Download as PDF, PPTX













![Обработка запроса
update t
set y = y + 1 where x = 1
BACKEND
PARSER
PLANNER
EXECUTER
user=# d+ t
Table "user.t"
Column | Type
--------+---------+
x | integer |
y | integer |
Indexes:
"t_pkey" PRIMARY KEY, btree (x)
-[ RECORD 1 ]-------+---------
relid | 24639
schemaname | user
relname | t
seq_scan | 1
seq_tup_read | 0
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 0
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 0
n_dead_tup | 0
n_mod_since_analyze | 0
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0
-[ RECORD 1 ]-+-------
relid | 24639
indexrelid | 24642
schemaname | user
relname | t
indexrelname | t_pkey
idx_scan | 0
idx_tup_read | 0
idx_tup_fetch | 0
| t_xmin | t_xmax | x | y |
---------+---------+---+---+
| 1 | 2 | 1 | 1 |
---------+---------+---+---+
| 2 | 0 | 1 | 2 |
---------+---------+---+---+
Update on t
-> Index Scan using t_pkey on t
-> Index Cond: (x = 1)](https://image.slidesharecdn.com/postgresql-160424181046/85/PostgreSQL-13-320.jpg)
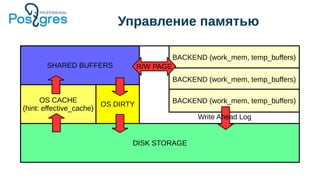
![Оптимальный размер Shared Buffers
pg_buffercache
-[ RECORD 1 ]----+------
bufferid | 331
relfilenode | 2654
reltablespace | 1663
reldatabase | 16432
relforknumber | 0
relblocknumber | 1
isdirty | f
usagecount | 5
pinning_backends | 0
● зависит от вашего железа
● зависит от типа нагрузки
● использовать pg_buffercache в бою
нельзя
● мы сделали правильную версию,
скоро будет](https://image.slidesharecdn.com/postgresql-160424181046/85/PostgreSQL-15-320.jpg)

![Vacuum
-[ RECORD 1 ]----+-------------------------
datid | 16384
datname | database
pid | 10190
usesysid | 16431
usename | user
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2016-04-22 22:47:50
xact_start |
query_start | 2016-04-22 22:48:12
state_change | 2016-04-22 22:48:12
waiting | f
state | idle
backend_xid | 4
backend_xmin | 4
query | update t set y = y + 1
+--------+---------+---+---+
| t_xmin | t_xmax | x | y |
---------+---------+---+---+
| 1 | 2 | 1 | 1 |
---------+---------+---+---+
| 2 | 0 | 1 | 2 |
+--------+---------+---+---+
| 3 | 5 | 2 | 4 |
+--------+---------+---+---+](https://image.slidesharecdn.com/postgresql-160424181046/85/PostgreSQL-18-320.jpg)
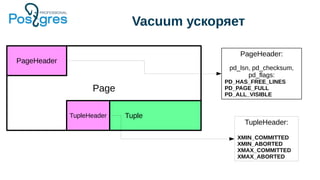









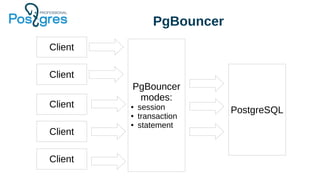
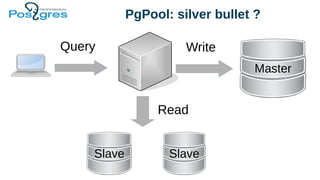
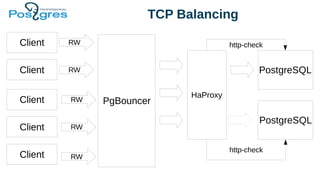
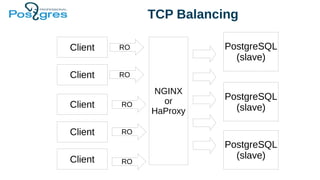



Доклад посвящен эксплуатационным аспектам PostgreSQL, включая отказоустойчивость, производительность и балансировку нагрузки. В нем рассматриваются инструменты для обеспечения целостности данных, такие как pg_dump, репликация и резервное копирование, а также стратегии управления памятью и выполнение запросов. Также обсуждаются методы балансировки клиентских запросов с использованием таких решений, как pgbouncer и pgpool.















































