Downloaded 44 times












































The document provides an introduction to Azure Data Lake, detailing its capabilities as an enterprise-wide repository for large-scale data storage and analytics. It covers ingestion methods for different data types, performance optimization, security features, and integration with Azure services like HDInsight and Power BI. Key components include U-SQL for data processing and Azure Data Lake Storage Gen2, emphasizing its advantages over traditional storage solutions.
Introductory details on Azure Data Lake and presentation agenda.
General overview of Azure Data Lake features and its importance.
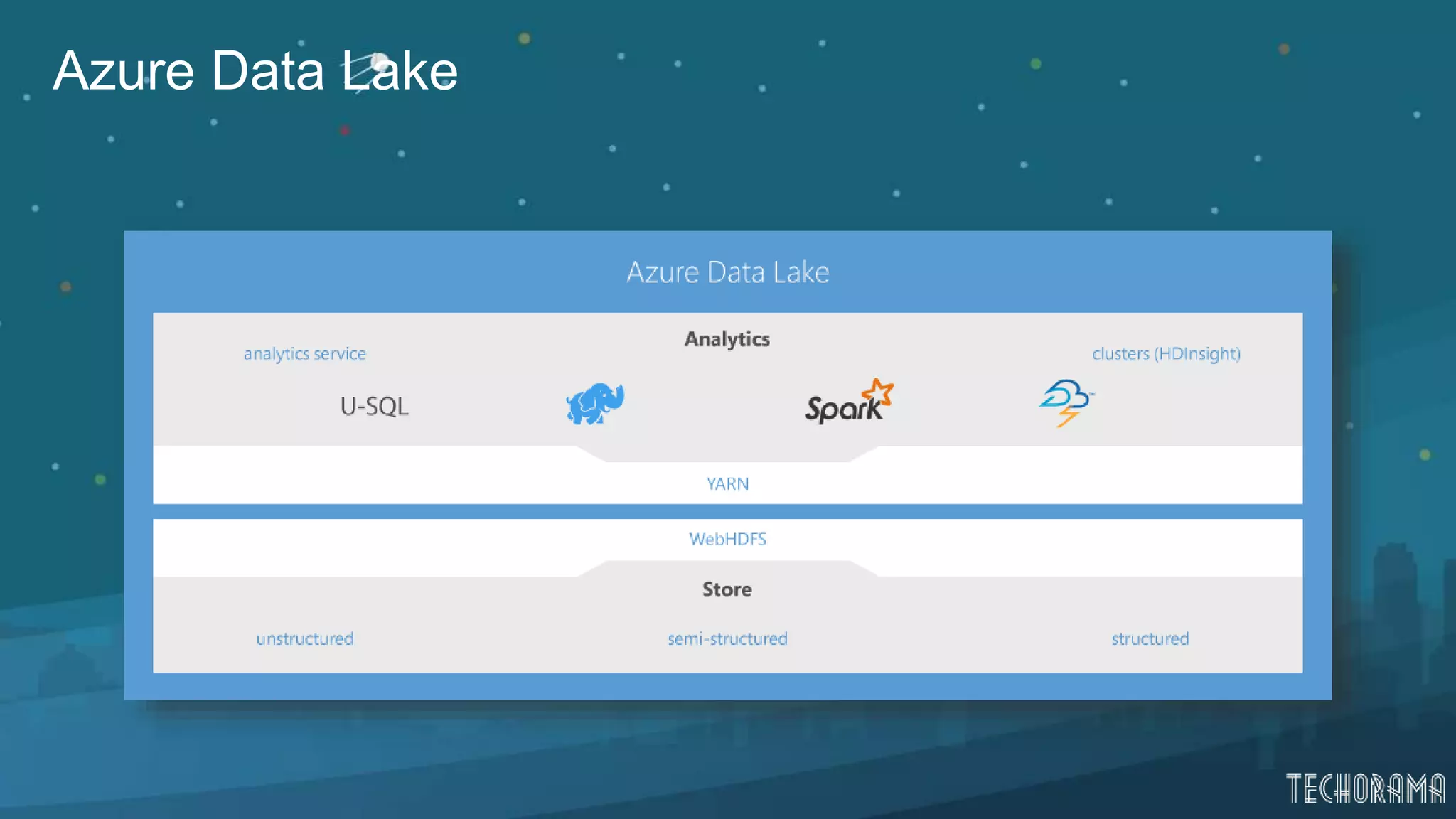
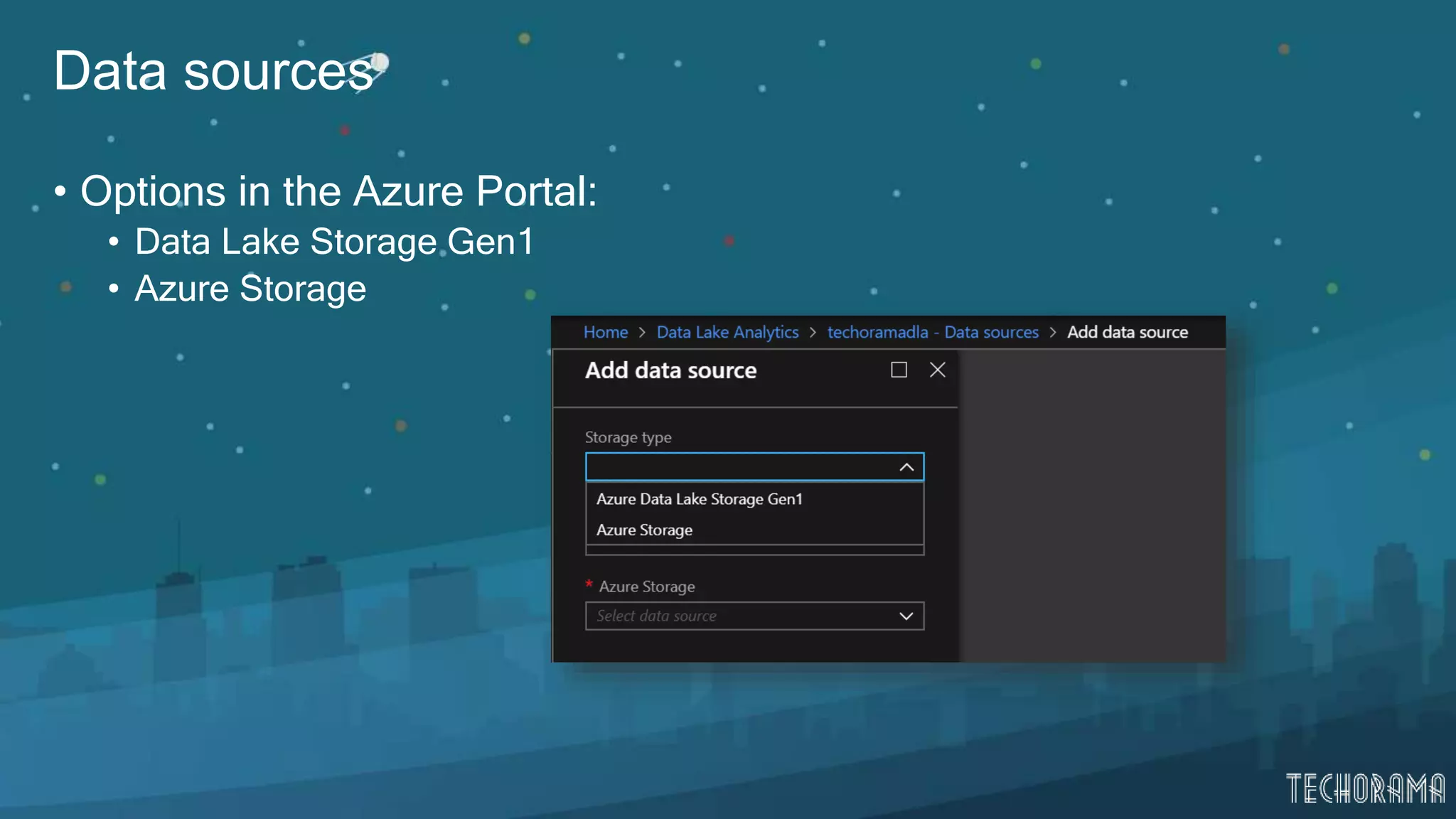
Description of Azure Data Lake Store, its capabilities, security, and compatibility.
