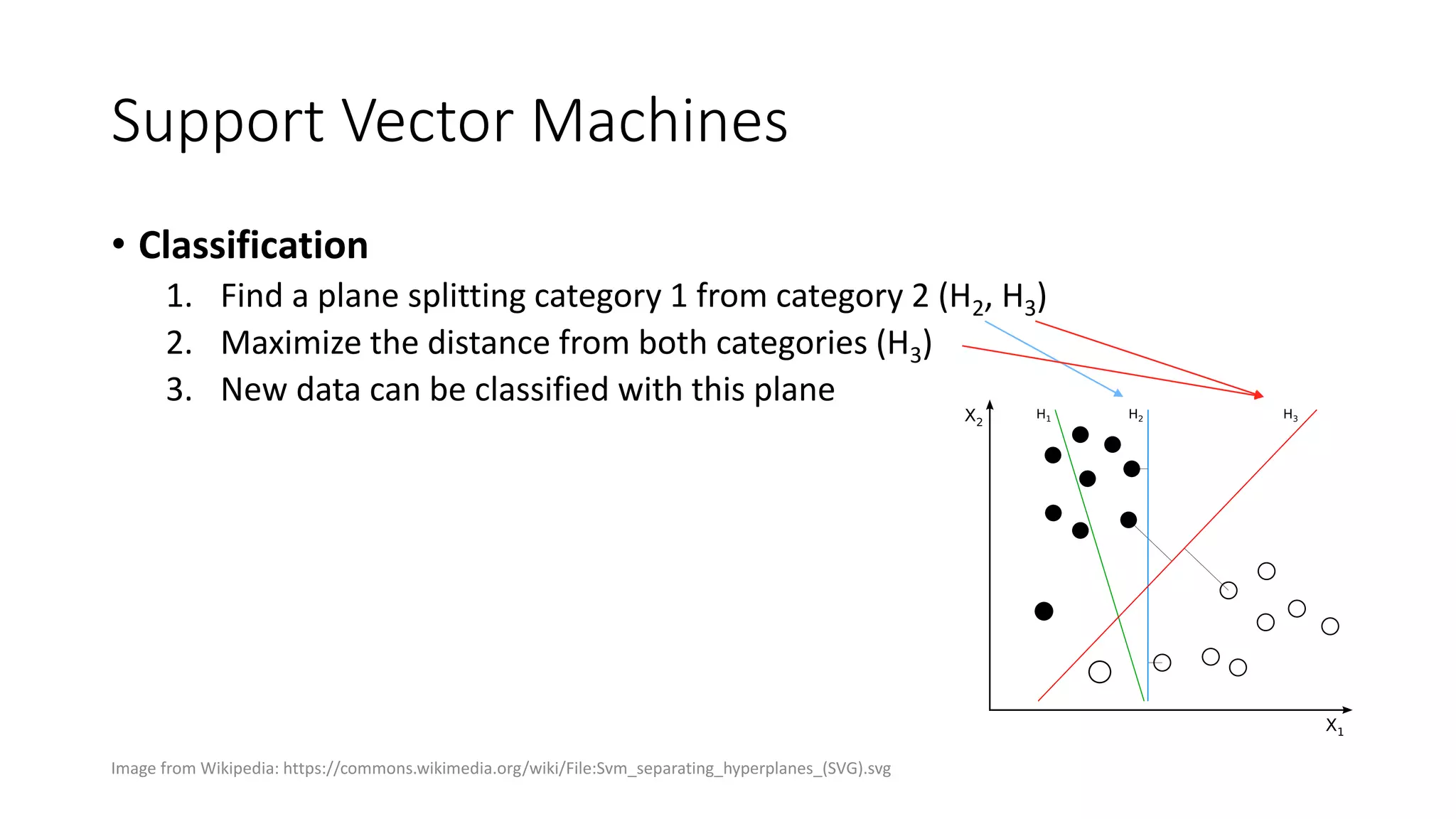
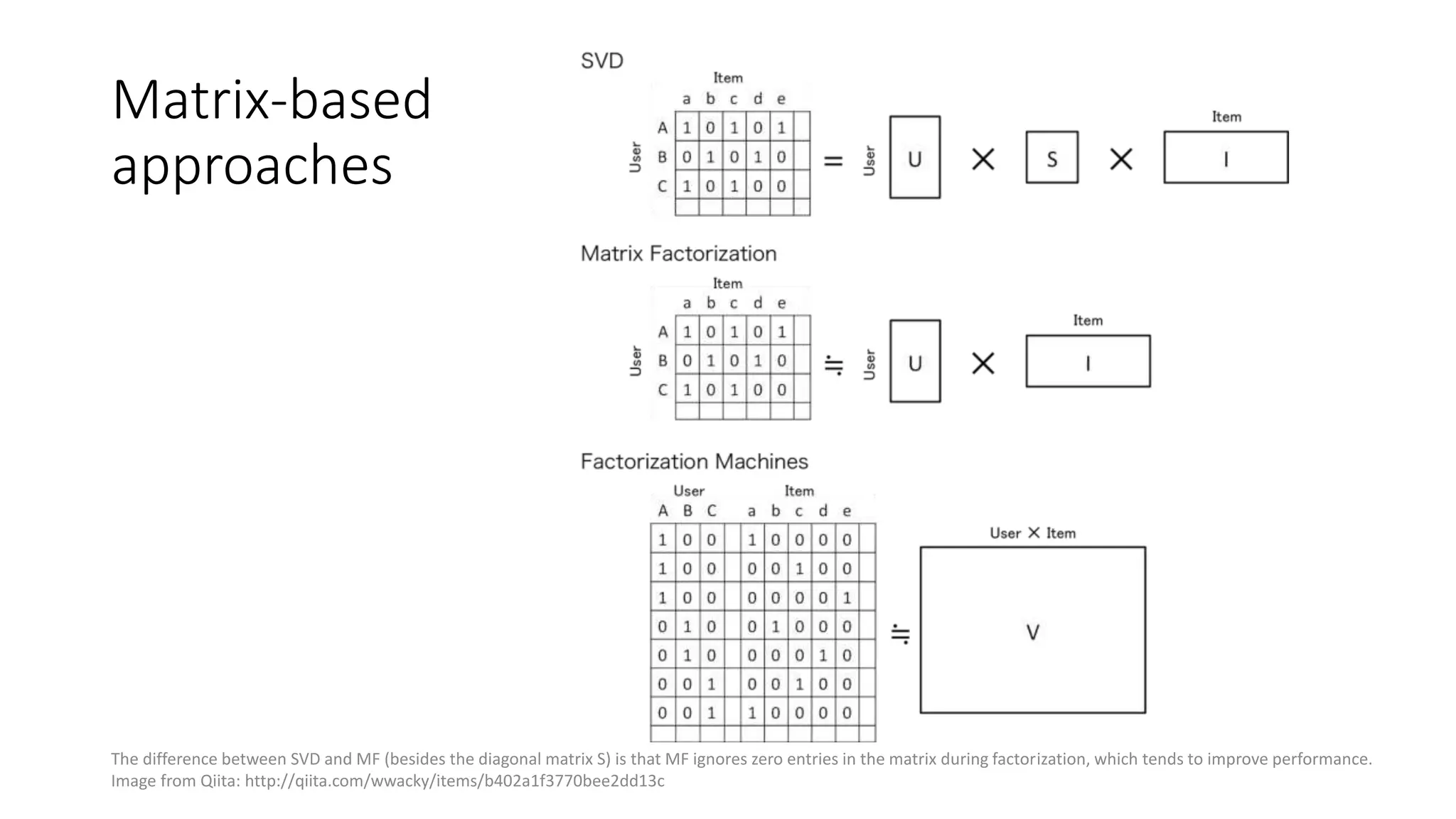
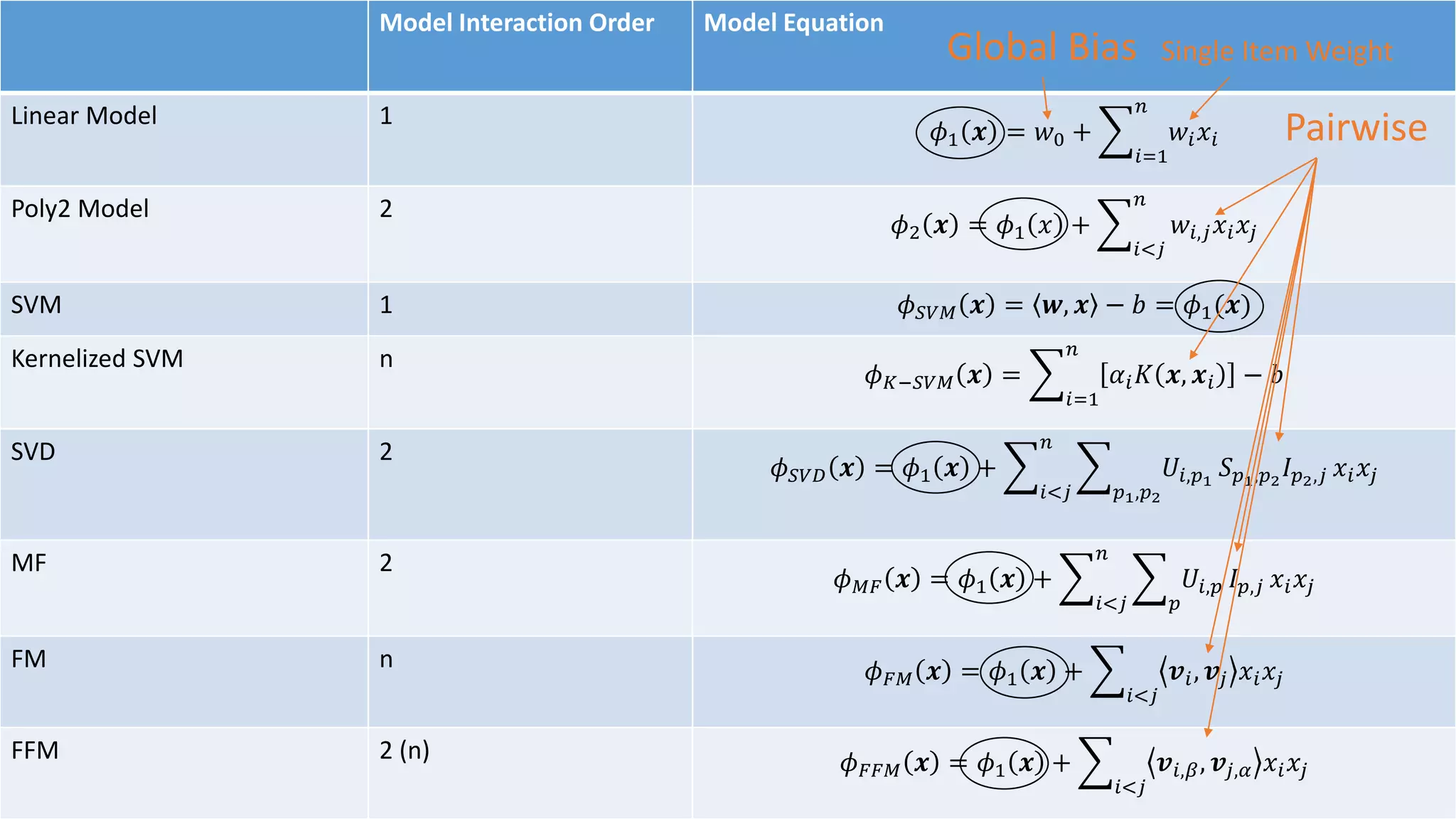
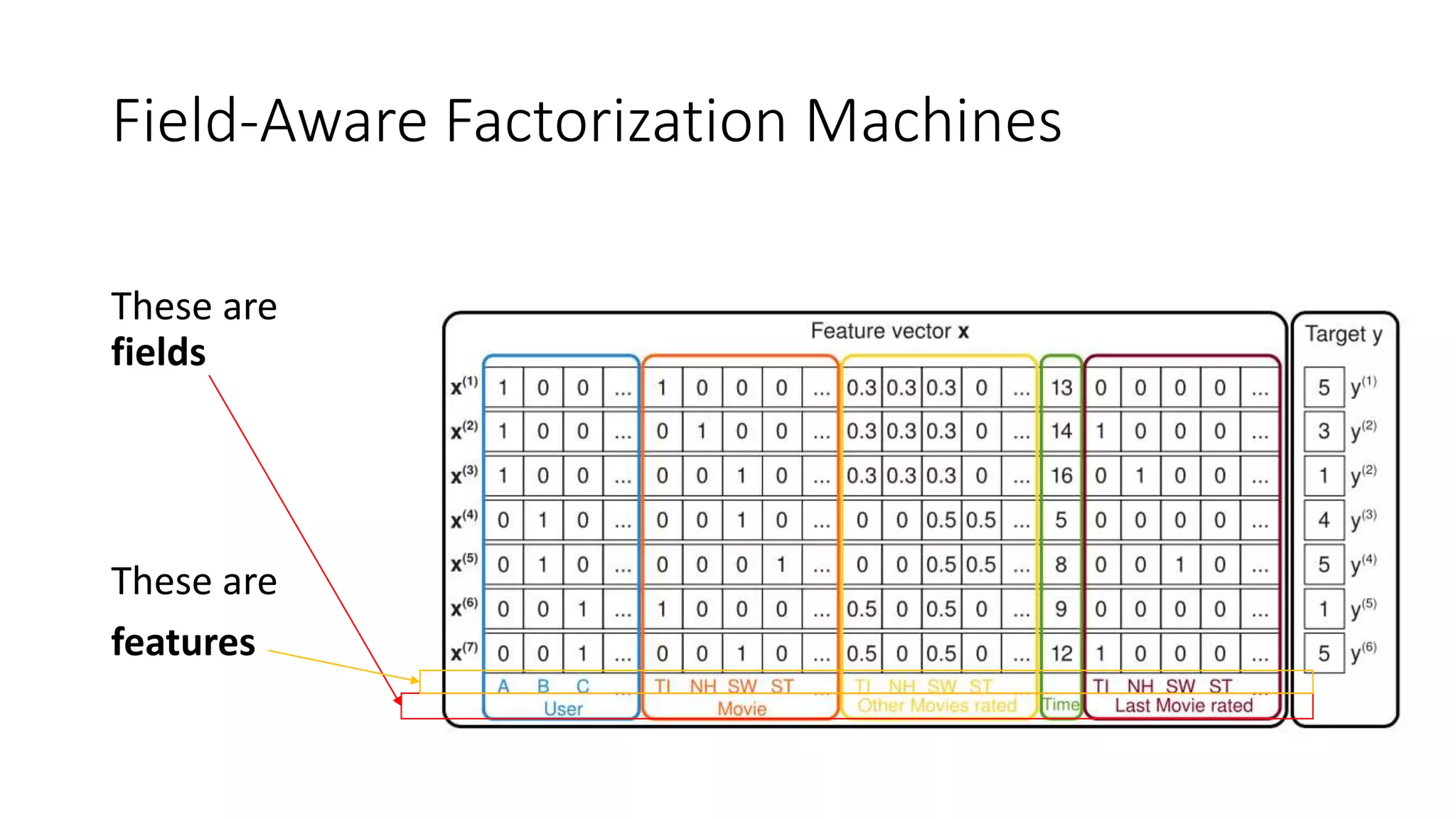
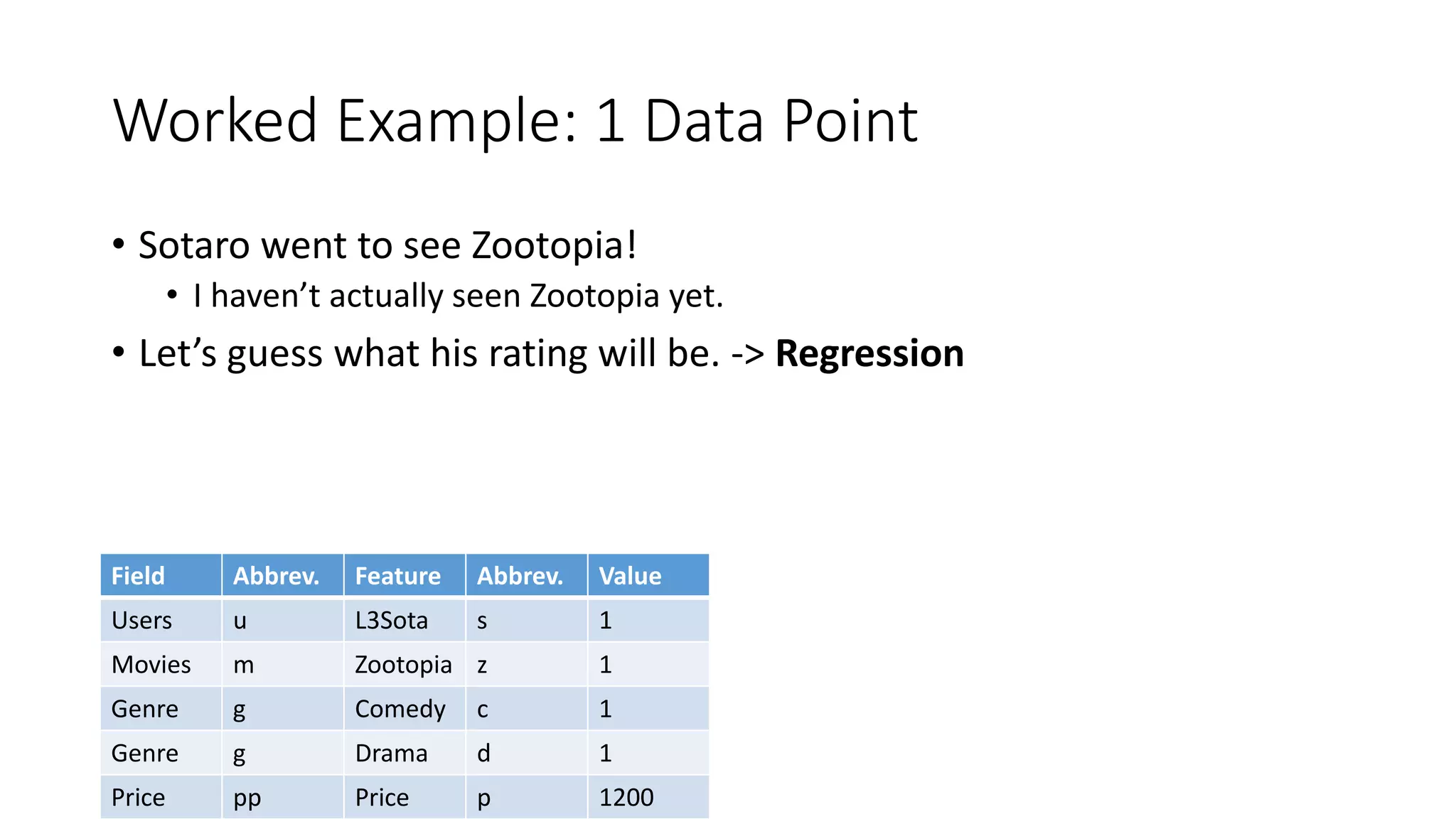
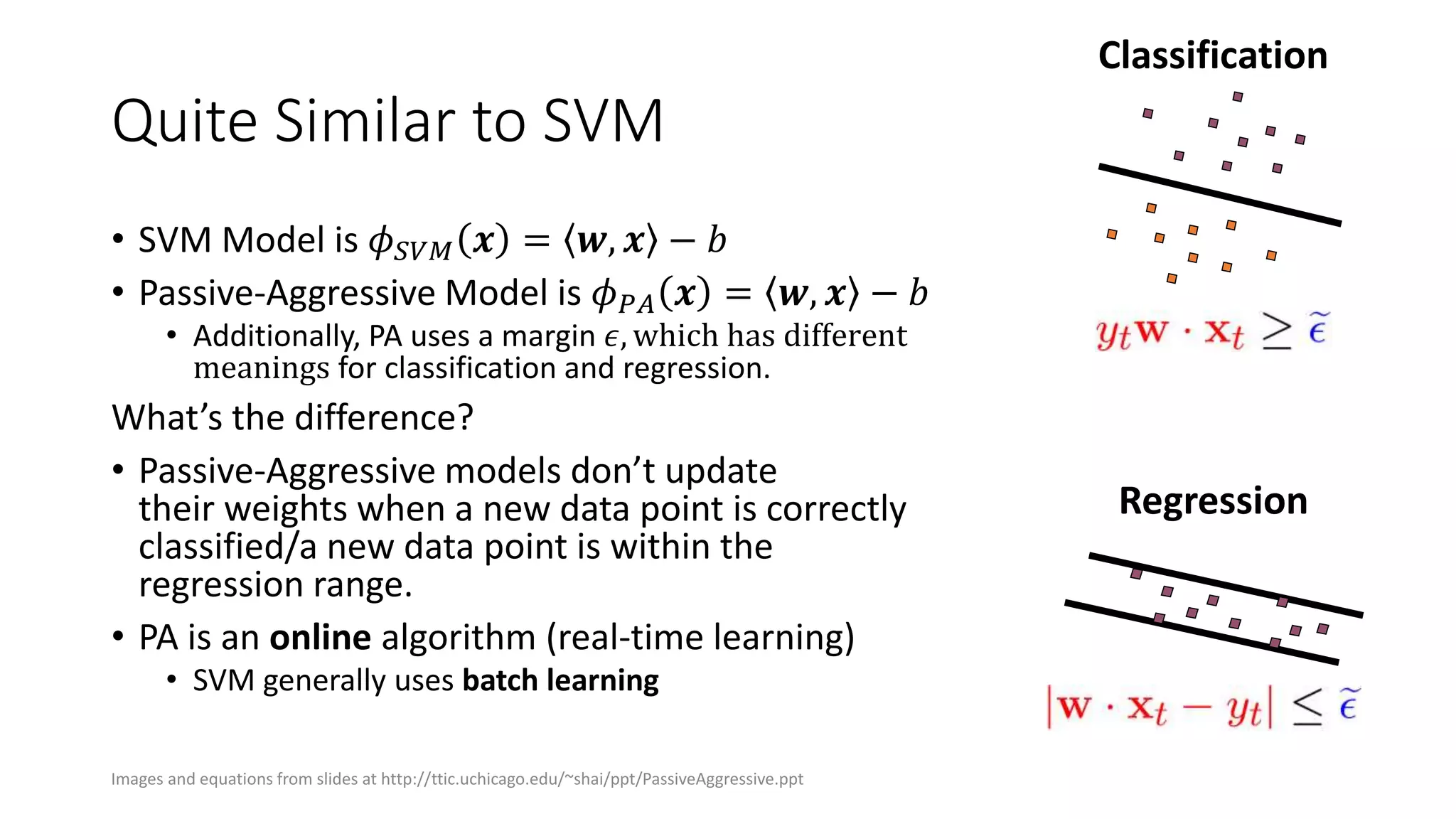
