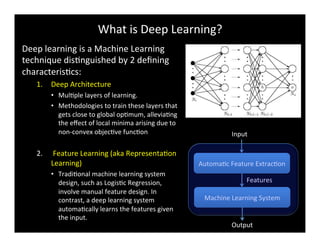
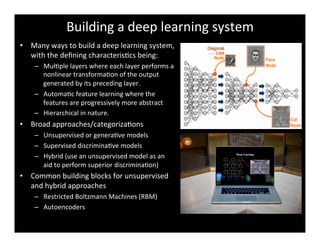
Deep learning is a machine learning approach characterized by deep architectures and automatic feature learning. It has garnered significant interest due to breakthroughs in areas such as speech and image recognition, and natural language processing. The document outlines the construction of a deep learning system using techniques like stacked autoencoders and layer-wise pretraining to enhance feature abstraction.

































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
