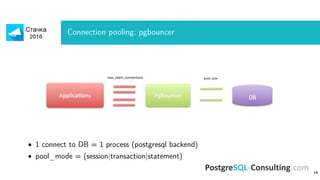
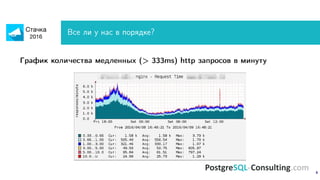
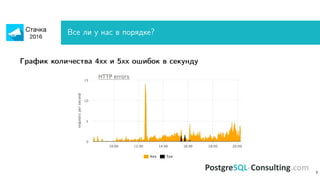
Документ обсуждает оптимизацию производительности PostgreSQL, акцентируя внимание на методах идентификации и устранения узких мест в системе. Описаны важные метрики, такие как время выполнения запросов и ошибки, а также предоставлены рекомендации по мониторингу и анализу запросов. Также рассмотрены технические аспекты настройки сервера и оптимизации запросов для повышения производительности.



![3
Типичный веб проект
[client]⇐⇒ [web server]⇐⇒ [application]⇐⇒ [database]](https://image.slidesharecdn.com/alexeyermakov-postgresqlperformancerecipes-160423100417/85/PostgreSQL-performance-recipes-3-320.jpg)








![14
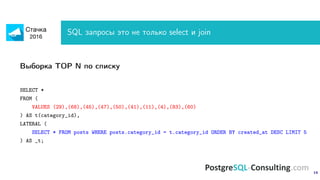
SQL запросы это не только select и join
• [recursive]CTE
• Window functions
• Lateral join
• DISTINCT ON
• EXISTS / NOT EXISTS
• generate_series()
• Arrays
• hstore/json/jsonb
• COPY
• Materialized views
• Unlogged tables
• pl/* functions
Нет времени объяснять, надо использовать!](https://image.slidesharecdn.com/alexeyermakov-postgresqlperformancerecipes-160423100417/85/PostgreSQL-performance-recipes-14-320.jpg)