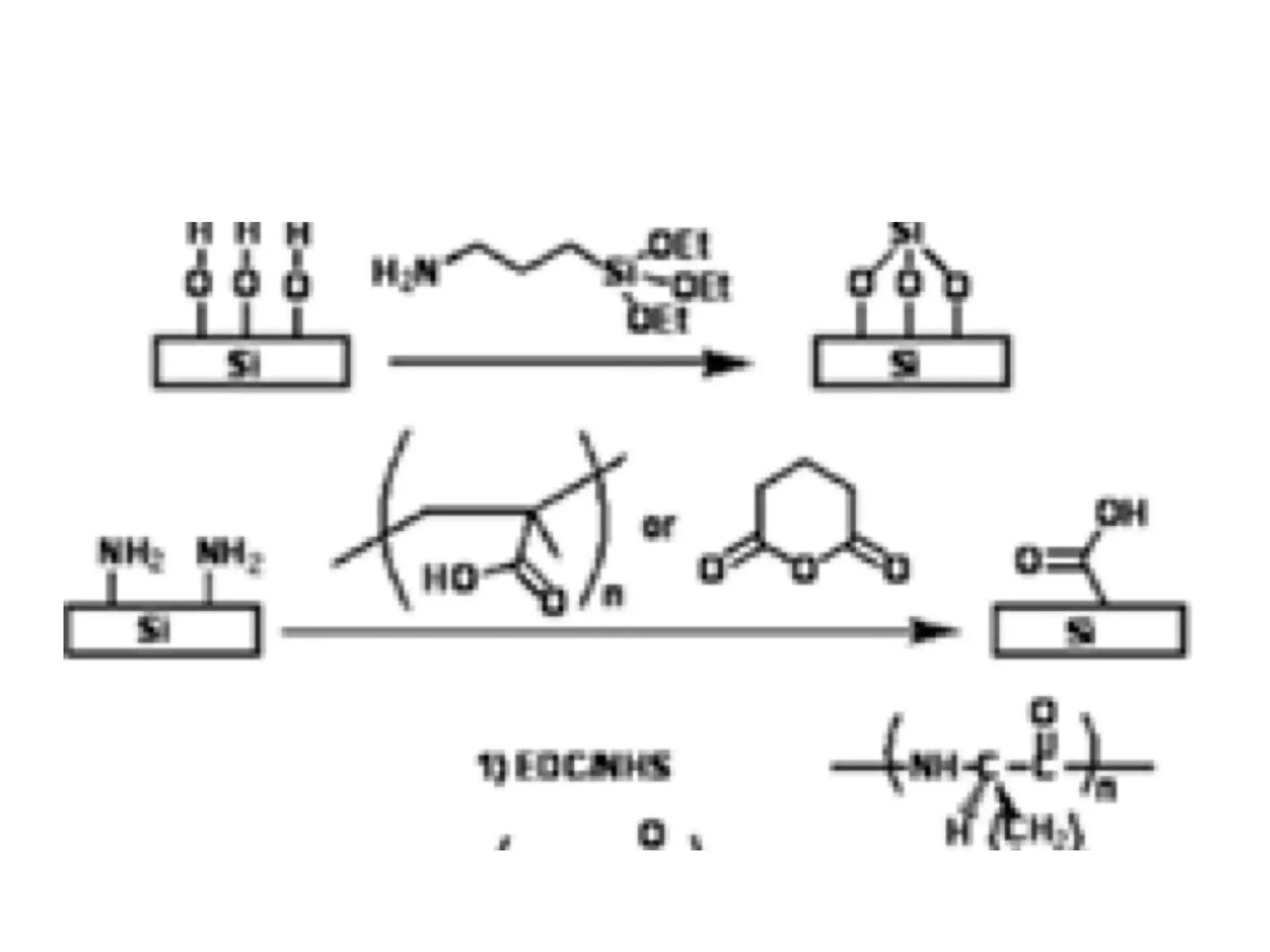
