Download to read offline



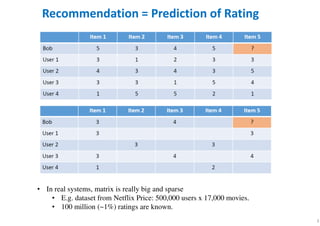
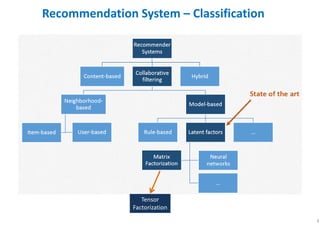
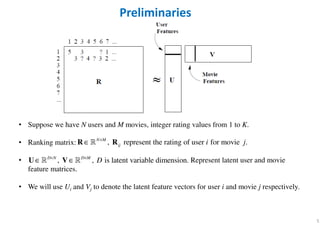

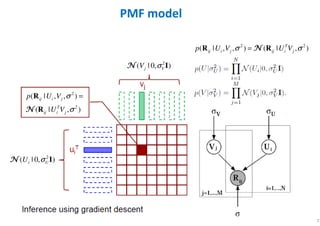
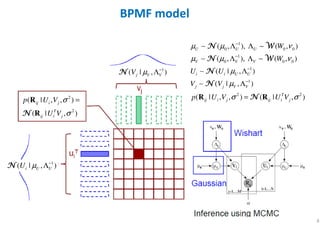



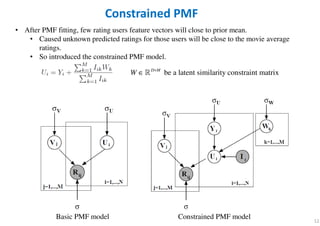


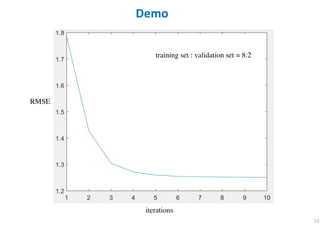
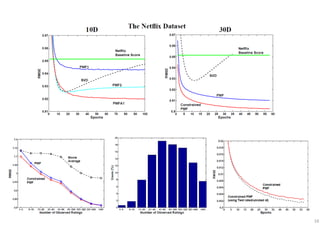





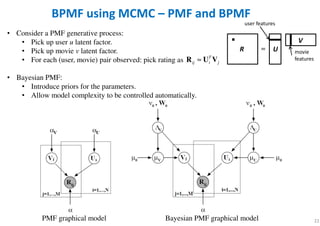






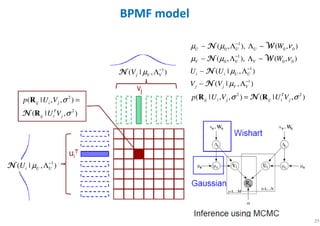
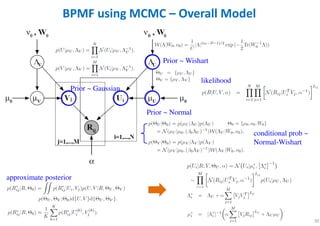

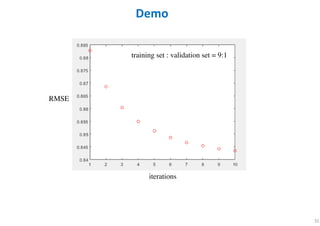
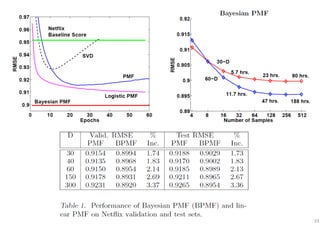