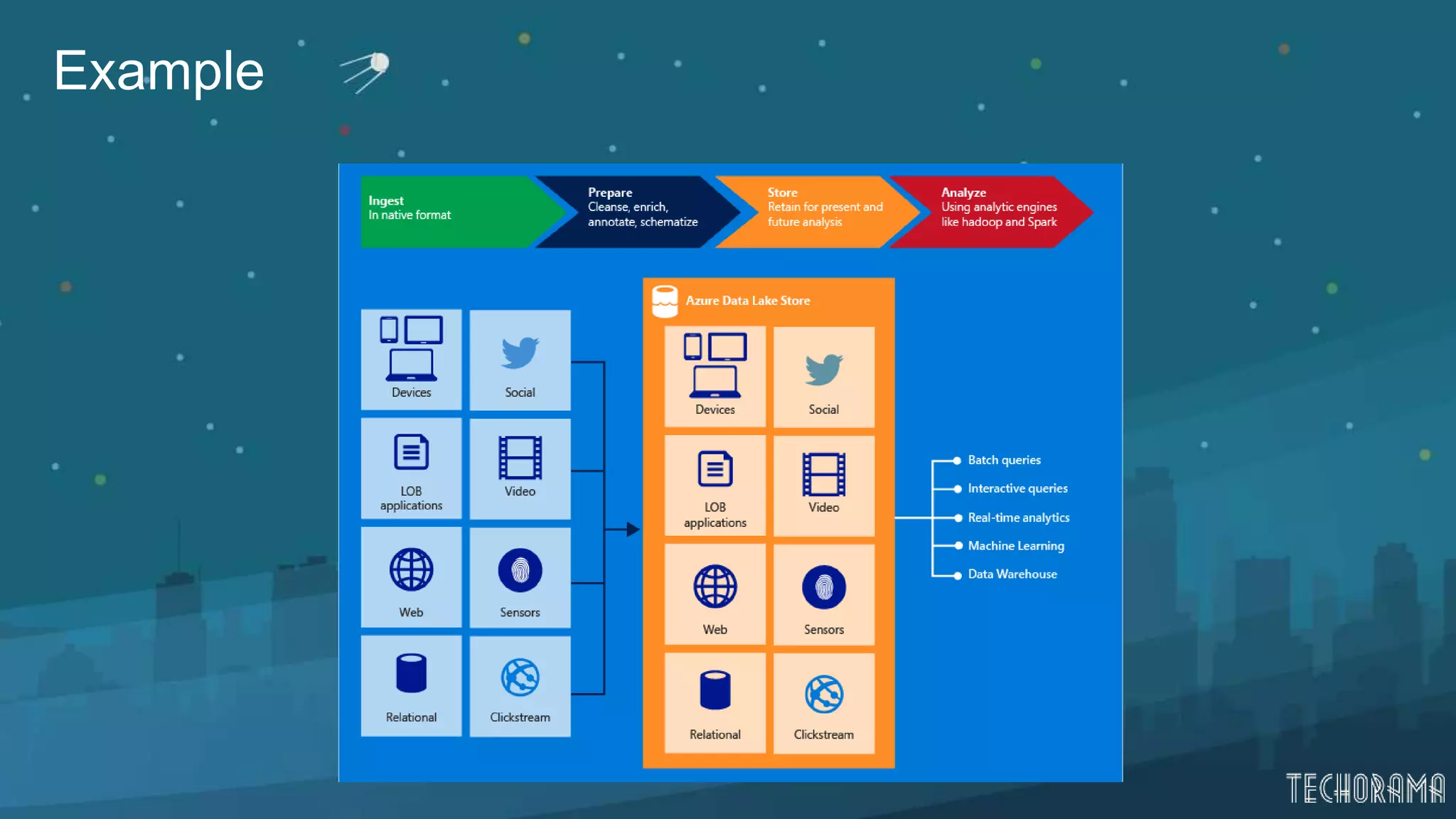
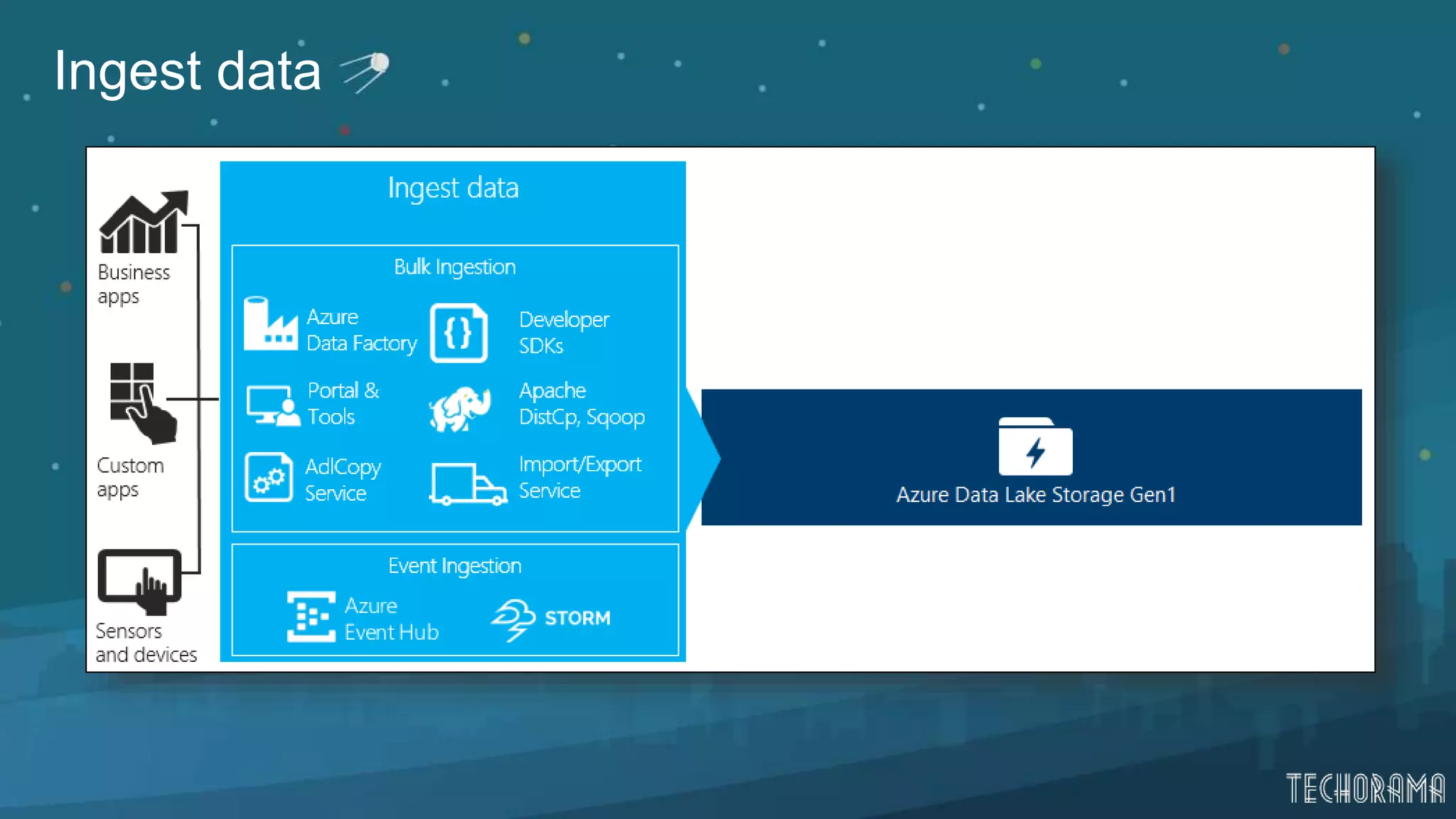
Various approaches for data ingestion including local, streamed, relational data, and large datasets.