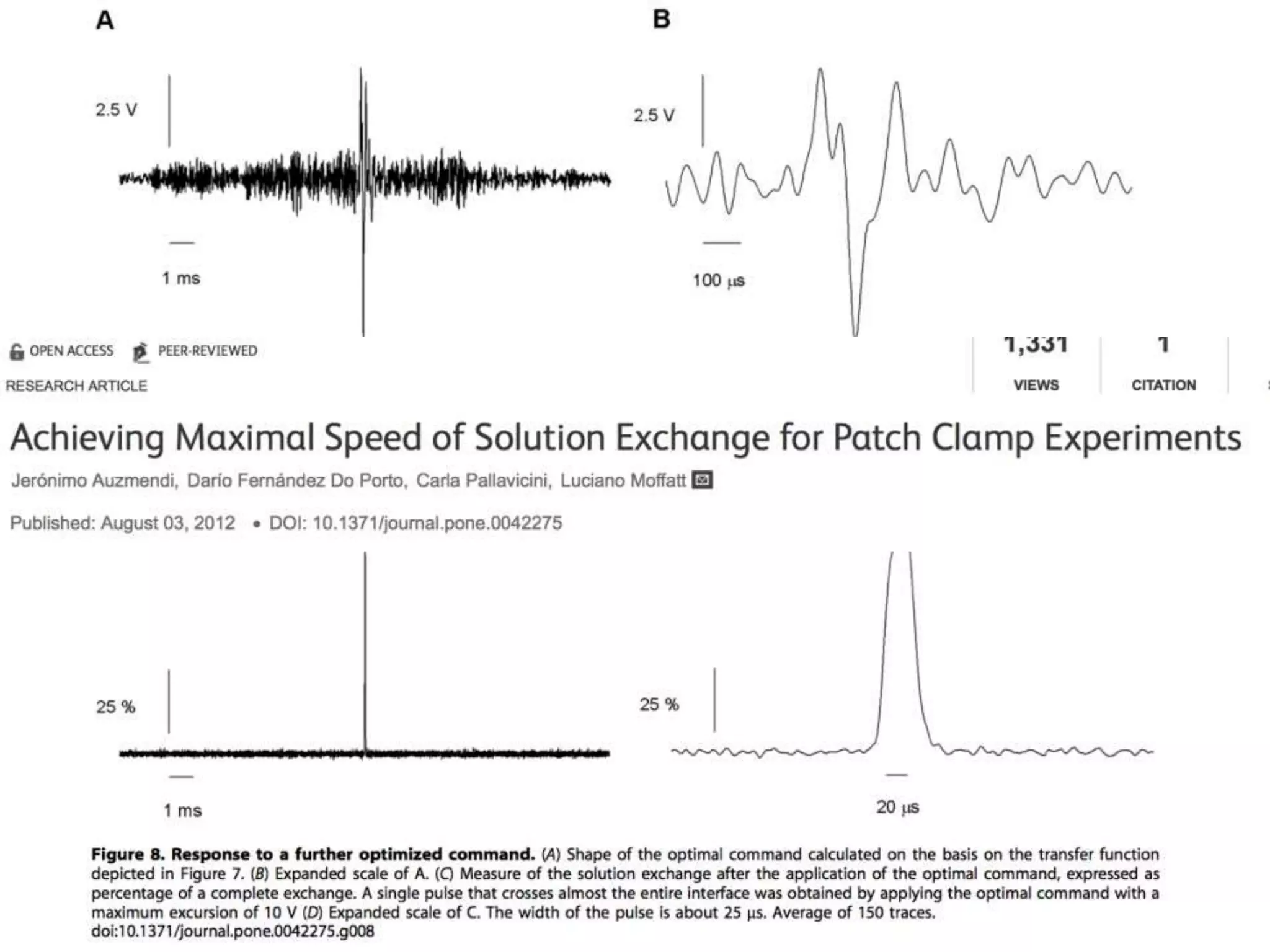