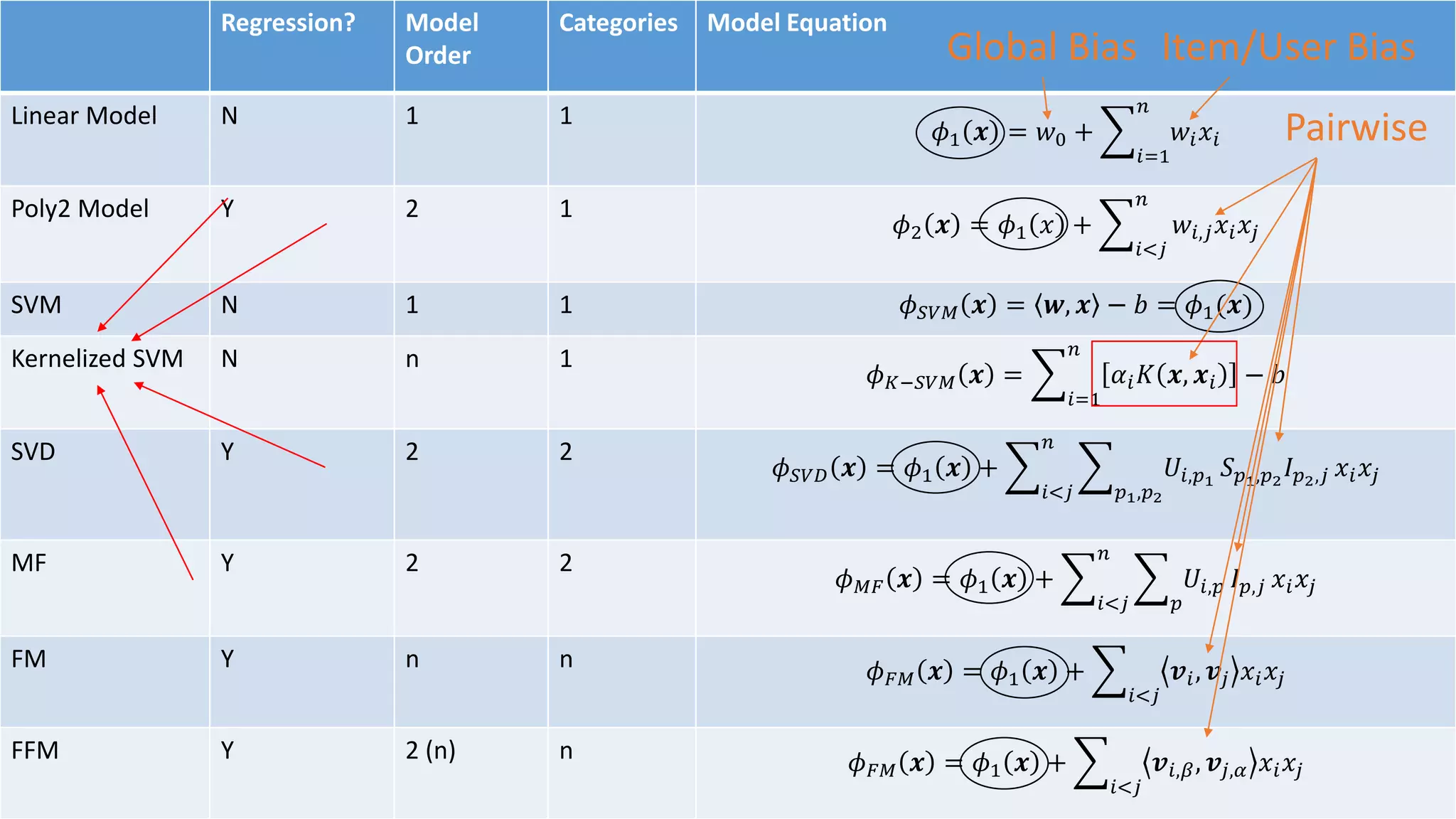
The document outlines an internship presentation by Sotaro Sugimoto at Treasure Data, focusing on machine learning techniques including field-aware factorization machines and kernelized passive-aggressive models. It discusses model-based predictors for tasks like click-through rate prediction and shopping recommendations, detailing the mechanics and advantages of these models. The presentation also covers the implementation status of these algorithms within the Hivemall framework.






