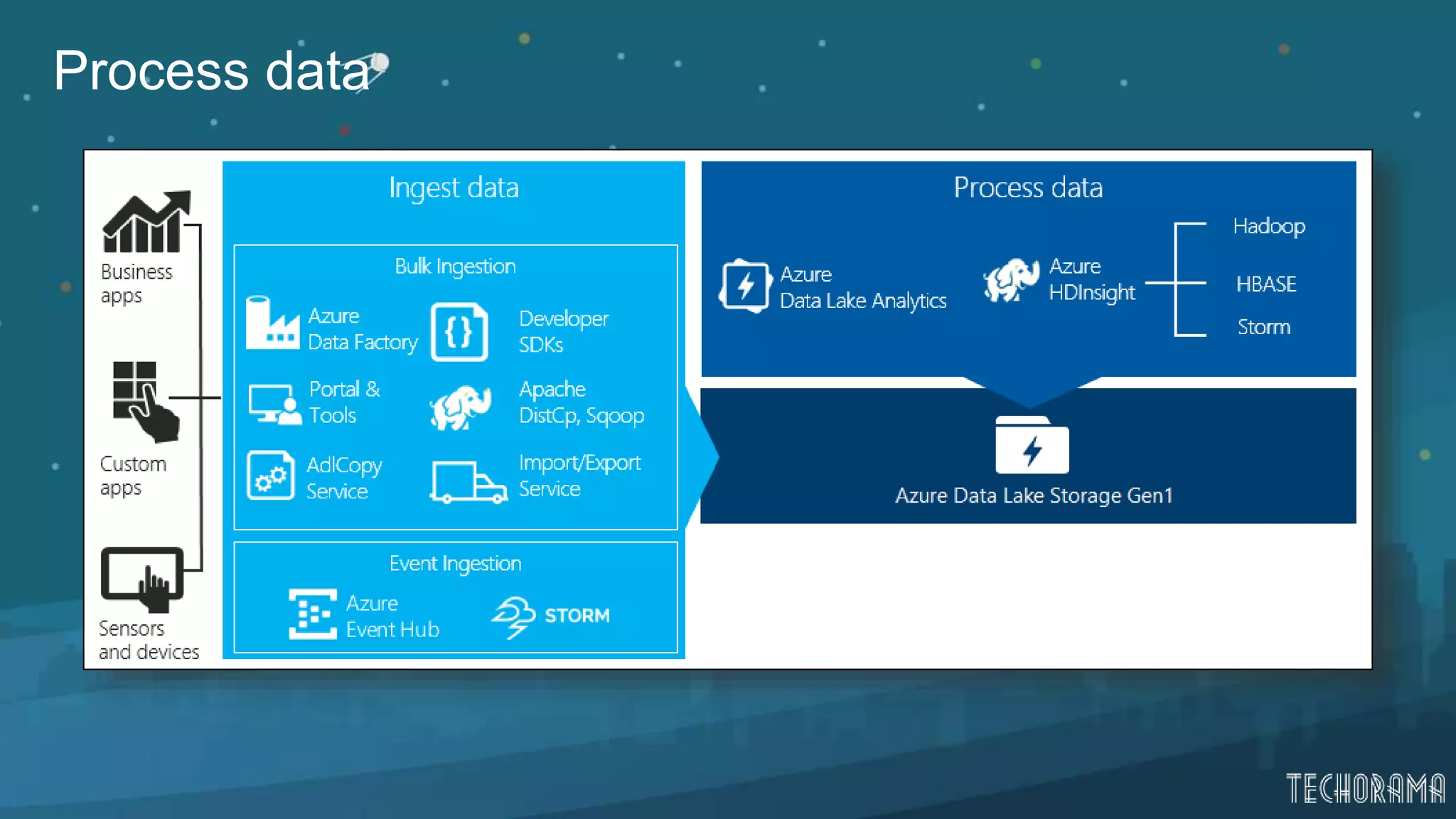
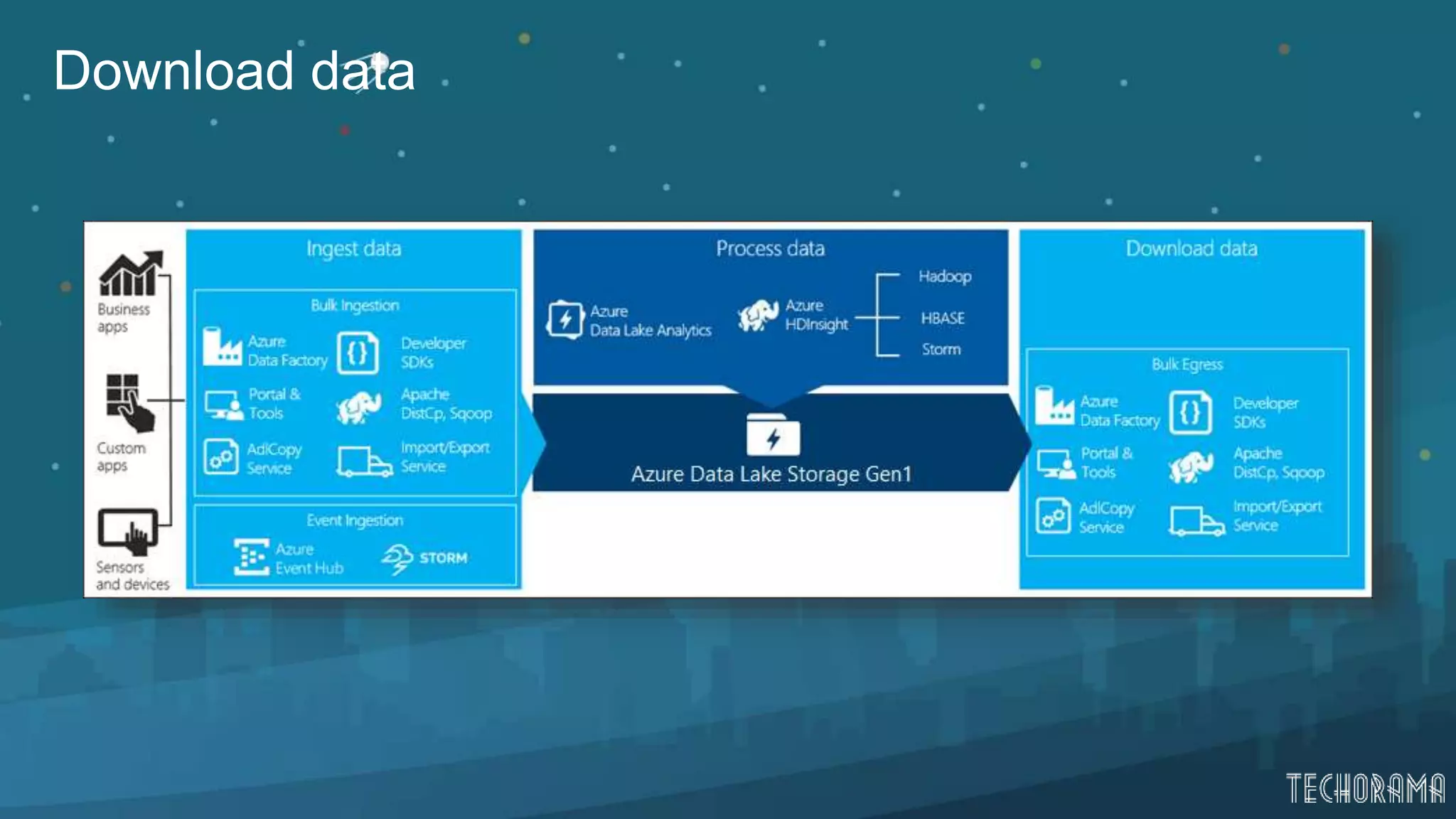
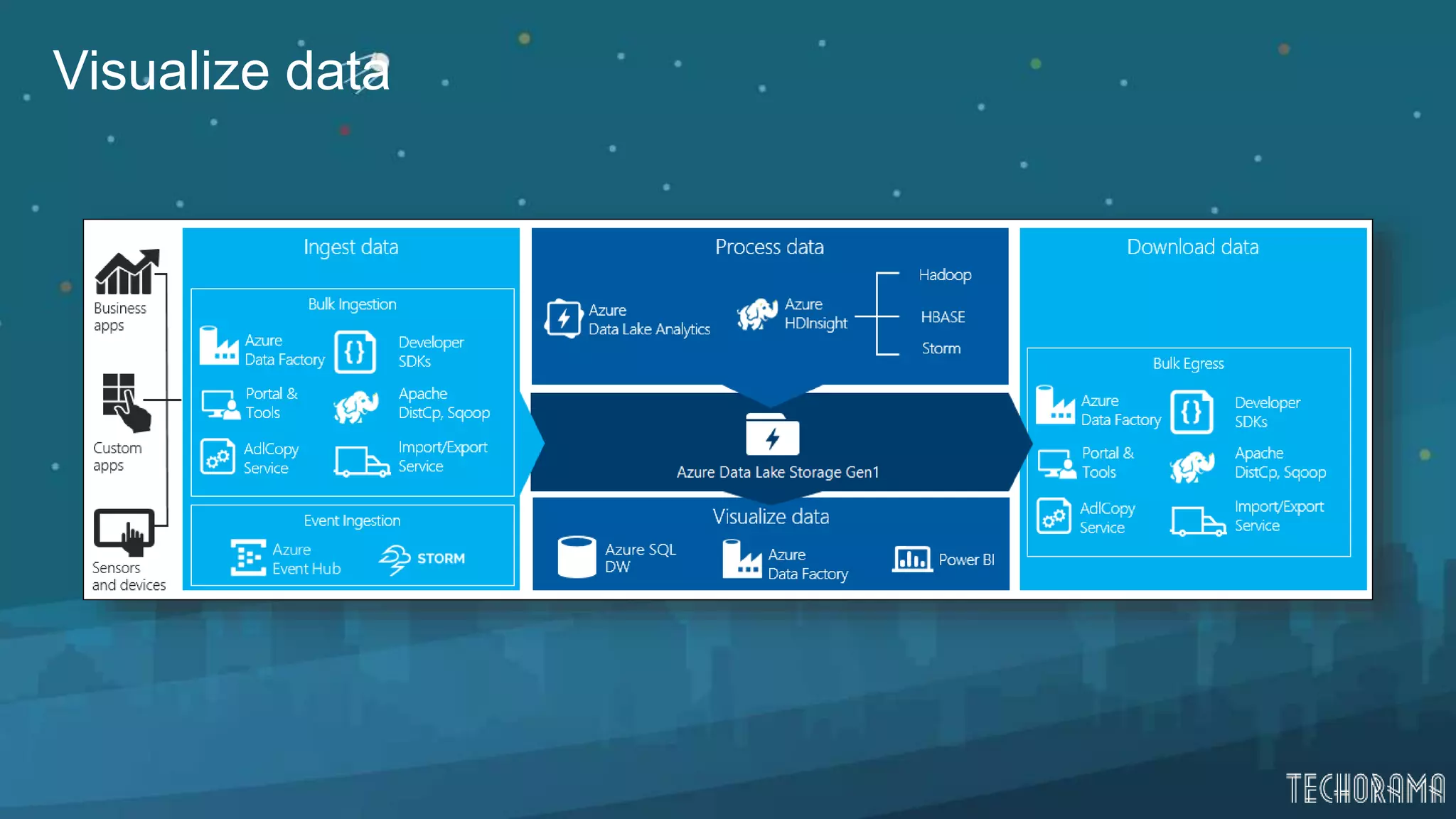