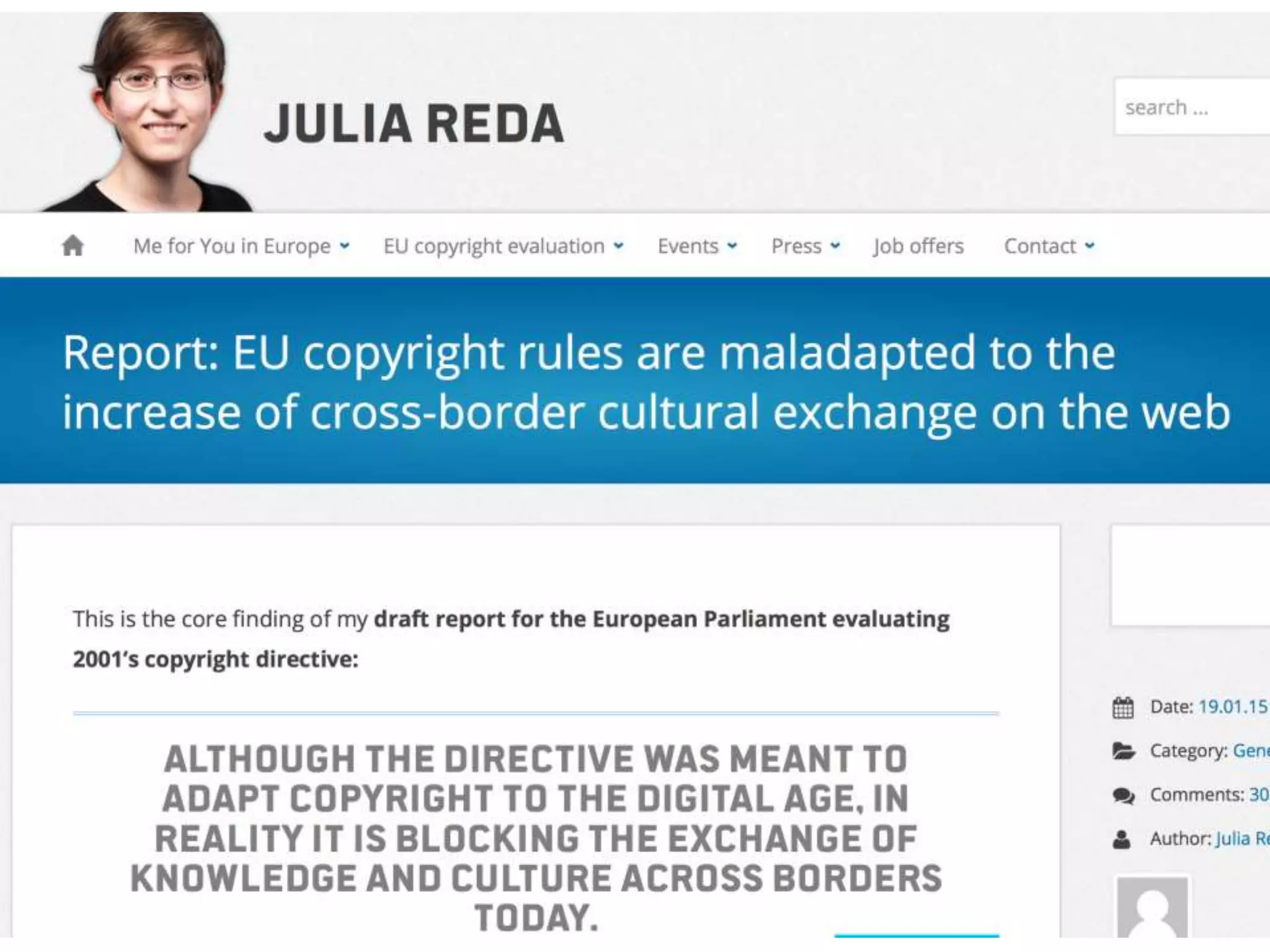
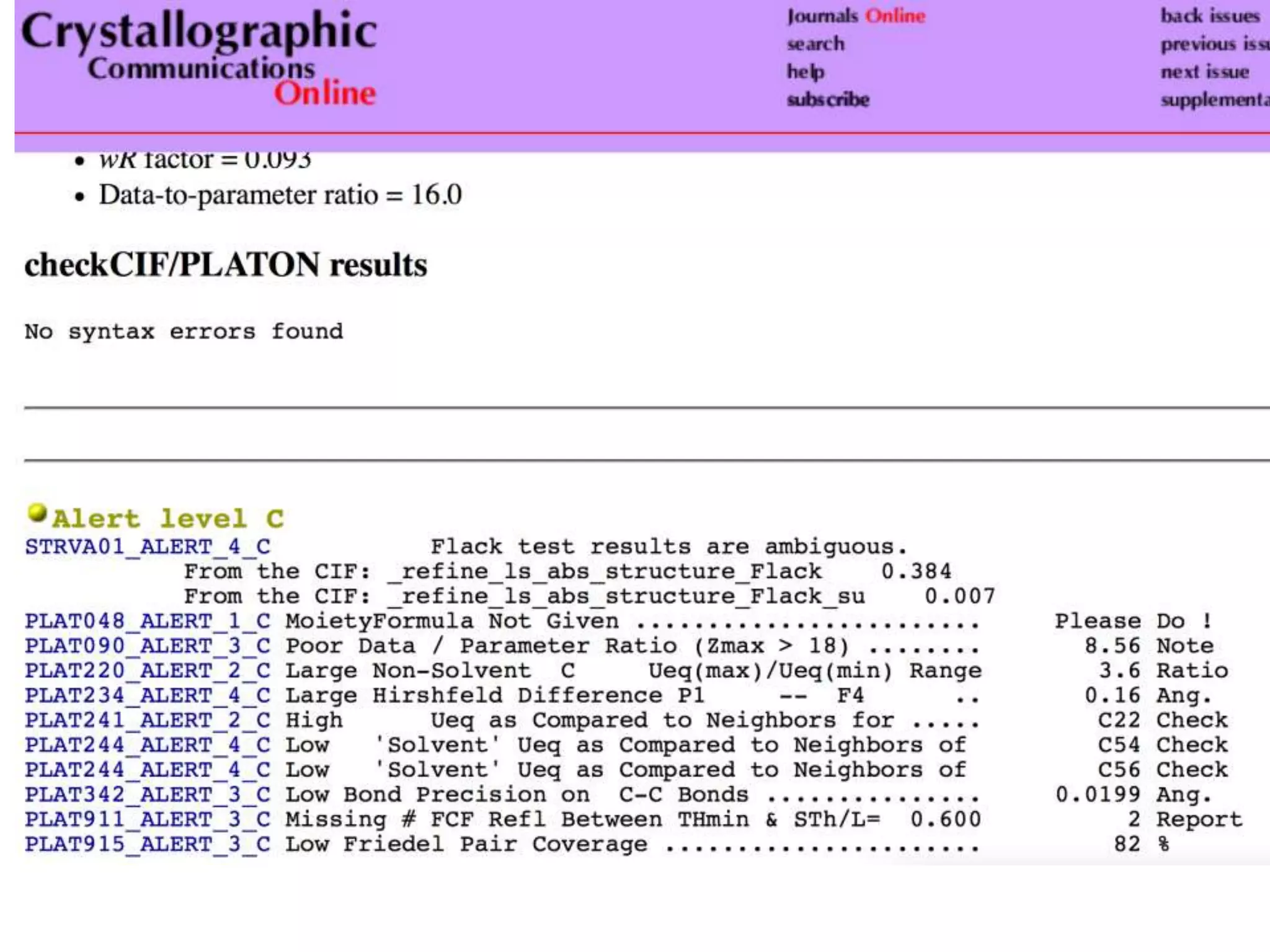
