Downloaded 27 times




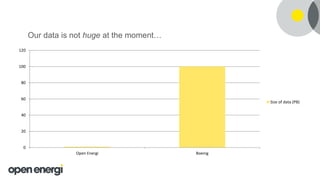
![• 25-40k messages processed per second
• Total size of data 500TB-800TB
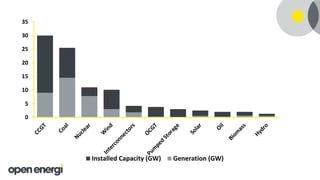
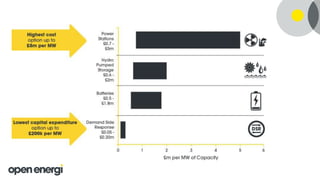
Open Energi in the coming year:
Perspective: here’s what “big data” means to Boeing [1]:
• ~64k messages per second from each aircraft
• Total size of data over 100 petabytes
[1]: http://bit.ly/18kQlMn](https://image.slidesharecdn.com/april131410openenergibironneau-160425200420/85/Powering-a-Virtual-Power-Station-with-Big-Data-9-320.jpg)
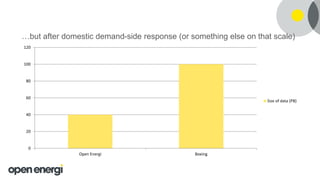

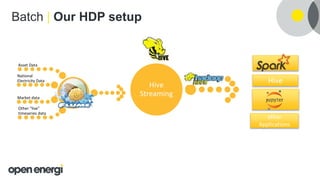
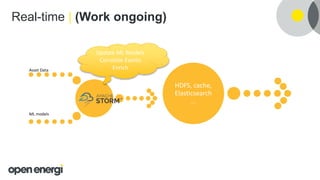


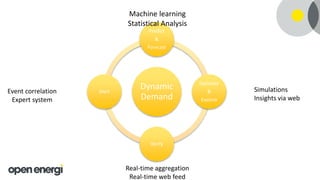
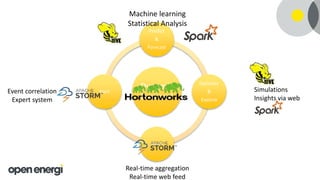

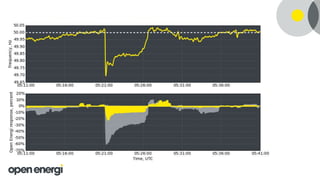
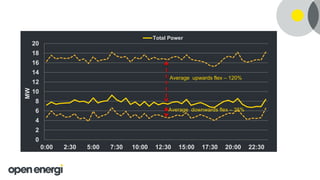
This document discusses how Open Energi is using big data and Hortonworks Data Platform (HDP) to power a virtual power station. Open Energi processes 25-40k messages per second containing 500TB-800TB of data from assets and markets. This is smaller than Boeing's 100PB of data from aircraft, but Open Energi's data volume is expected to grow significantly with demand-side response programs. HDP allows Open Energi to scale quickly, integrate multiple data sources using Apache Hive, reuse Python code for analytics, and gain insights through machine learning to predict demand, optimize systems, and more.



































































![Dell_whitepaper[1]](https://cdn.slidesharecdn.com/ss_thumbnails/98588d5b-7479-4930-9c9c-c3b85f2d0688-160619005556-thumbnail.jpg?width=640&height=640&fit=bounds)







































