Download to read offline








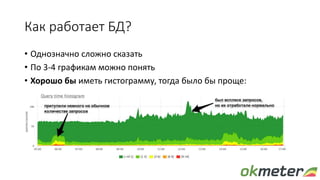
![Смотрим по pg_stat_statements
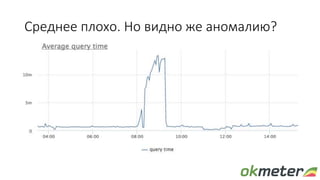
• Время выполнения запроса обычно ~1ms, получить полную картину
периодическими запросами в pg_stat_activity нереально
• По pg_stat_statements мы к сожалению не можем посчитать
гистограмму, придется смотреть на среднее
[rate(total_time)/rate(calls)]
• Для общей картины смотрим на суммарное среднее:
[sum(rate(total_time))/sum(rate(calls))]](https://image.slidesharecdn.com/pgconf2017-170317122525/85/postgresql-9-320.jpg)

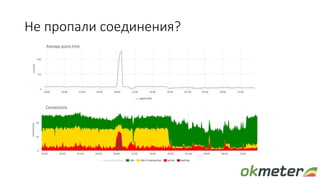
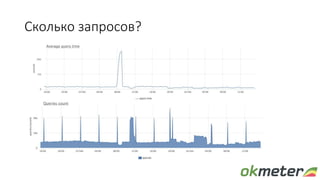








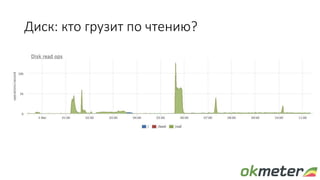
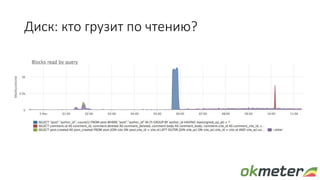
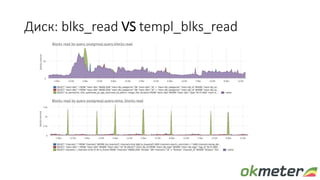



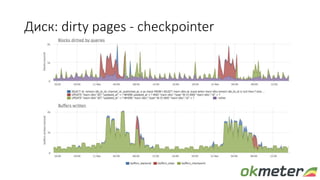
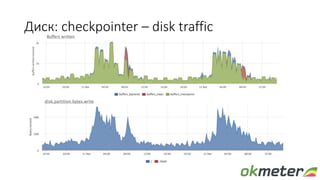


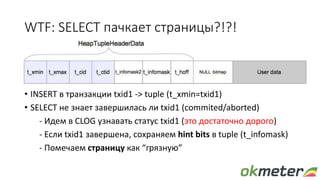






Документ обсуждает диагностику PostgreSQL с точки зрения системного администрирования, подчеркивая важность понимания работы базы данных для обеспечения надежности и производительности. Рассматриваются различные аспекты мониторинга, включая время выполнения запросов, использование ресурсов и сложности, связанные с блокировками и чтением/записью на диск. Автор обращает внимание на необходимость осознания физических метрик и аномалий для более глубокого понимания работы PostgreSQL.


































