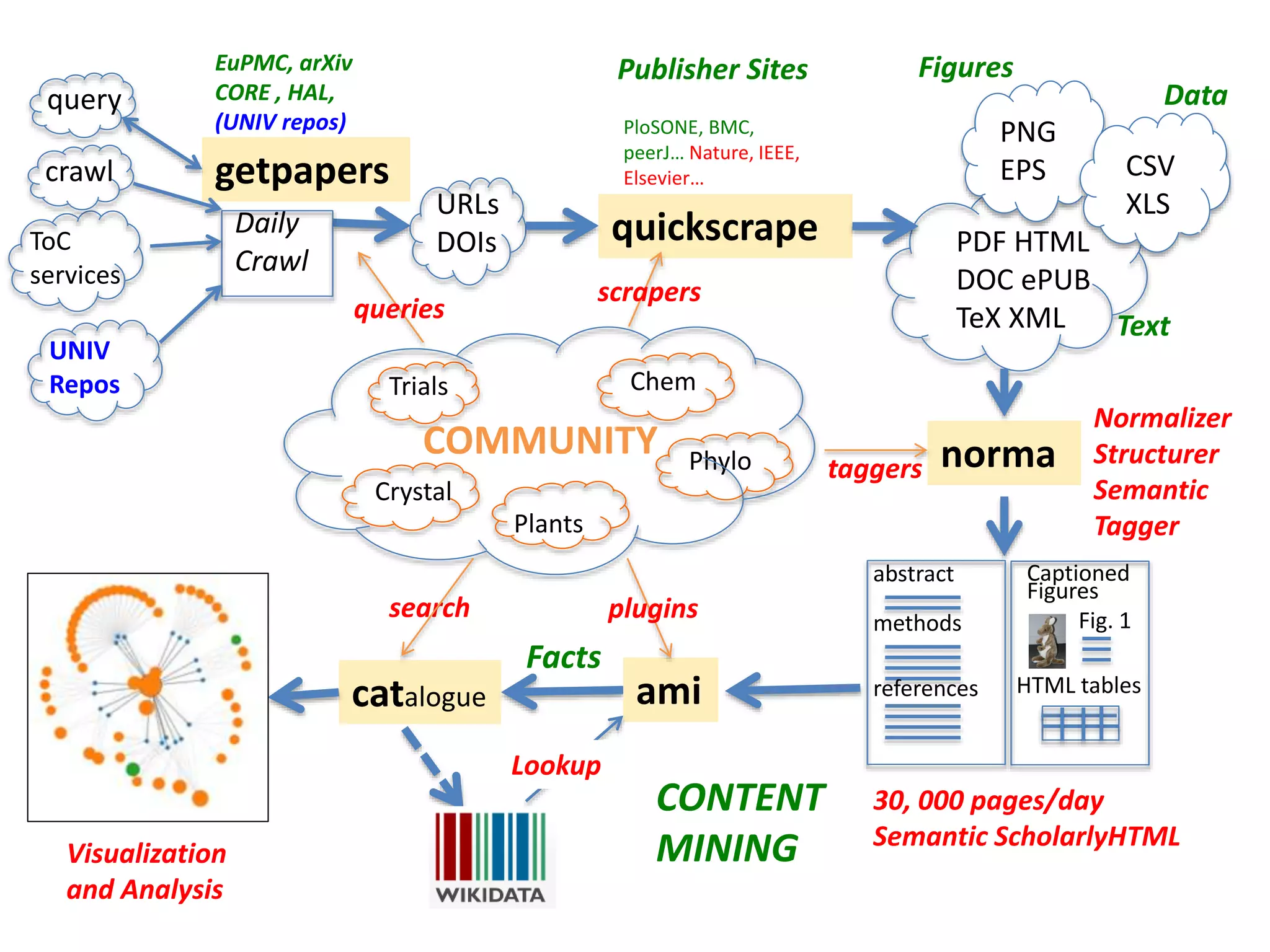