![Status of FFM within Hivemall
• Pull request merged (#284)
• https://github.com/myui/hivemall/pull/284
• Will probably be in next release(?)
• train_ffm(array<string> x, double y[, const string options])
• Trains the internal FFM model using a (sparse) vector x and target y.
• Training uses Stochastic Gradient Descent (SGD).
• ffm_predict(m.model_id, m.model, data.features)
• Calculates a prediction from the given FFM model and data vector.
• The internal FFM model is referenced as ffm_model m](https://image.slidesharecdn.com/spring2016intern-160616080150/75/Spring-2016-Intern-at-Treasure-Data-28-2048.jpg)







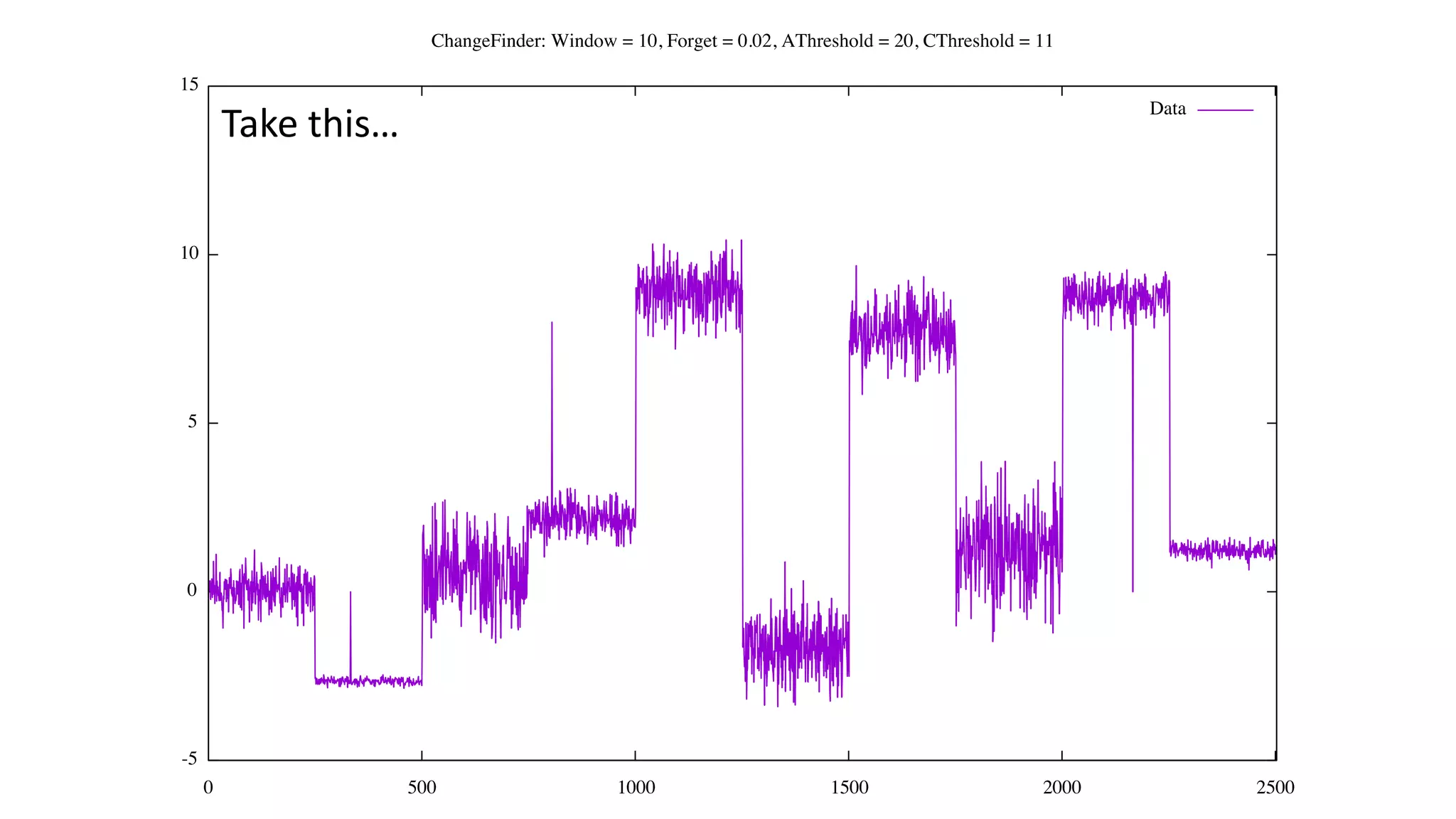
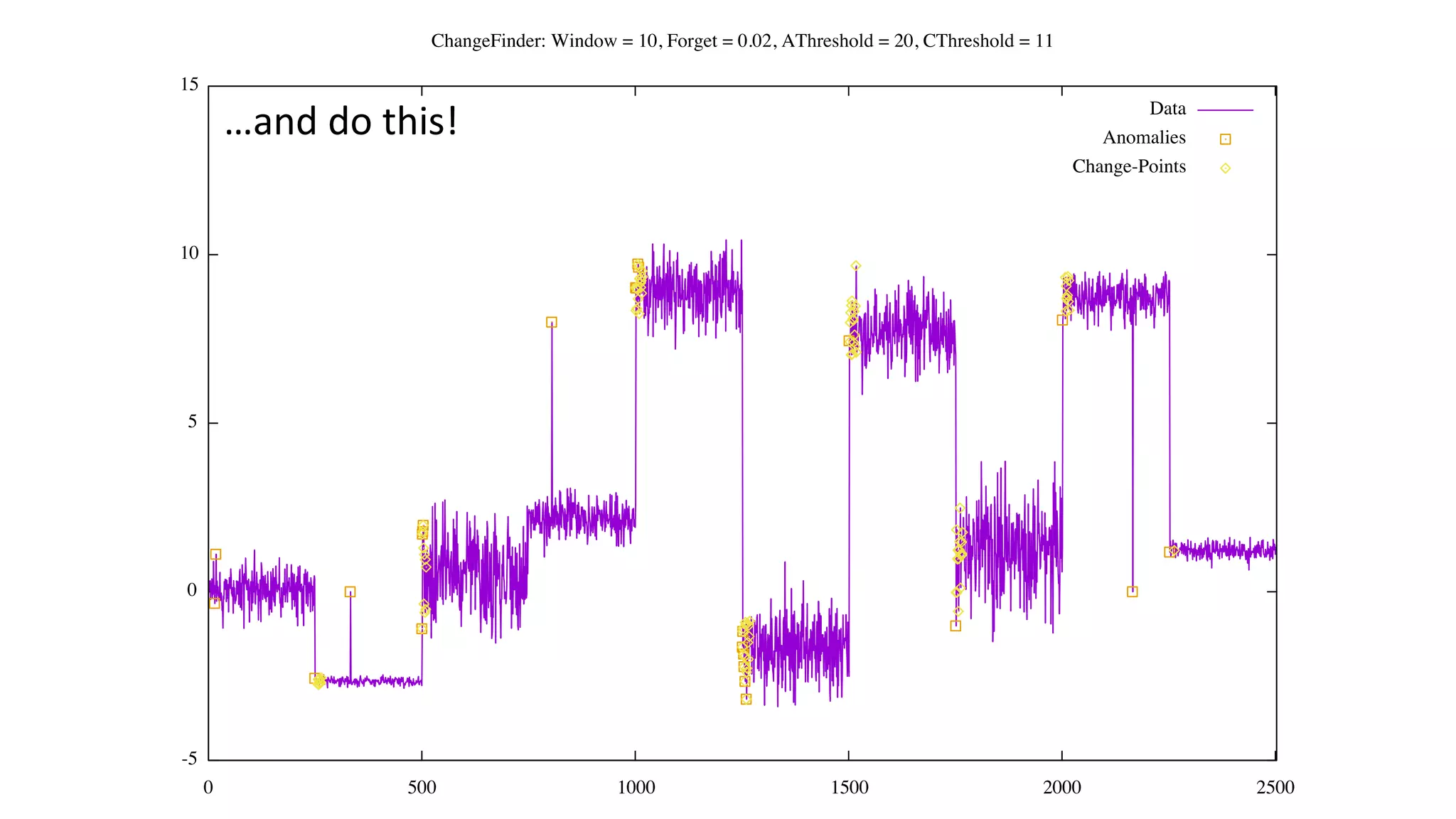



