Download as PDF, PPTX




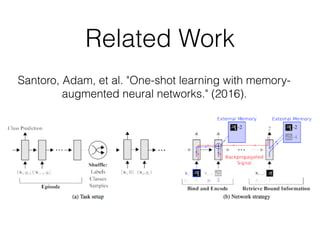
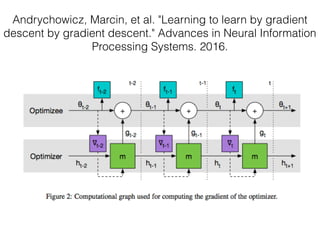
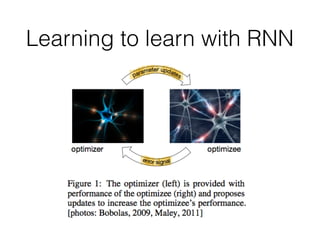


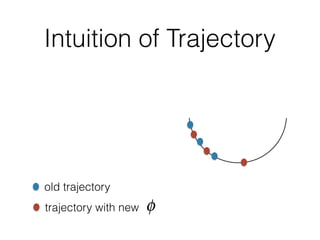
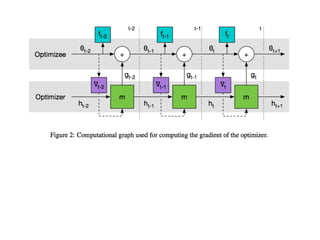

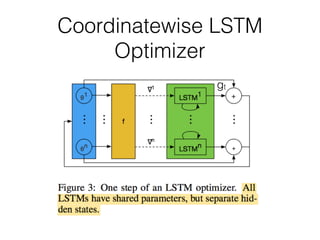




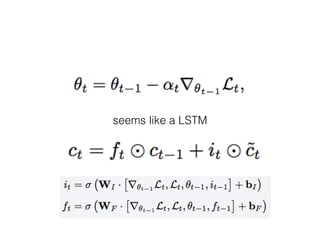
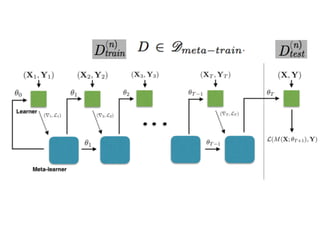





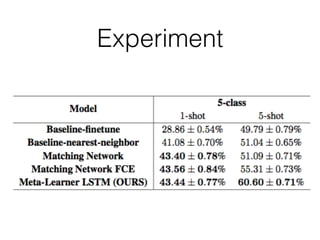
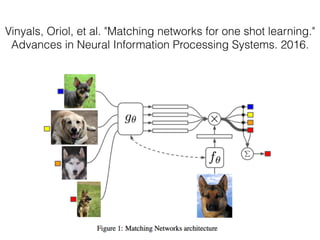
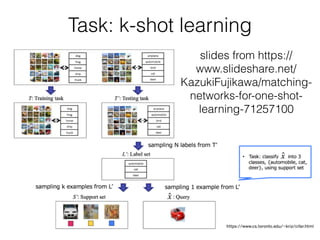
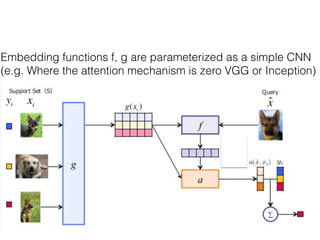
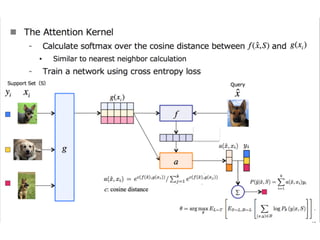
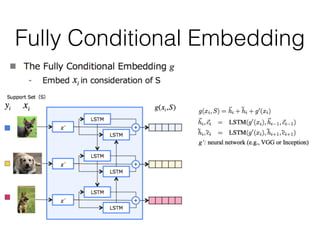
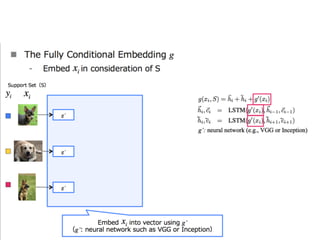
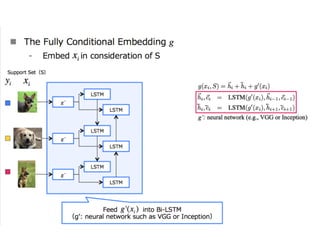
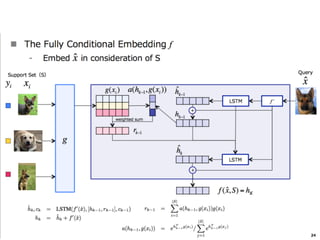
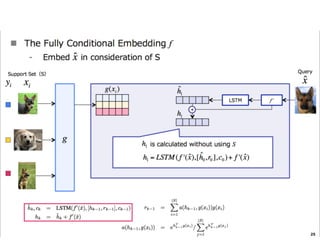
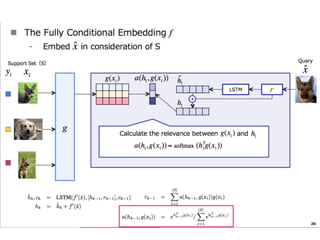
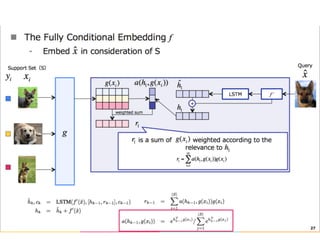
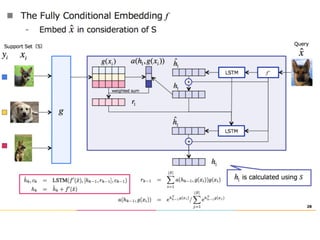
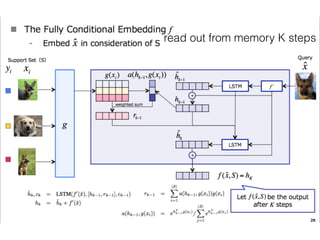



The document discusses few-shot learning and the challenges faced by gradient-based optimization techniques in this context. It proposes a learned update rule using a Long Short-Term Memory (LSTM) model as an optimizer for enhancing learning from small datasets. Experiments conducted on the Mini-ImageNet dataset demonstrate the effectiveness of this meta-learning approach in adapting optimization strategies for different tasks.





























![[DL Hacks]Meta-Learning LT](https://cdn.slidesharecdn.com/ss_thumbnails/meta-learning-181226041942-thumbnail.jpg?width=640&height=640&fit=bounds)










