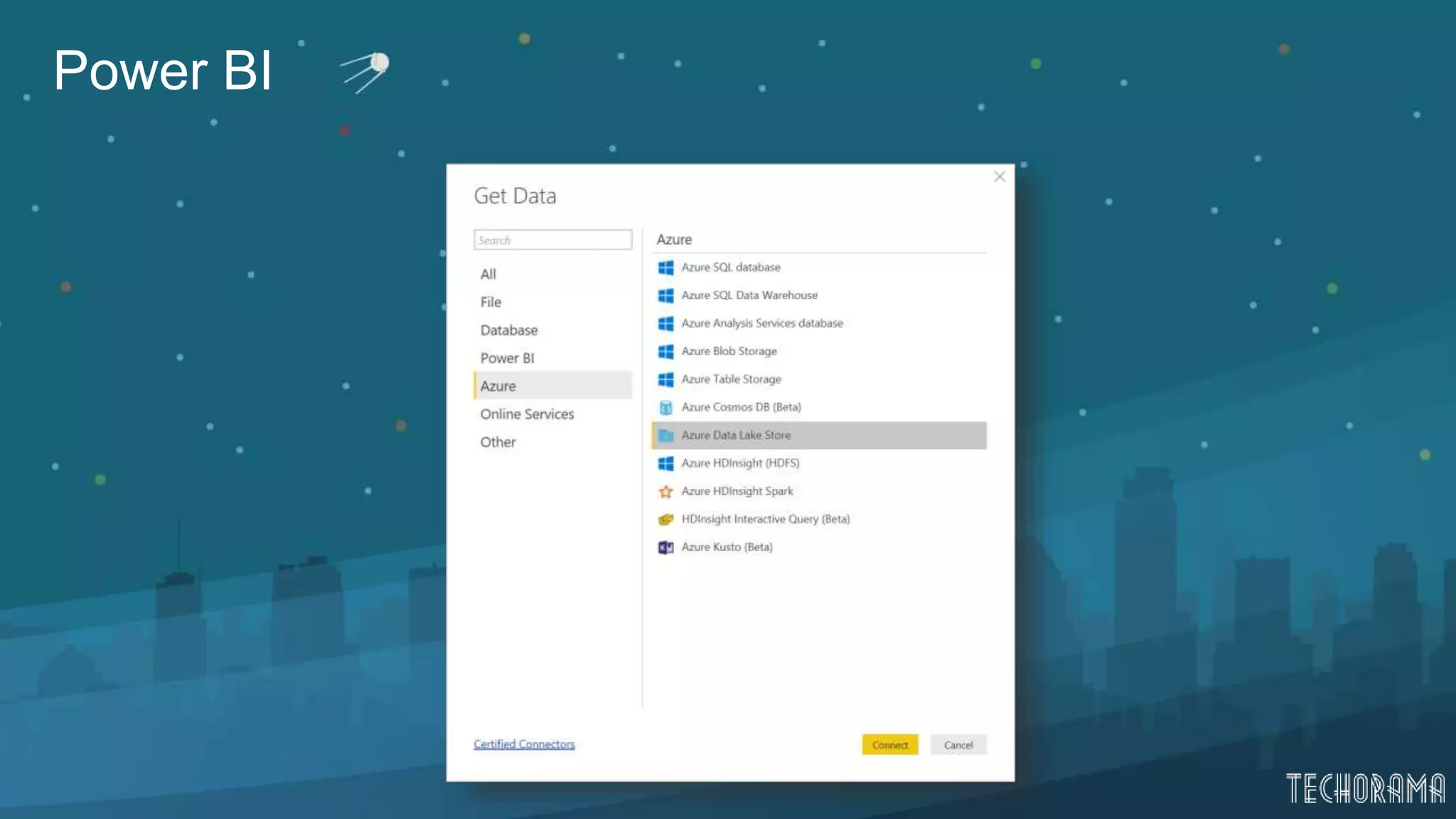
Overview of data processing, downloading, and visualizing data in Azure Data Lake.