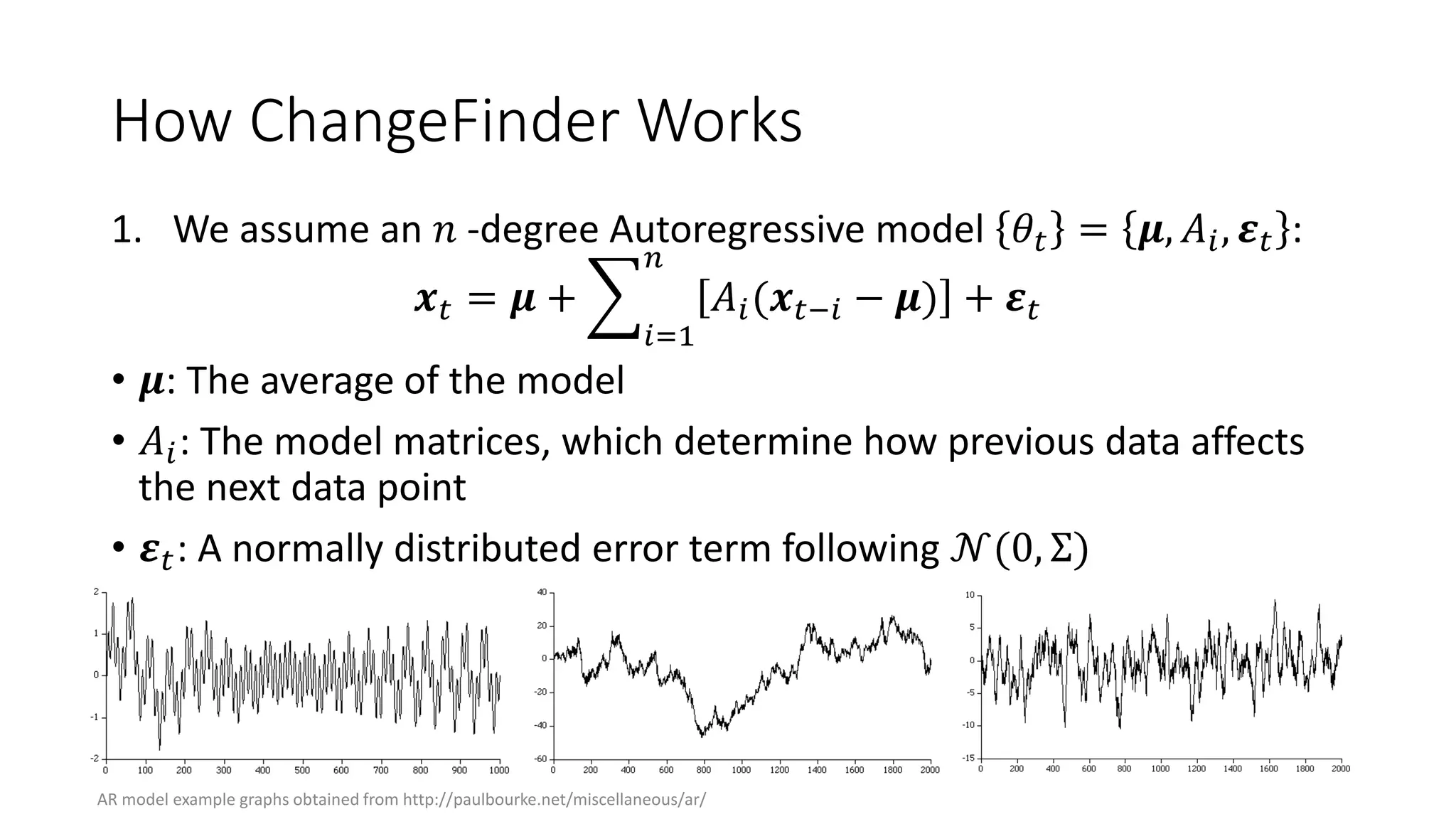



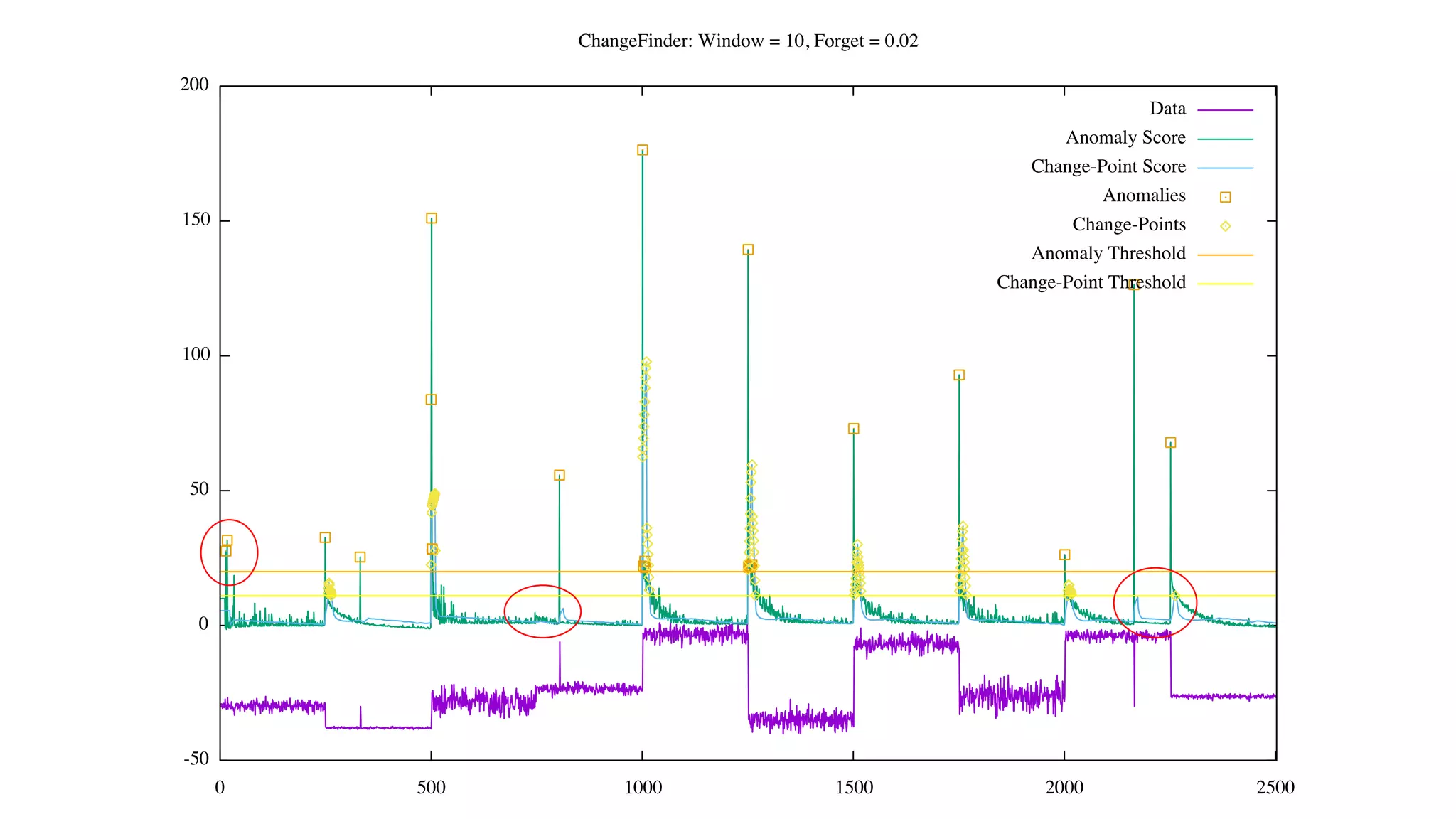
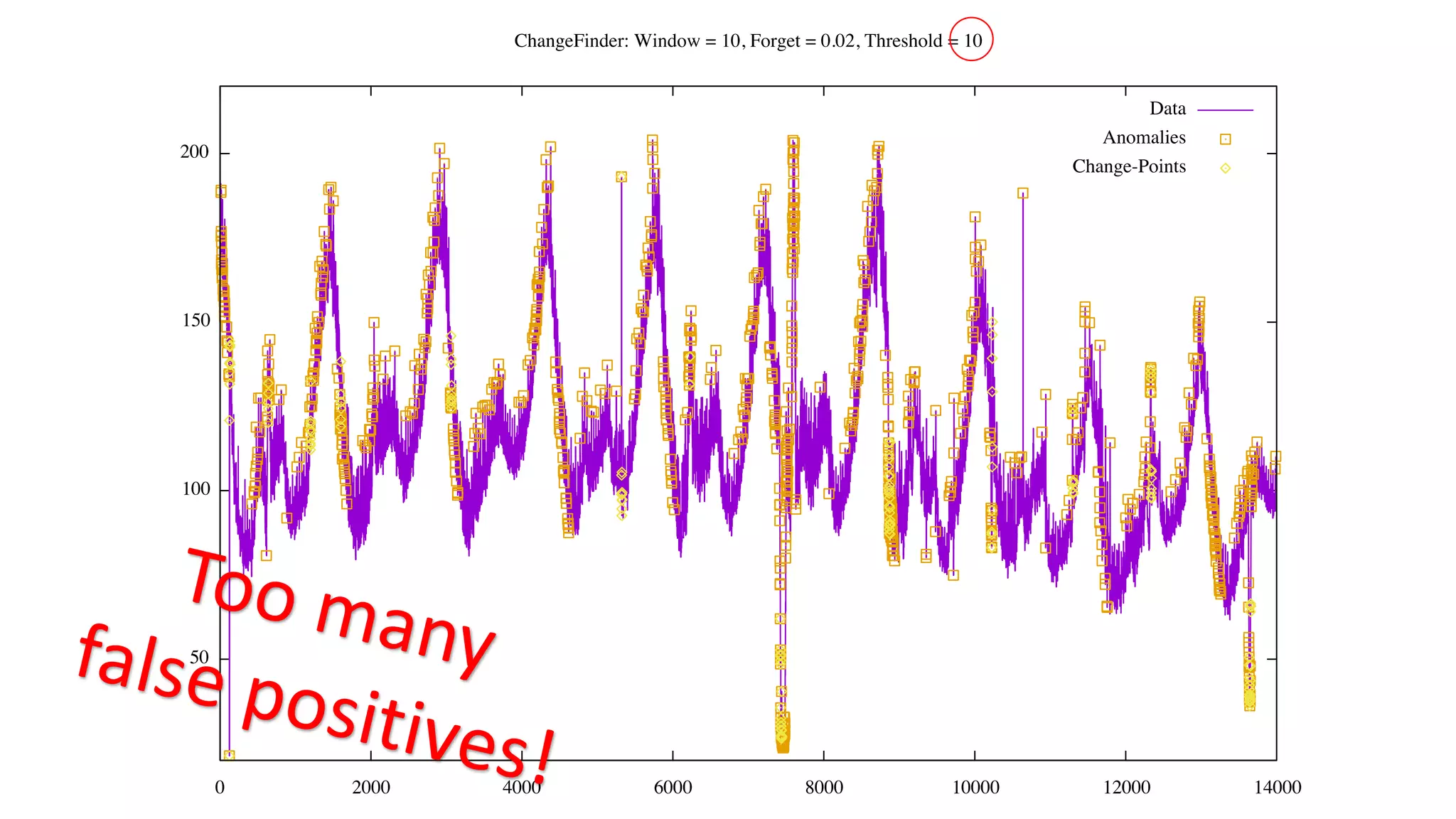
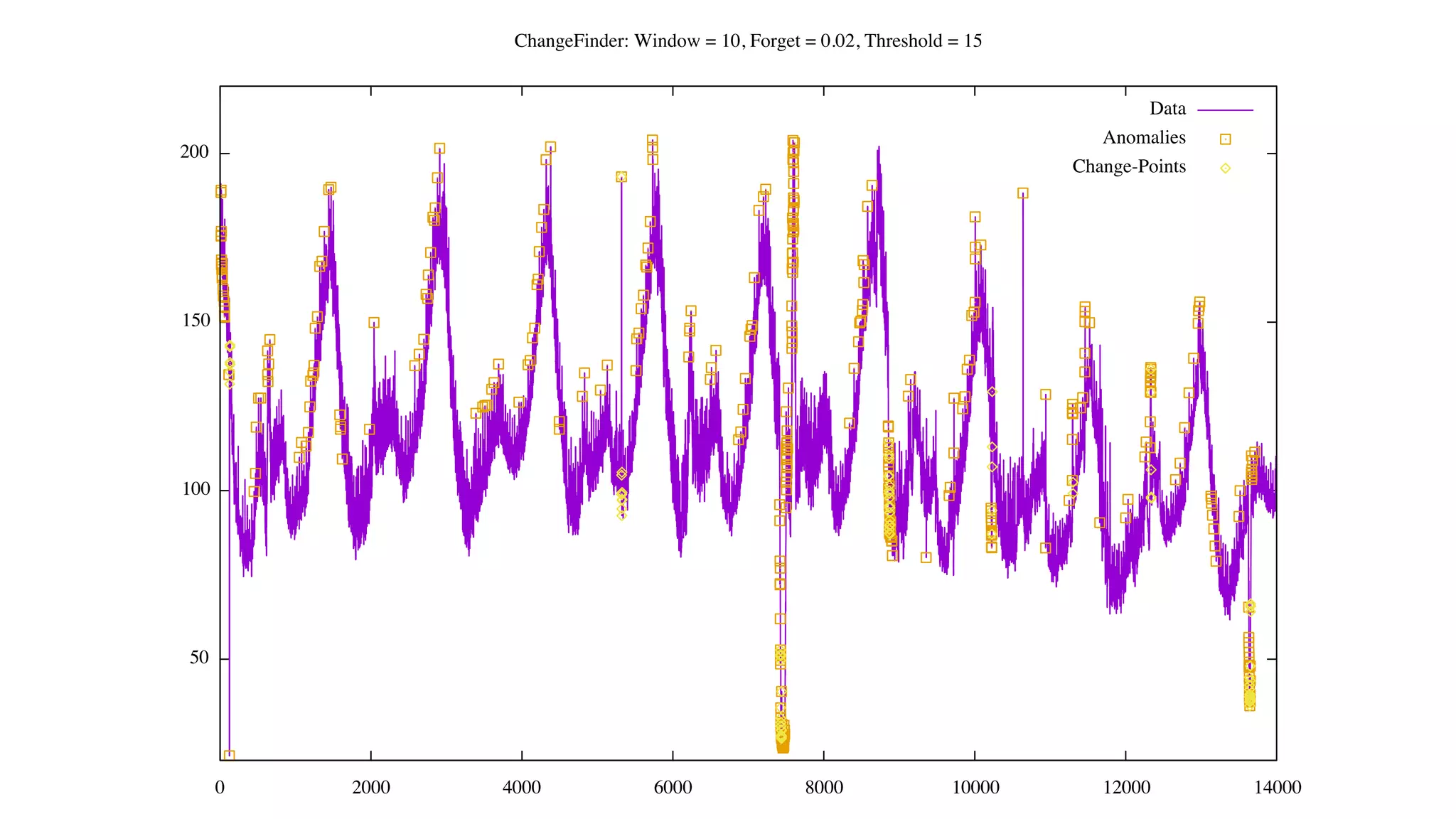
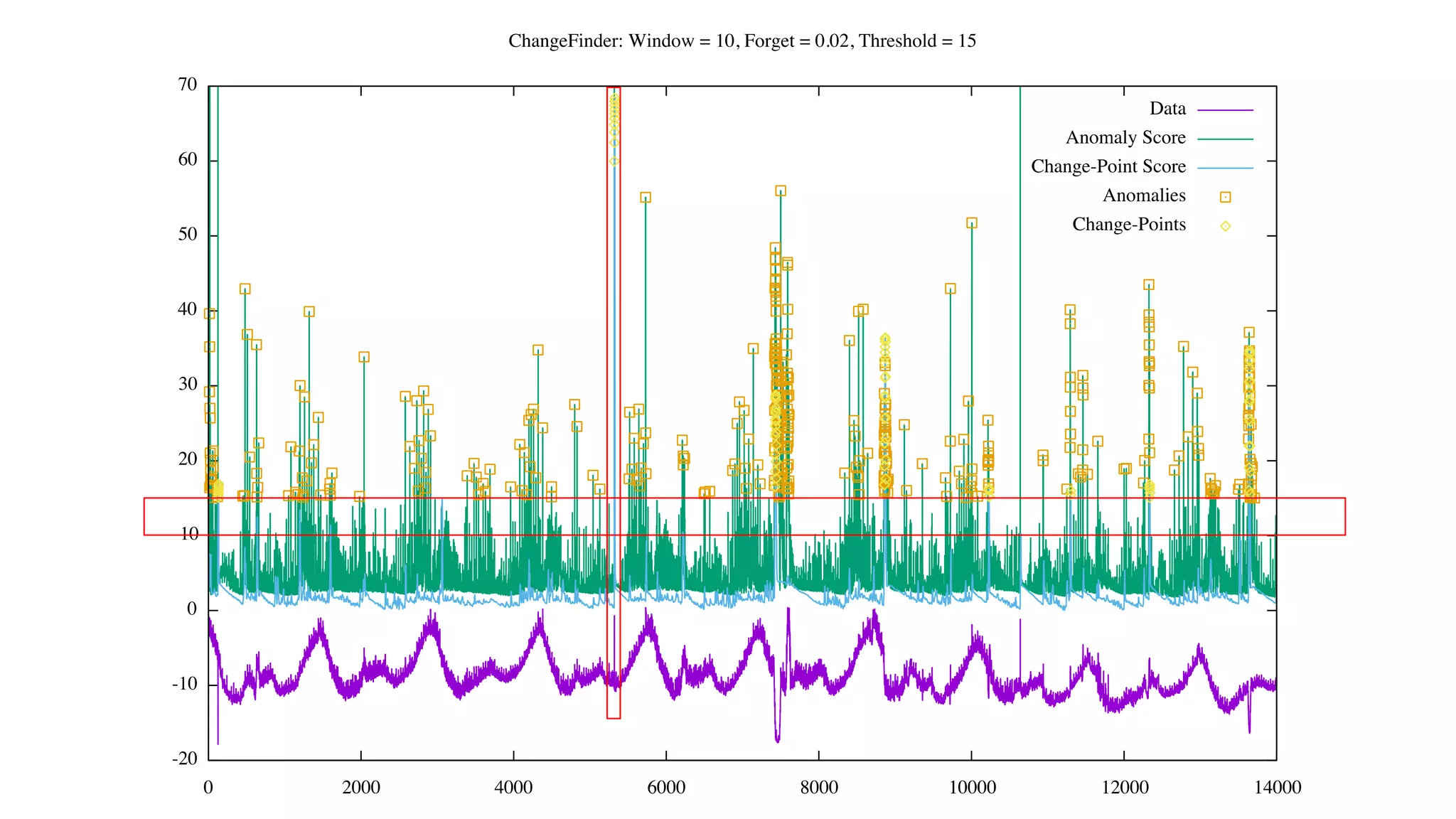
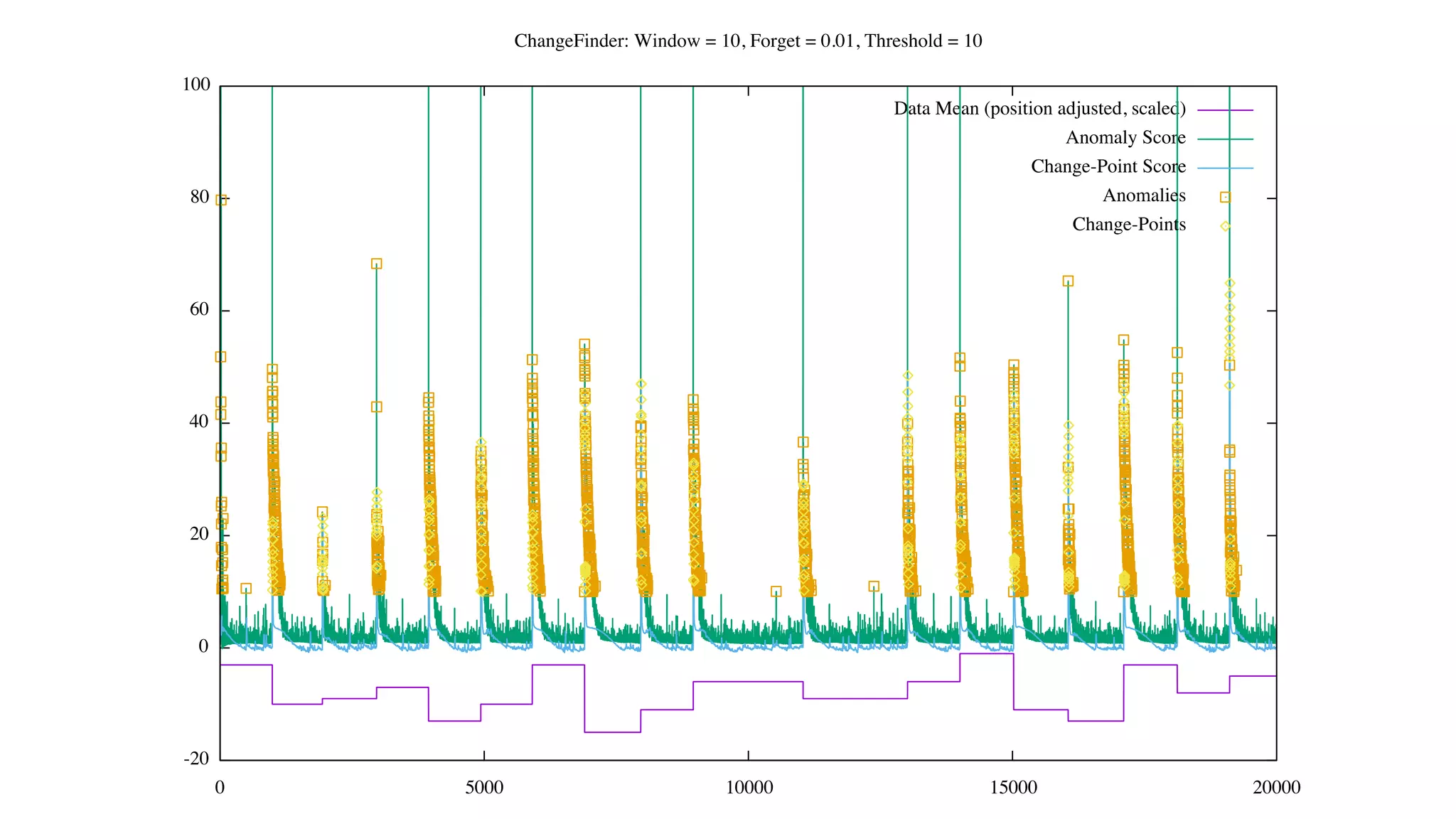
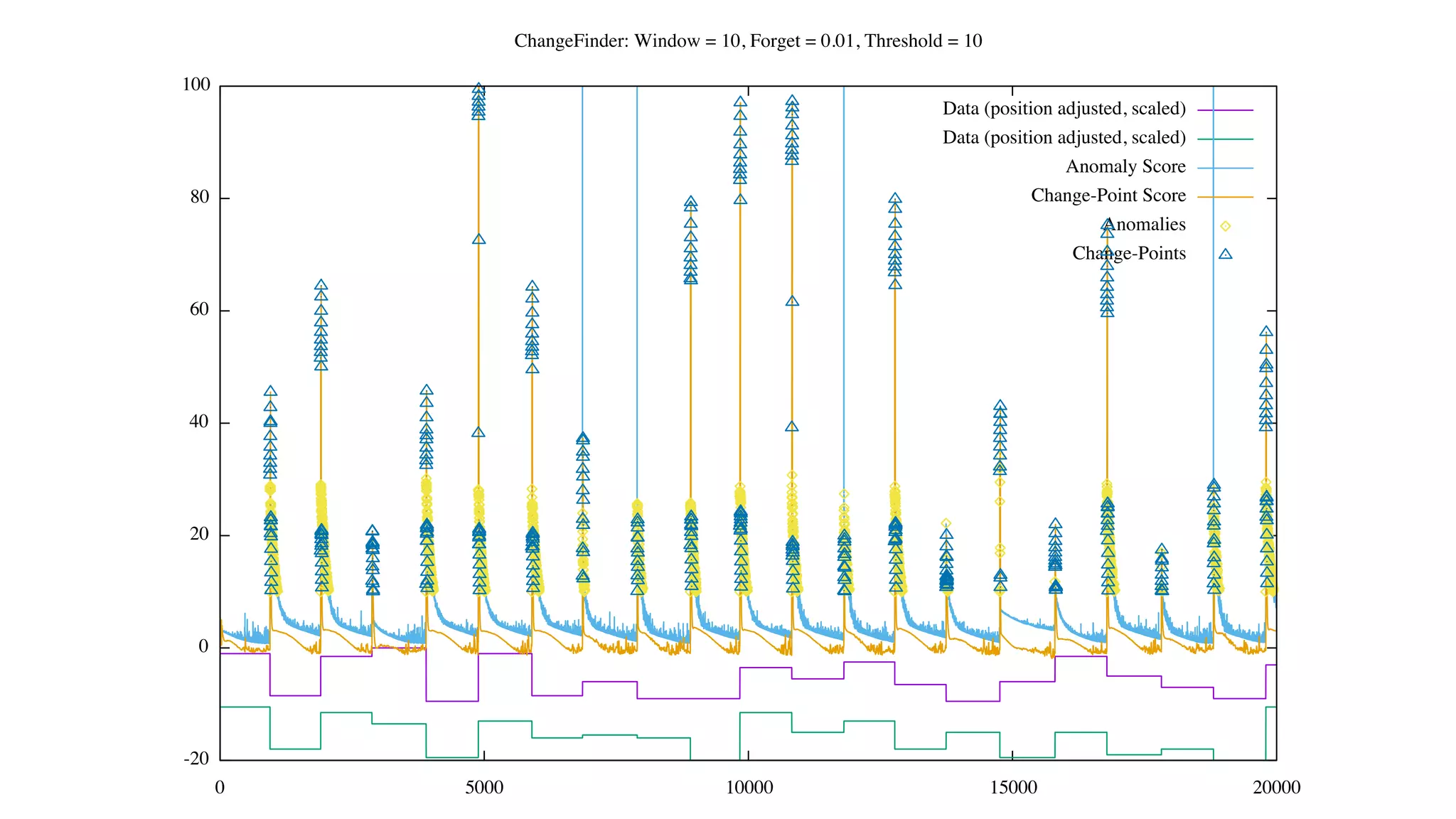
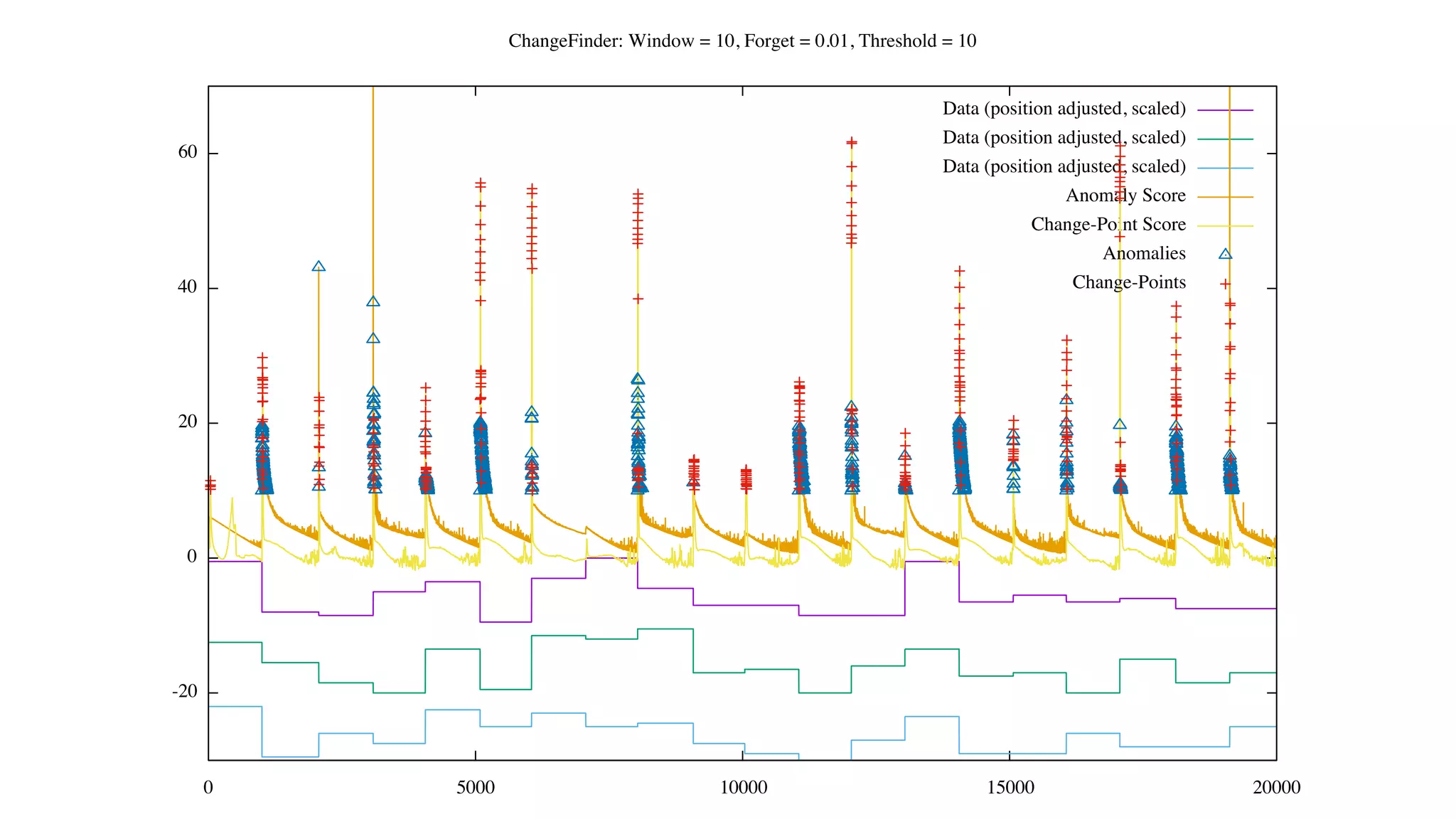
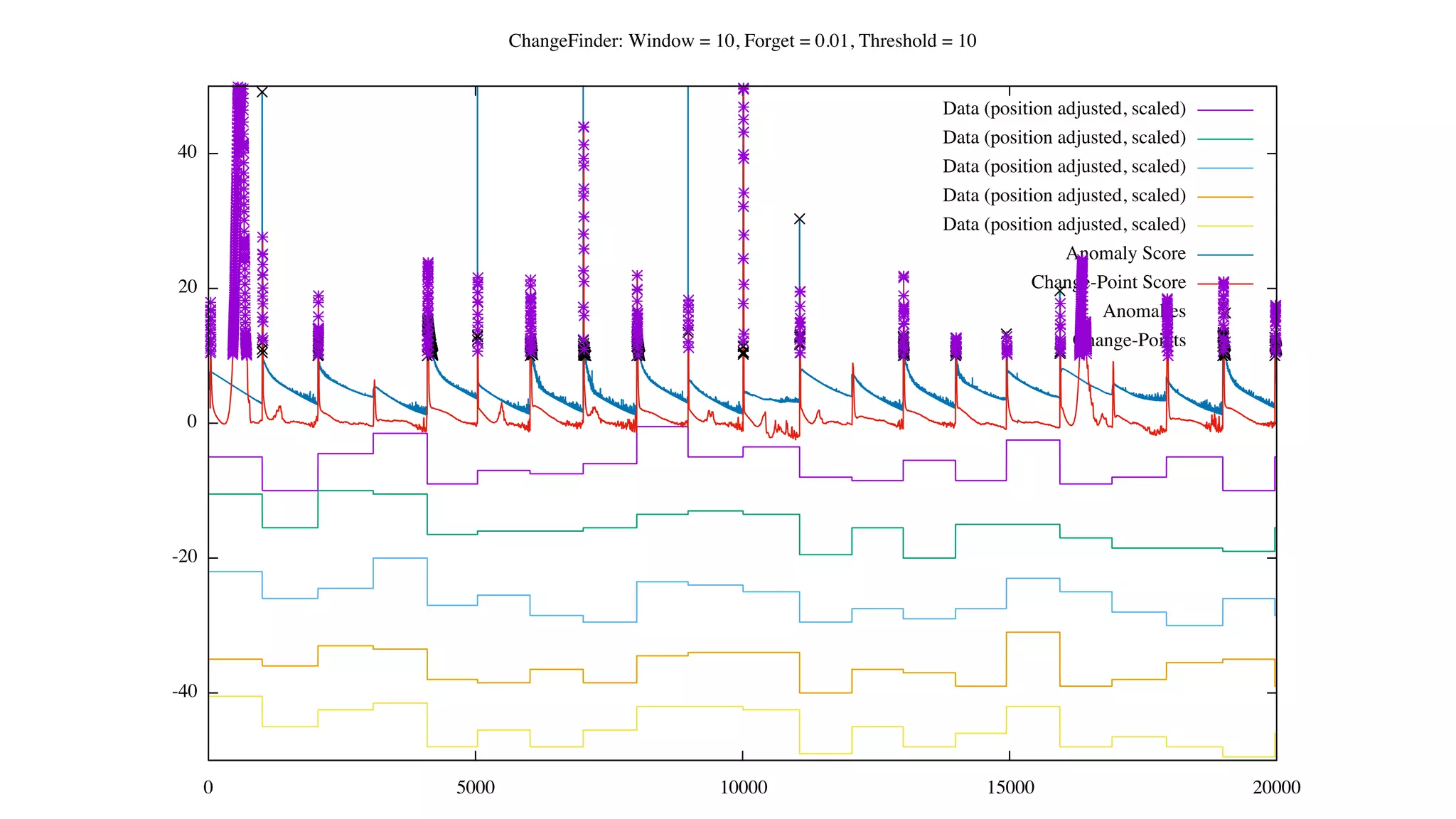
![Status of ChangeFinder within Hivemall
• No pull request yet
• https://github.com/L3Sota/hivemall/tree/feature/cf_sdar_focused
• Mostly complete but some issues remain with detection accuracy, esp. at
higher dimensions
• cf_detect(array<double> x[, const string options])
• ChangeFinder expects input one data point (one vector) at a time, and
automatically learns from the data in the order provided while returning
detection results.](https://image.slidesharecdn.com/spring2016intern-160616080150/75/Spring-2016-Intern-at-Treasure-Data-56-2048.jpg)


























![[ML]-SVM2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-svm2-230916145832-2580c8e3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)


