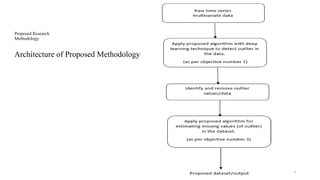
This document presents a research proposal by Swati Jain on unsupervised anomaly detection using deep learning techniques applied to multivariate time series stock data, aiming for a Ph.D. in computer science and engineering. The study focuses on developing an anomaly detection model utilizing methods like LSTM and autoencoders while addressing challenges in outlier detection, particularly in stock data. The proposal outlines objectives, methodologies, implementation plans, and the current status of the research, which includes ongoing data analysis and preparation for publications.