shimono
Make Accumulated Data in Companies Eloquent by SQL Statement Constructors (PDF)
by
Toshiyuki Shimono
企業等に蓄積されたデータを分析するための処理機能の提案
by
Toshiyuki Shimono
新入社員の頃に教えて欲しかったようなことなど
by
Toshiyuki Shimono
ページャ lessを使いこなす
by
Toshiyuki Shimono
Guiを使わないテキストデータ処理
by
Toshiyuki Shimono
データ全貌把握の方法170324
by
Toshiyuki Shimono
Macで開発環境を整える170420
by
Toshiyuki Shimono
大きなテキストデータを閲覧するには
by
Toshiyuki Shimono
A Hacking Toolset for Big Tabular Files (3)
by
Toshiyuki Shimono
Washingtondc b20161214 (2/3)
by
Toshiyuki Shimono
耐巨大性を備えた表データ分析用コマンド群
by
Toshiyuki Shimono
BigQueryを使ってみた(2018年2月)
1.
Google BigQuery を 使ってみた 2018-02-14 下野寿之 この資料は社内関係者の許可を得て、BigQuery を 初めて使って分かったことを人に随時説明するために、 補助資料として作ったものを公開するものです。
2.
BigQuery とは ØGoogle クラウドのサービスの1つ。 ØSQL⽂でデータの参照が出来る。 ØSQL⽂のUpdate と Deleteはできない。 Øインデックスも無いようだ。 Øとにかく速い。 Ø裏で数千台数万台のサーバーに計算を⾛らせている。 Ø今まで、2分以上かかったことが無い。 Ø簡単な計算は10〜15秒。簡単なのに60秒かかることもある。 Ø料⾦は
1TB(テラバイト)の参照に5ドル。 Øデータを1週間保管すると、同じ料⾦がかかる。 ØCPUに負荷がかかるような計算をしても、⼀定。 Ø参照する列(カラム)を減らすと、節約可能。 ØWhere 句で参照する⾏が、コスト上は減らない。
3.
BigQueryを使う為には • データのインポート: • GoogleクラウドのGCS(Google Cloud Storage)に データファイルを載せて、インポートを要する。 •
ブラウザで使う • Googleアカウントを1つだけログインして使う。 • 他のGoogleアカウントは使えない。 • ブラウザはChrome も Canaryも同時に起動すると、 メールやGoogleドライブの参照に便利。
4.
BigQuery のSQL • Legacy と標準(Standard) SQL
の選択が必要。 • ブラウザでオプション設定して使う。 • Legacyはjoinやcount(distinct ..)に各種配慮が必要。 • ジョイン(複数のテーブルの結合) • 最近は、{left, right, full} outer join が全て実⾏可能。 • 共有メモリの制約が気になったものの、問題無し。 • Over()句を使った分析関数が使える。 • Row_numer, rank, ntile, approx_{top_count ,quantile} • 配列も使える。 • 正規表現(regular expression)による演算も可能。
5.
BigQueryの結果の出⼒ • 20〜30⾏以内: • ブラウザからエクセルへコピペする。 •
少しコツが必要。コピー領域は出⼒表の 最後のセルをぴったり選択する必要があるようだ。 • 約1万⾏以内: • CSV 形式ですぐ出⼒出来る。 • “配列” を含むセルが存在すると、出⼒不能になる。 • それ以上 : • Google Cloud Storage を経由する。 • ローカルにGoogle Cloud SDK が必要のようだ。
6.
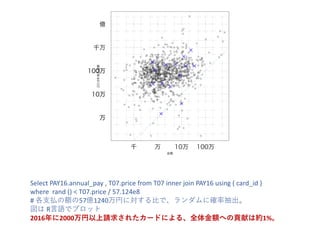
select age, q6[offset(1)], q6[offset(2)], q6[offset(3)], q6[offset(4)], q6[offset(5)] from (select age, approx_quantile(pay,6) q6 from T01 inner join PAY2016 using ( card_id ) group by age ) 1/6 2/6 3/6 4/6 5/6
7.
参照した4個の表 : 6 - 請求情報
7-確定情報 8-月次請求額 22-支払判定 6と7と22に各⽀払の⽇付情報あり。6と7と8に、毎⽉の締年⽉の⽇付列あり。
8.
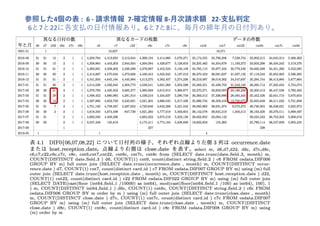
Select PAY16.annual_pay , T07.price from T07 inner join PAY16 using ( card_id ) where rand () < T07.price / 57.124e8 # 各⽀払の額の57億1240万円に対する⽐で、ランダムに確率抽出。 図は R⾔語でプロット 2016年に2000万円以上請求されたカードによる、全体金額への貢献は約1%。
Download






![select age, q6[offset(1)], q6[offset(2)], q6[offset(3)], q6[offset(4)], q6[offset(5)]
from
(select age, approx_quantile(pay,6) q6 from T01 inner join PAY2016 using ( card_id )
group by age )
1/6 2/6 3/6 4/6 5/6](https://image.slidesharecdn.com/bigquery0517x-190402073253/85/BigQuery-2018-2-6-320.jpg)























![[Cloud OnAir] BigQuery の一般公開データセットを 利用した実践的データ分析 2019年3月28日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0328-190328095050-thumbnail.jpg?width=640&height=640&fit=bounds)