Introduction of Storage Gen2 aimed at big data analytics, along with its advantages.
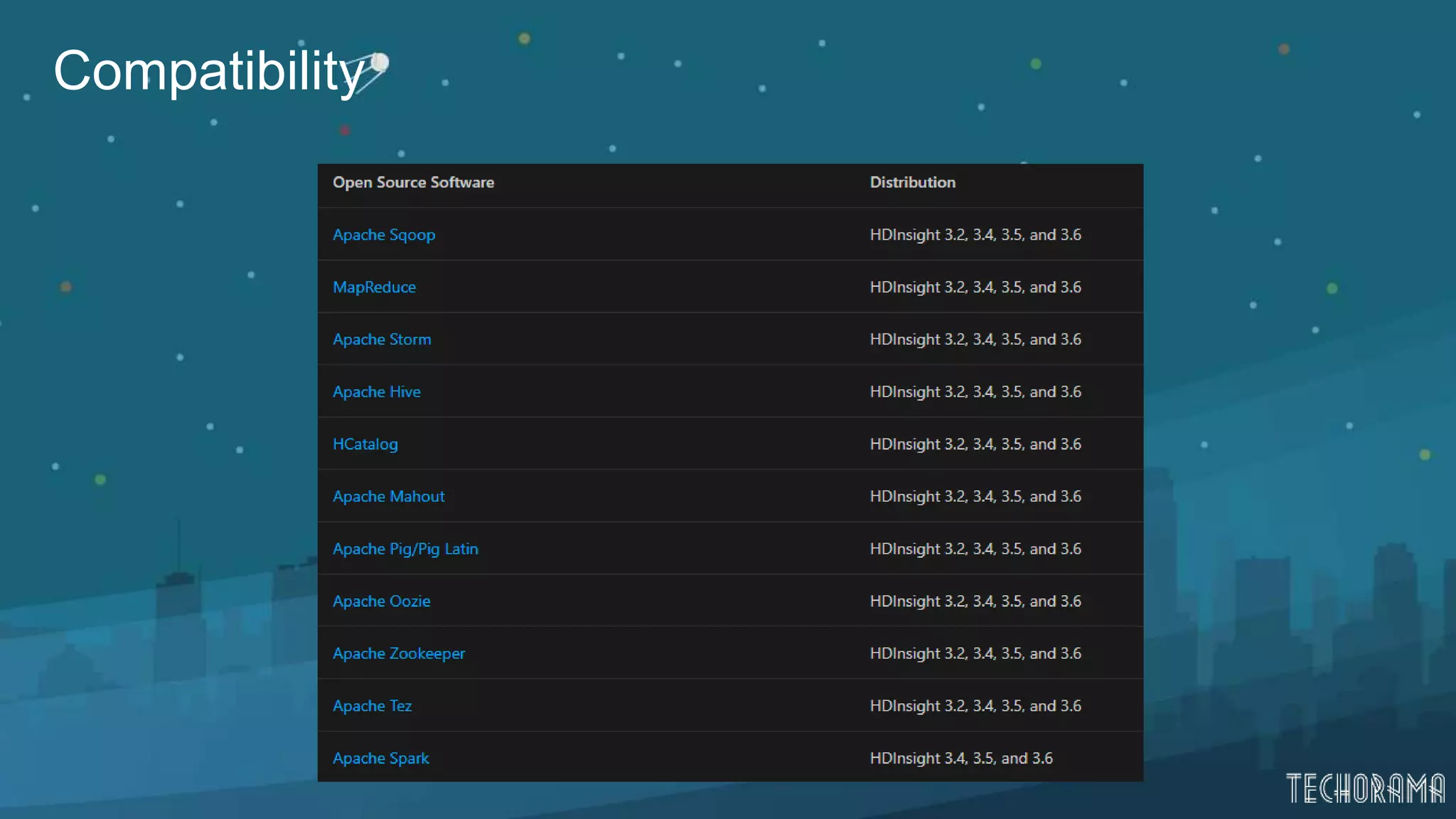
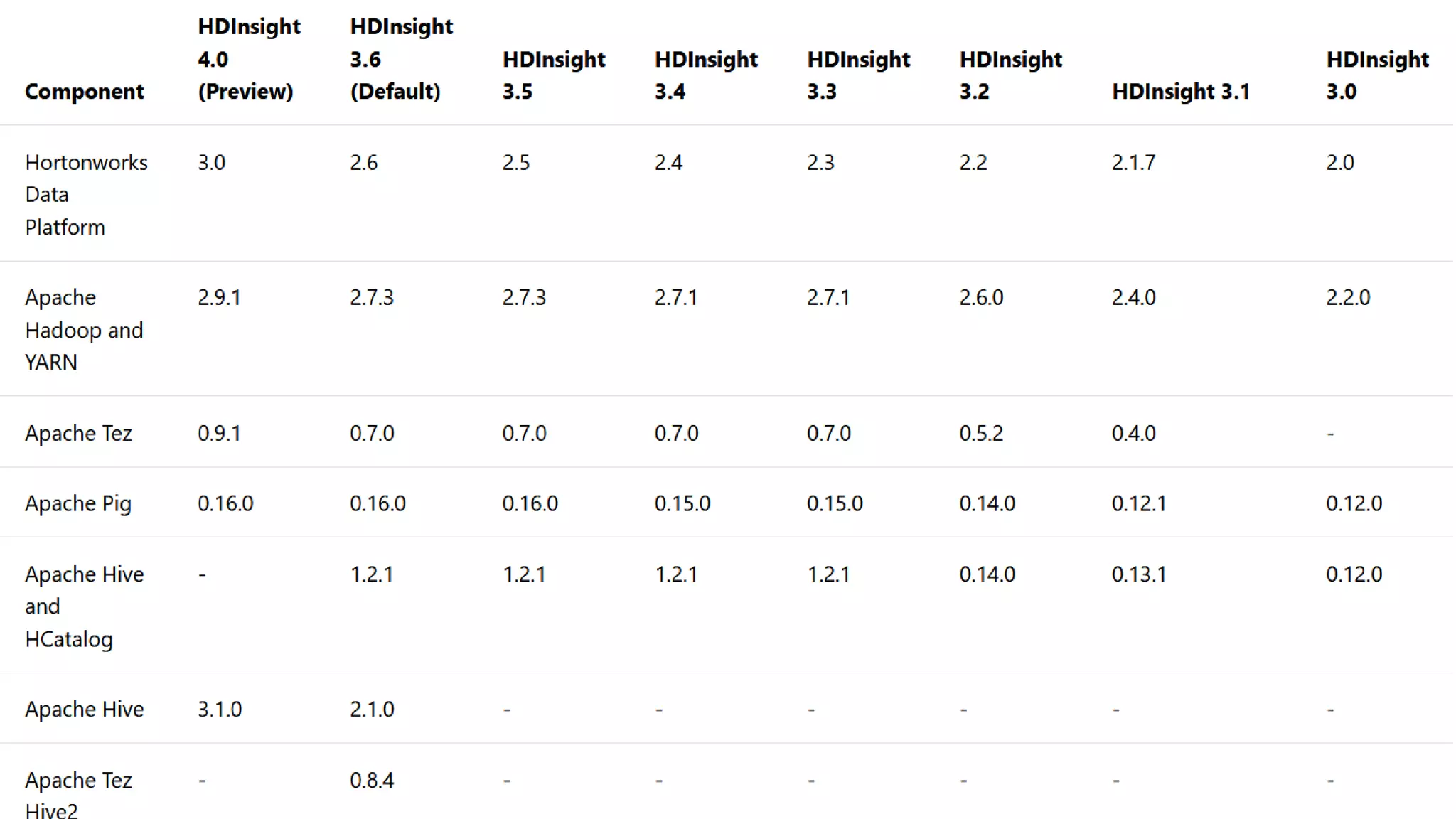