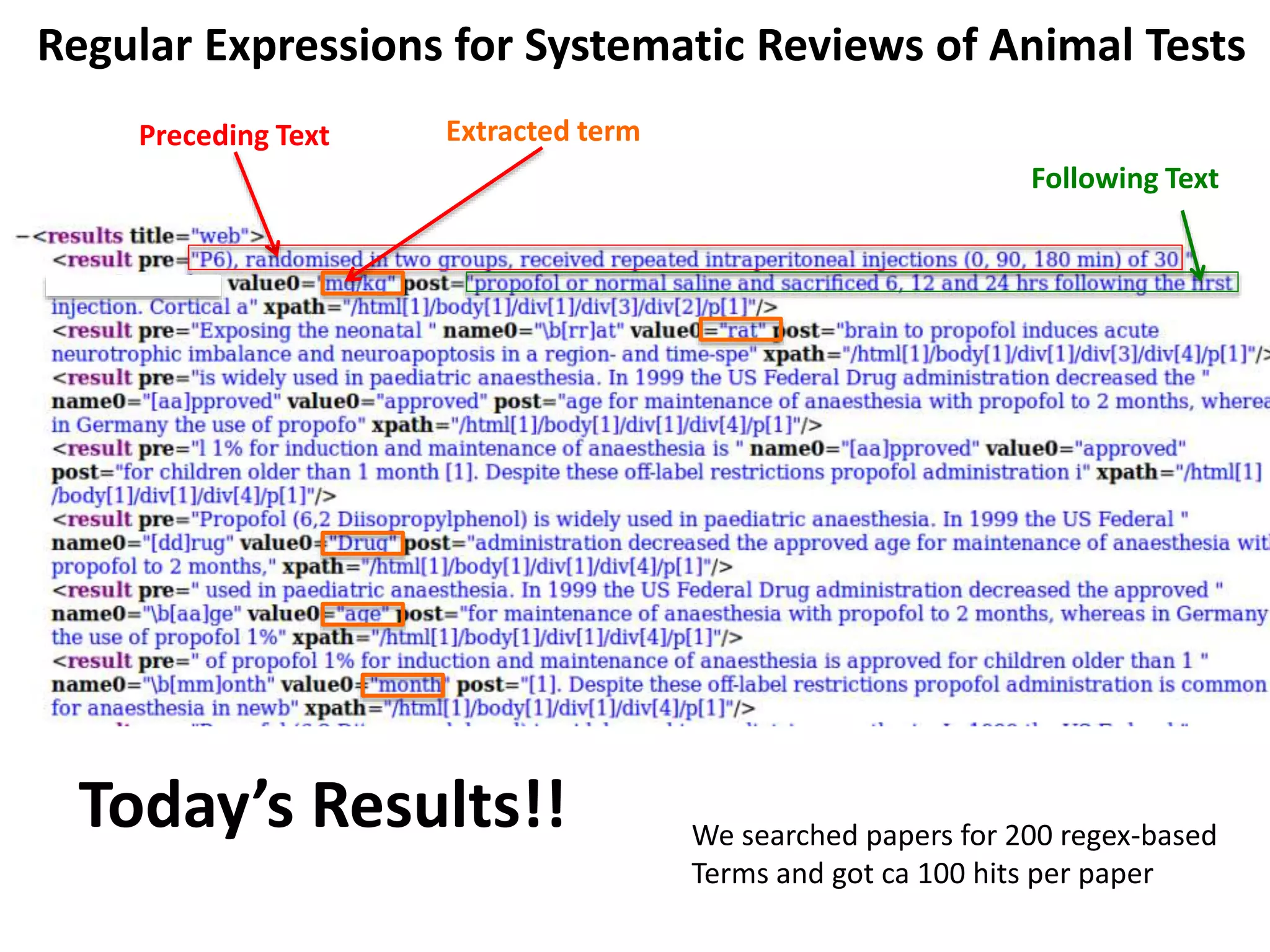
