Downloaded 58 times





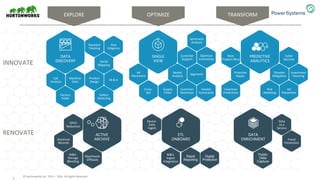

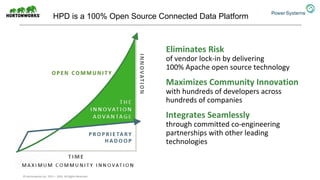


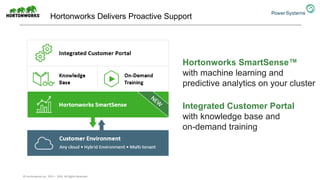

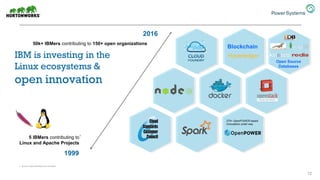
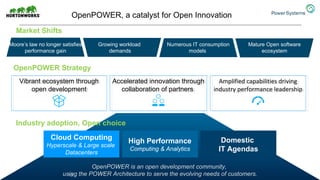
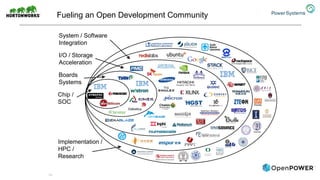
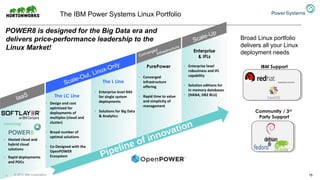

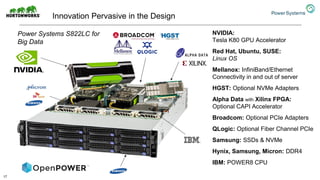

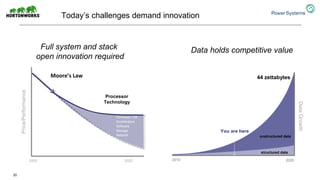
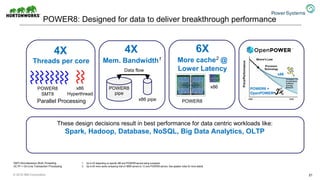
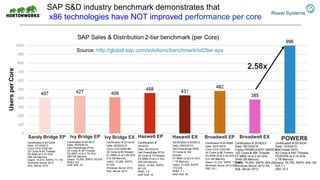
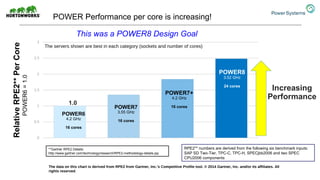
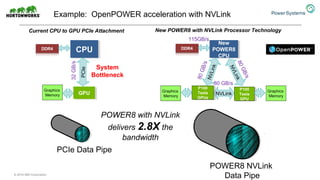

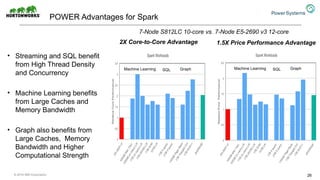


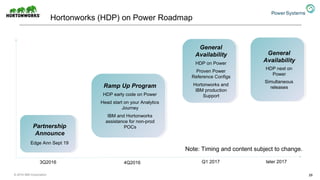


The document discusses the partnership between Hortonworks and IBM to provide the Hortonworks Data Platform (HDP) on IBM Power Systems, emphasizing its capabilities in big data processing and customer analytics. It highlights the advantages of the open-source technology and hardware solutions, such as reduced costs and improved performance in analytics and server management. Additionally, it showcases customer success stories, particularly in healthcare, demonstrating the operational benefits of adopting this flexible IT infrastructure.











































































