Details on HDInsight including cluster types and components for Hadoop ecosystem.
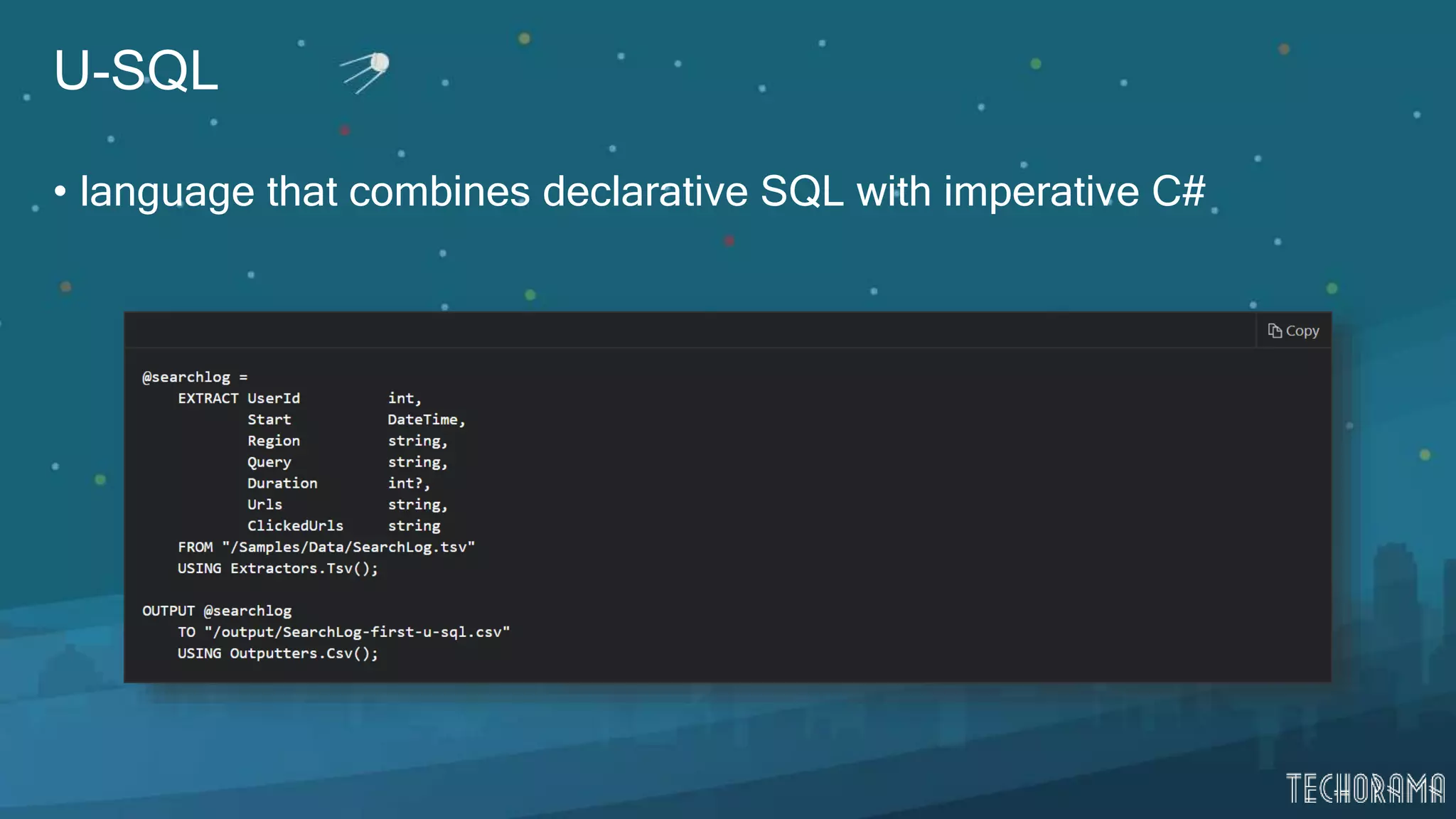
Description and features of Azure Data Lake Analytics, including U-SQL language.