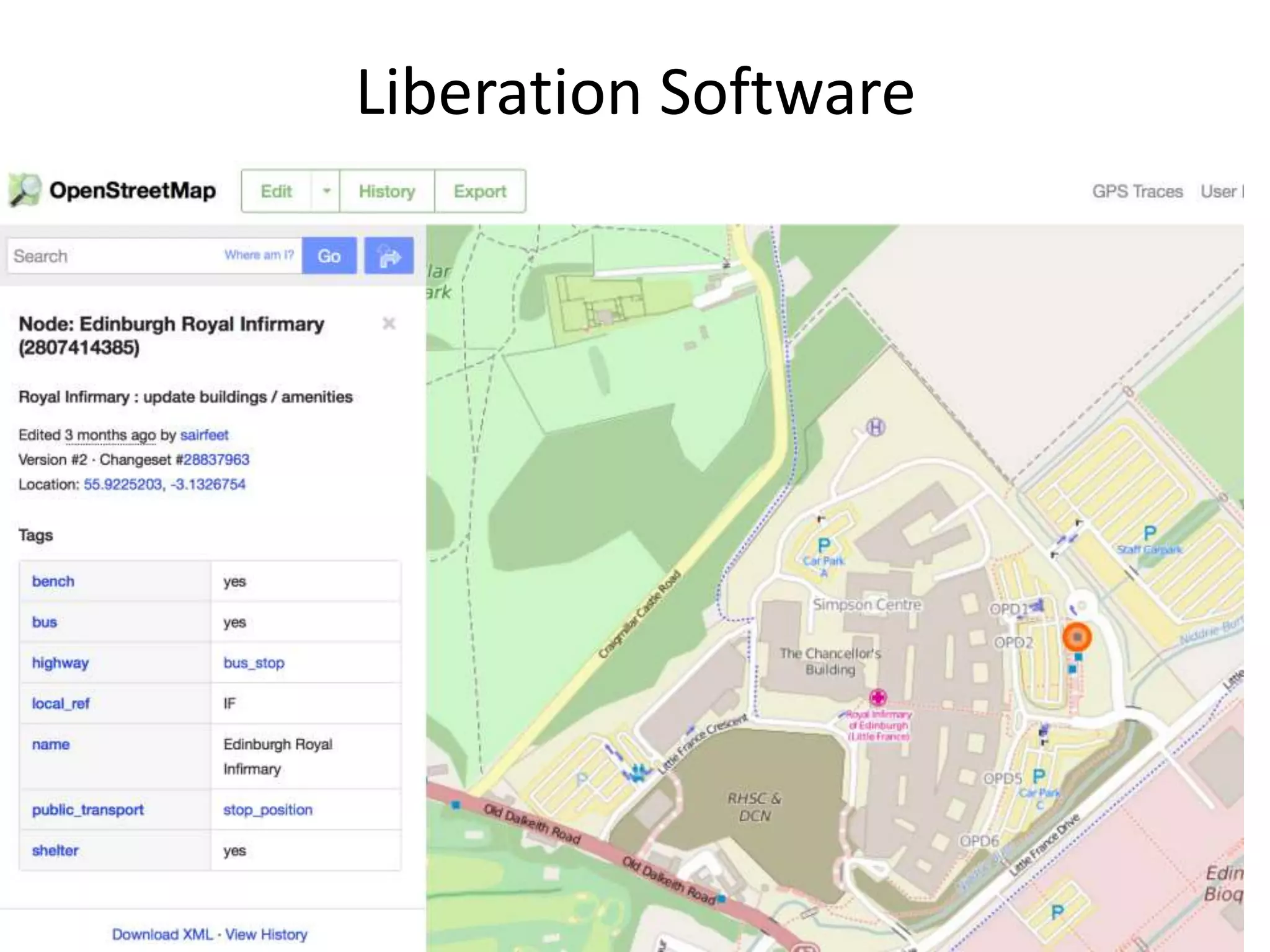
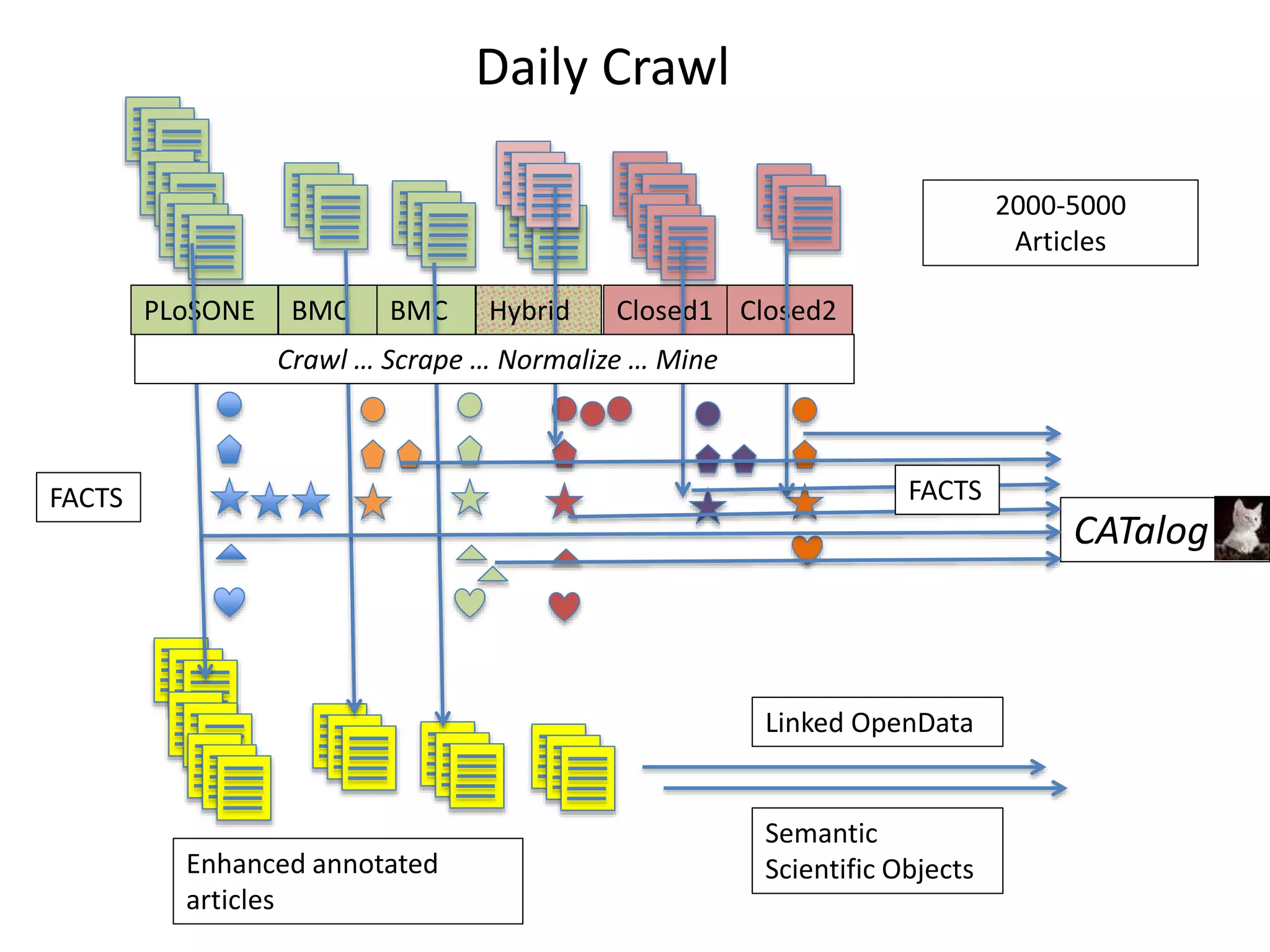