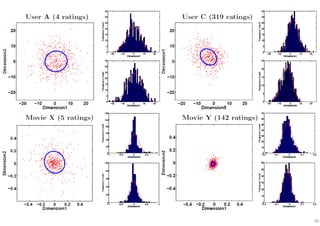
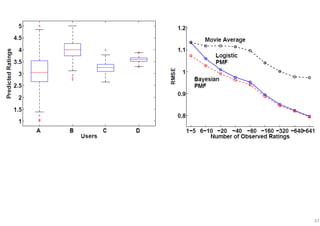


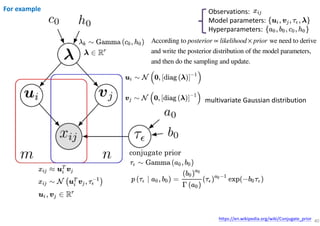
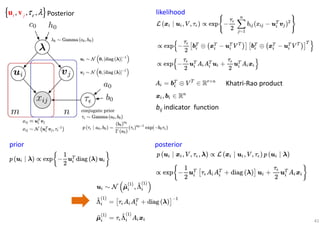
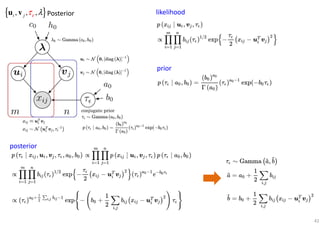
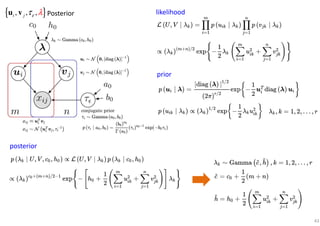
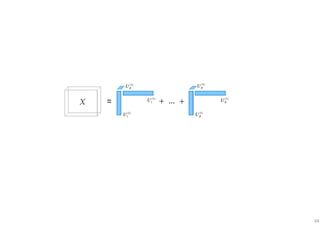
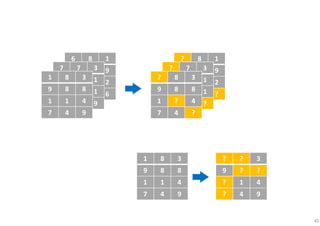
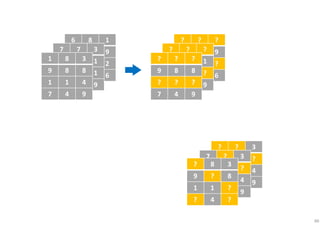
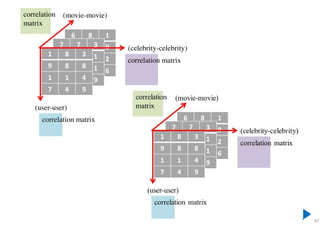
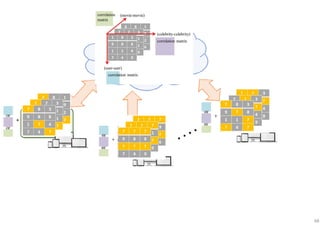


The document outlines probabilistic matrix factorization (PMF) and its applications in recommendation systems, particularly focusing on models like Bayesian PMF (BPMF) and constrained PMF. It discusses the mathematical foundations, learning processes, and comparisons between several factorization methods, emphasizing challenges such as computational complexity and parameter tuning. Additionally, it highlights the advantages of Bayesian approaches in improving predictive accuracy while addressing their computational demands.
















![Digital Signal Processing[ECEG-3171]-Ch1_L04](https://cdn.slidesharecdn.com/ss_thumbnails/dspl4-180427094424-thumbnail.jpg?width=640&height=640&fit=bounds)






![Digital Signal Processing[ECEG-3171]-Ch1_L03](https://cdn.slidesharecdn.com/ss_thumbnails/dspl3-180427094423-thumbnail.jpg?width=640&height=640&fit=bounds)



![Digital Signal Processing[ECEG-3171]-Ch1_L02](https://cdn.slidesharecdn.com/ss_thumbnails/dspl2-180427094423-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