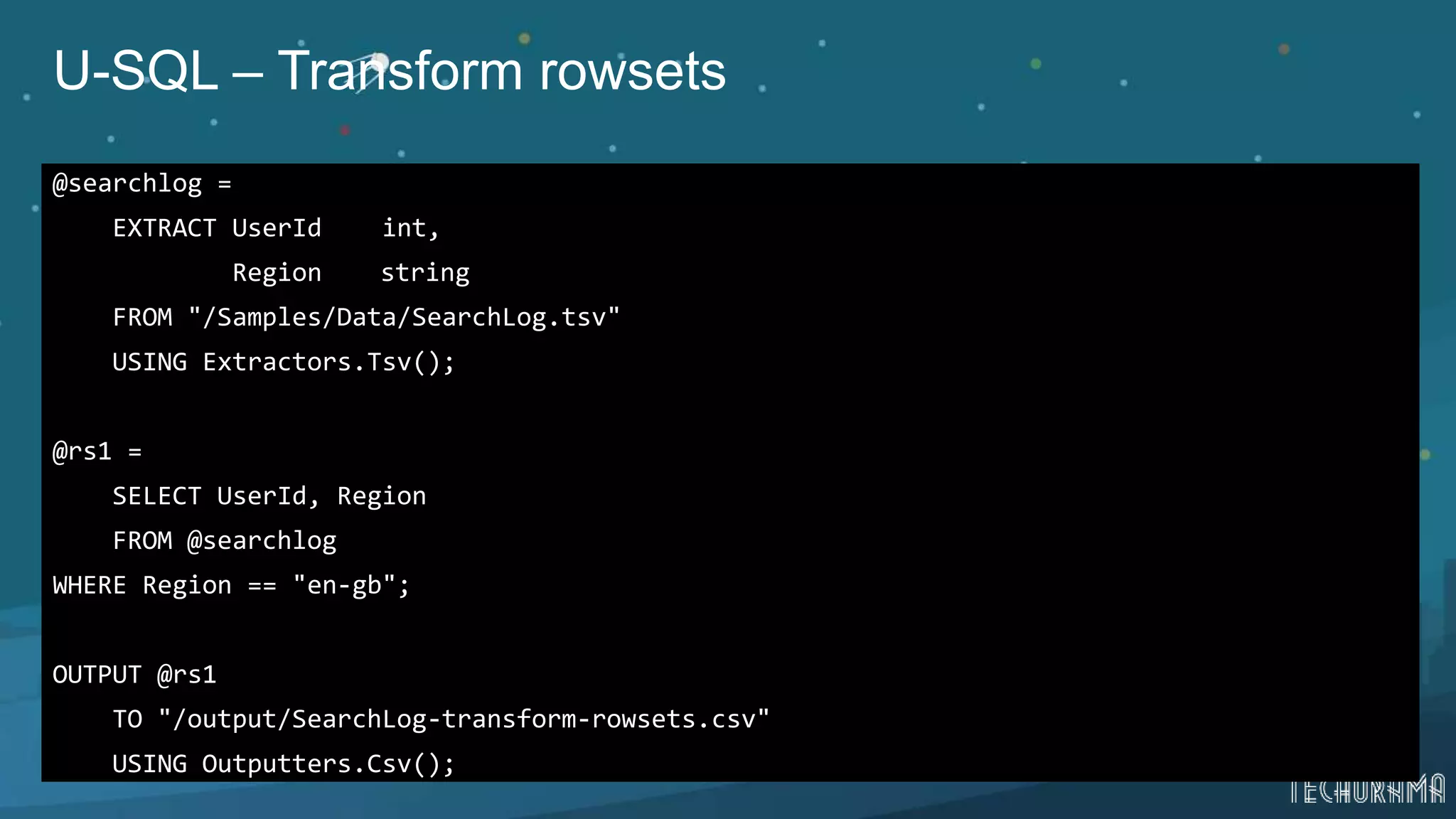
Insights into advanced U-SQL functionalities including extractor and output parameters.
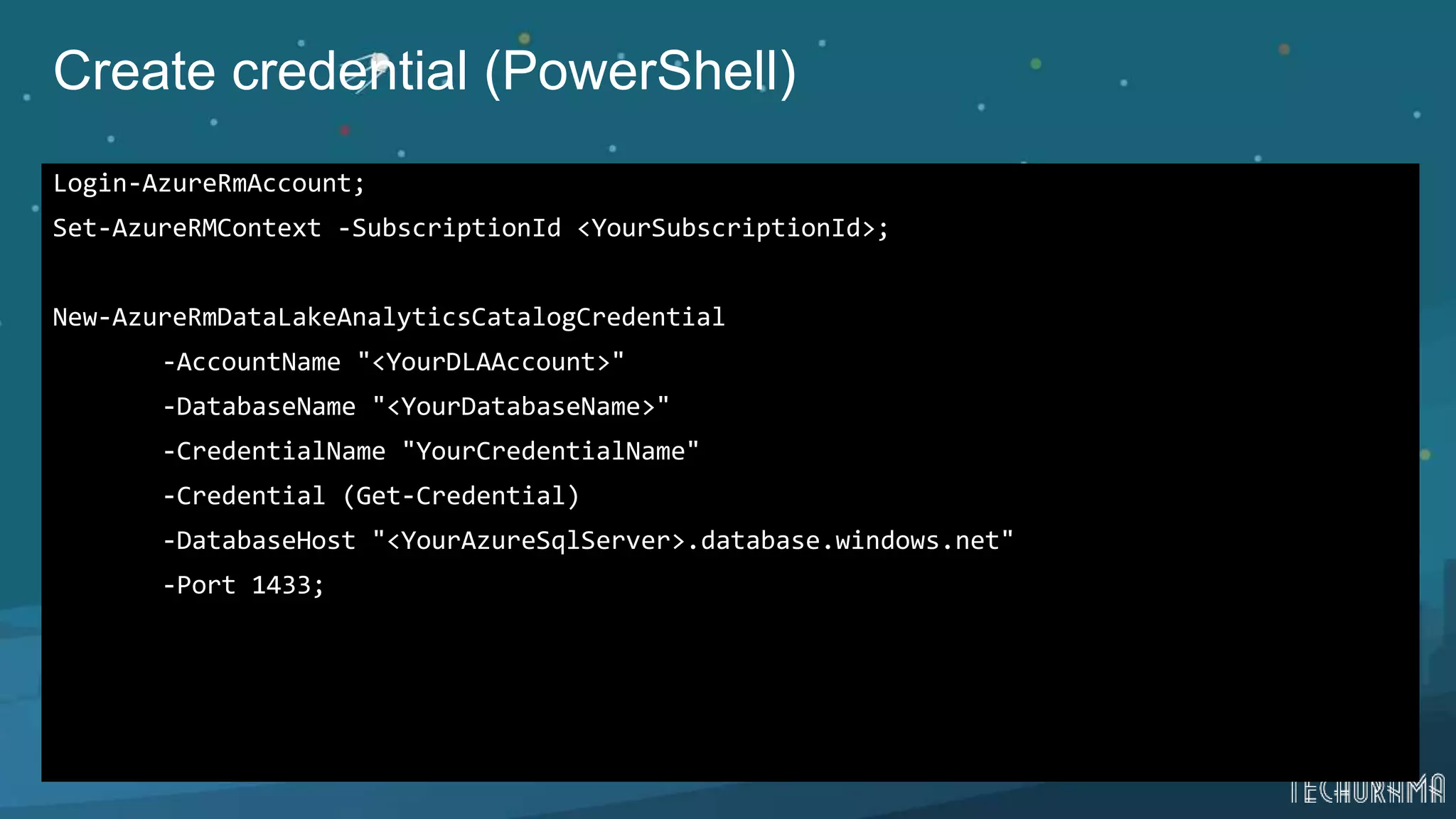
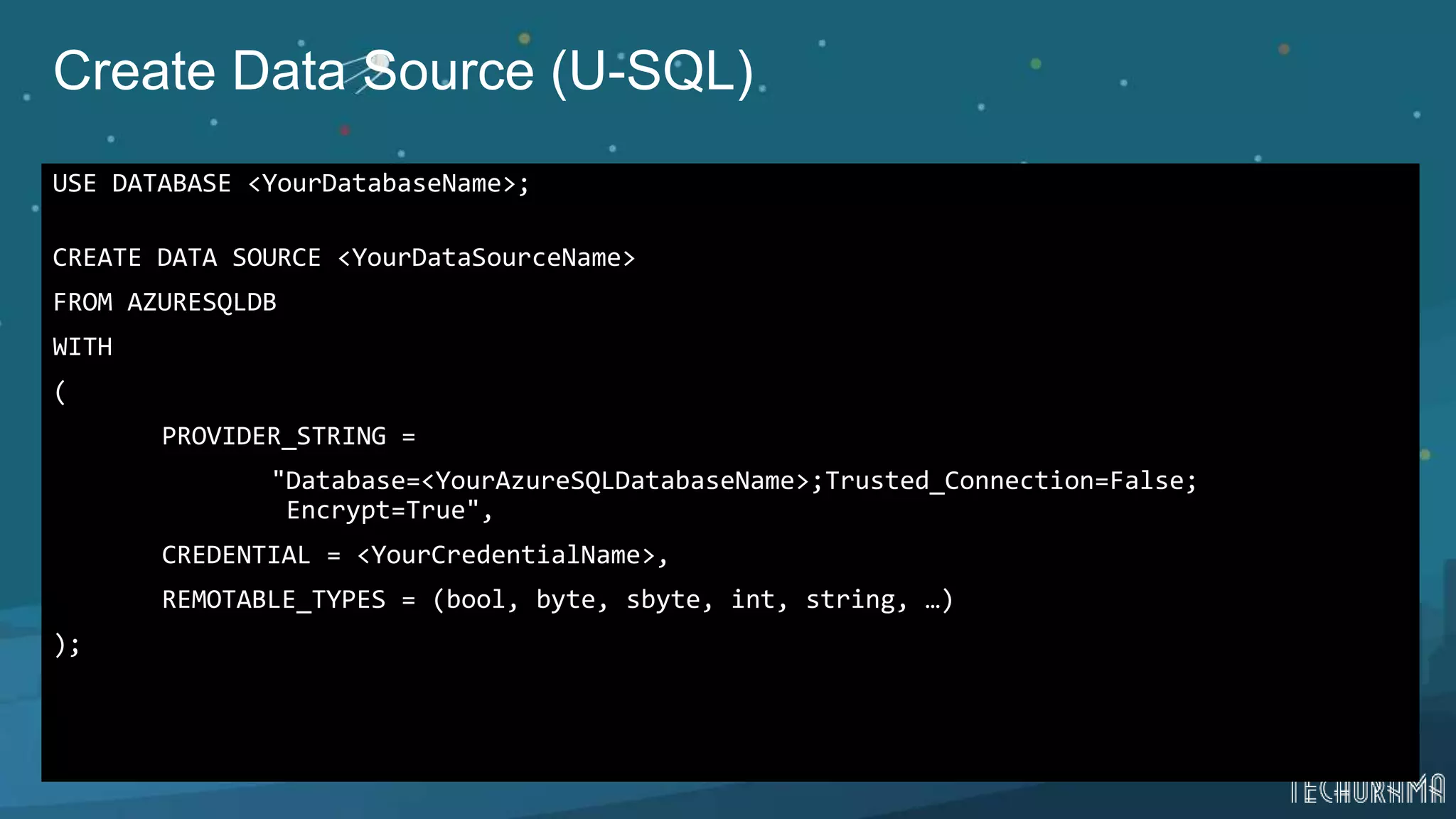
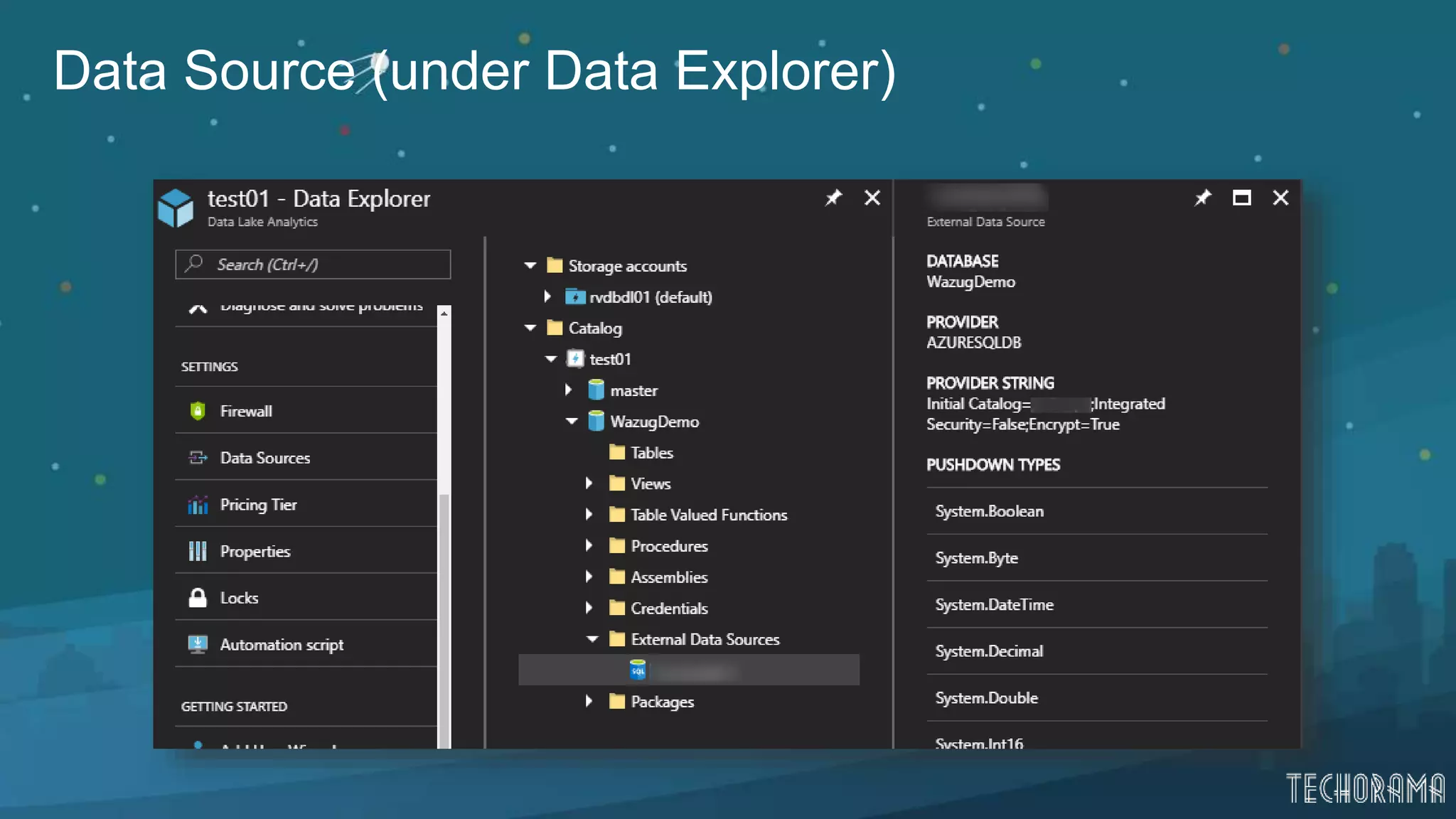
Instructions on using Azure SQL as a data source and querying data in Azure Data Lake.Final thoughts and resources for further learning about Azure Data Lake capabilities.





























































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