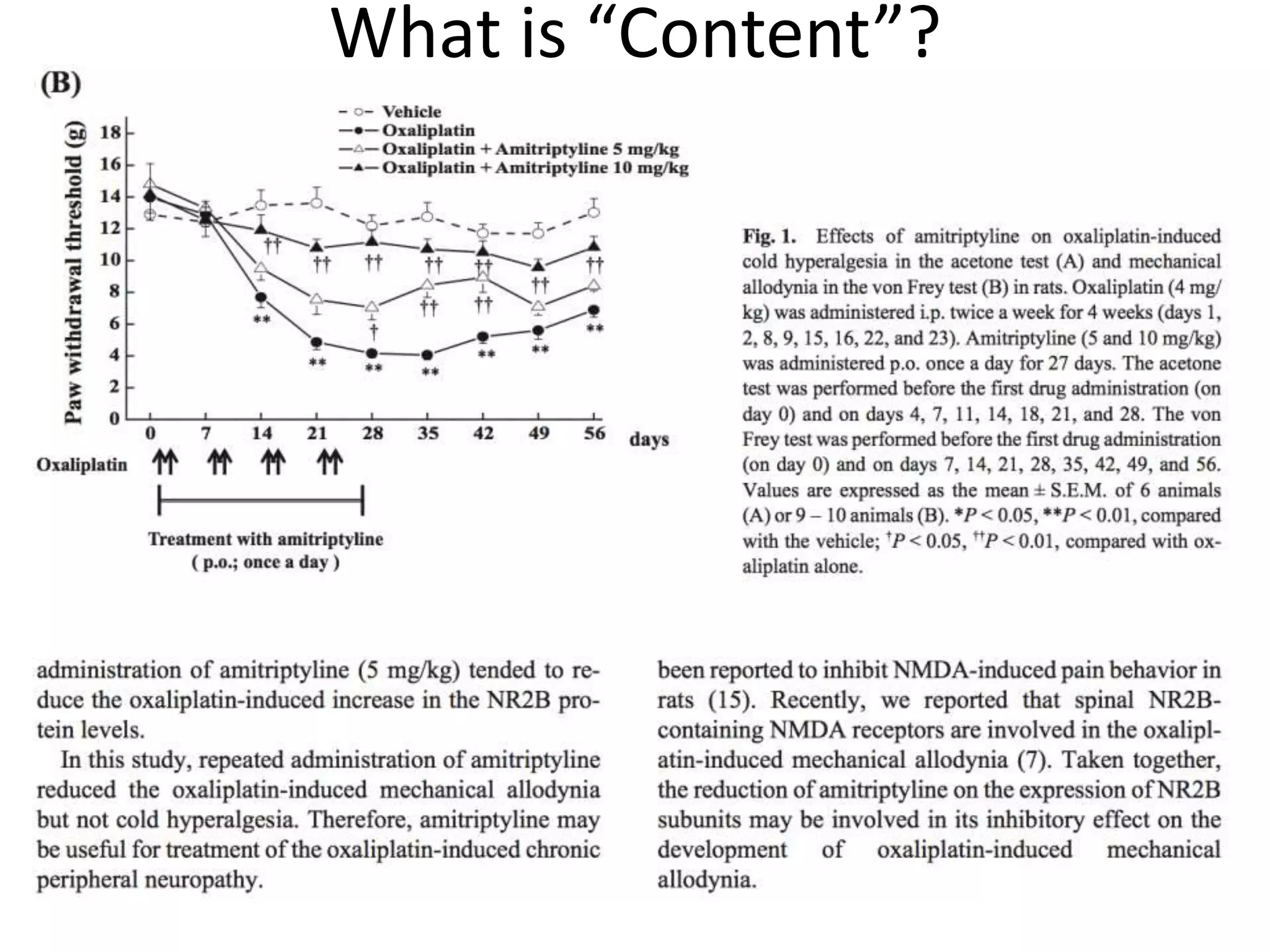
