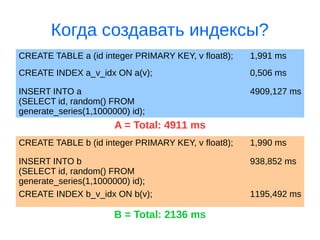
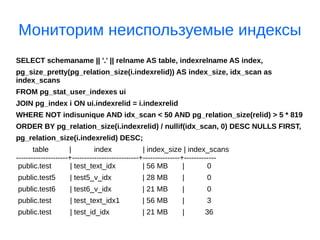
Документ рассматривает оптимизацию запросов в PostgreSQL, включая использование команды EXPLAIN, индексов и техники нормализации баз данных. Объясняются преимущества и недостатки ORM и SQL, а также важные аспекты проектирования структур баз данных. Приведены примеры эффективных запросов и деталей работы системы, таких как VACUUM и анализ индексов.




![ORM vs SQl
●
ORM — удобно?
●
ORM — быстро?
Total runtime: (~)117.092 ms*
JAVA
@ManyToOne
@JoinColumn(name = "CATEGORY_ID")
public Category getCategory() {
return category;
}
PHP
$customers = Customer::find()
->where(['status' => TRUE])
->orderBy('id')
->limit(100, 10000);
* Подробный пример мы разберем ниже
☑](https://image.slidesharecdn.com/gw2016-04-151pgsqloptimization-160703215357/85/PostgreSQL-4-320.jpg)













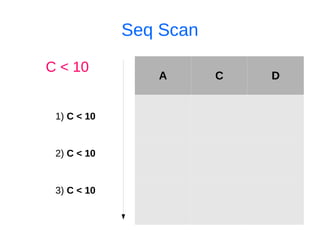
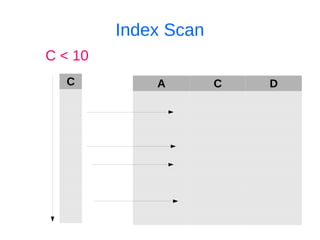




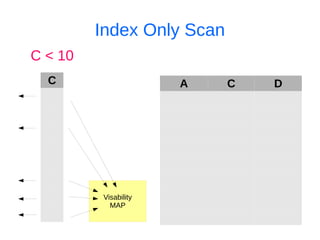


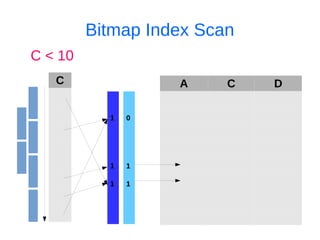



![Ищем дубликаты индексов
lk=> SELECT pg_size_pretty(SUM(pg_relation_size(idx))::BIGINT) AS SIZE,
(array_agg(idx))[1] AS idx1, (array_agg(idx))[2] AS idx2,
(array_agg(idx))[3] AS idx3, (array_agg(idx))[4] AS idx4
FROM ( SELECT indexrelid::regclass AS idx,
(indrelid::text ||E'n'|| indclass::text ||E'n'|| indkey::text ||E'n'||
COALESCE(indexprs::text,'')||E'n' || COALESCE(indpred::text,'')) AS KEY
FROM pg_index) sub
GROUP BY KEY HAVING COUNT(*)>1
ORDER BY SUM(pg_relation_size(idx)) DESC;
size | idx1 | idx2 | idx3 | idx4
---------+-----------------------+----------------------+------+------
32 kB | blocks_id_idx | blocks_id_idx1 | |
32 kB | blocks_type_idx1 | blocks_type_idx | |
32 kB | primary_key | ids | |](https://image.slidesharecdn.com/gw2016-04-151pgsqloptimization-160703215357/85/PostgreSQL-33-320.jpg)






![Данные в JSON ARRAY
=> SELECT
array_to_json( array_agg( row_to_json(tasks) ) )
FROM tasks;
[
{ "id":1, "type":"refill_cache", "status":"new",
"params":"{"threads":-1}", "output":"",
"exception":"" },
{ "id":2, "type":"refill_cache", "status":"new",
"params":"{"threads":-1}", "output":"",
"exception":"" }
]](https://image.slidesharecdn.com/gw2016-04-151pgsqloptimization-160703215357/85/PostgreSQL-40-320.jpg)
![OUTPUT to FILE
=> o tasks.json
=> SELECT array_to_json( array_agg( row_to_json(tasks) ) )
FROM tasks;
=> o
# cat tasks.json
array_to_json
-------------------------------------------------------------------------------
[{"id":1,"type":"refill_cache","status":"new","params":"{"thread
s":-1}","output":"","exception":""},
{"id":2,"type":"refill_cache","status":"new","params":"{"thread
s":-1}","output":"","exception":""}]](https://image.slidesharecdn.com/gw2016-04-151pgsqloptimization-160703215357/85/PostgreSQL-41-320.jpg)

















![[JAM 1.1] Clean Code (Paul Malikov)](https://cdn.slidesharecdn.com/ss_thumbnails/jam-mar5-2011-clean-code-lowquality-110307033110-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