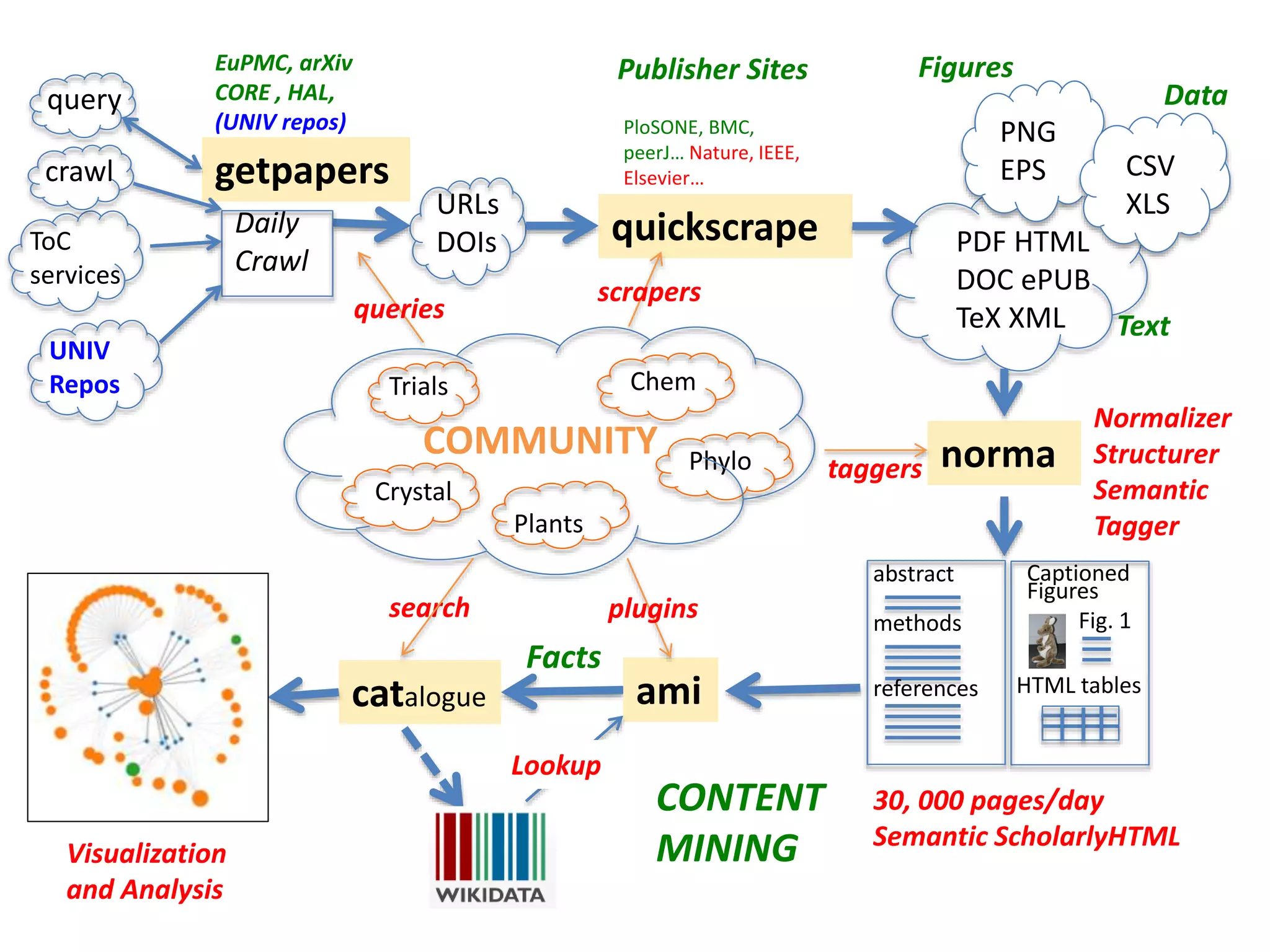
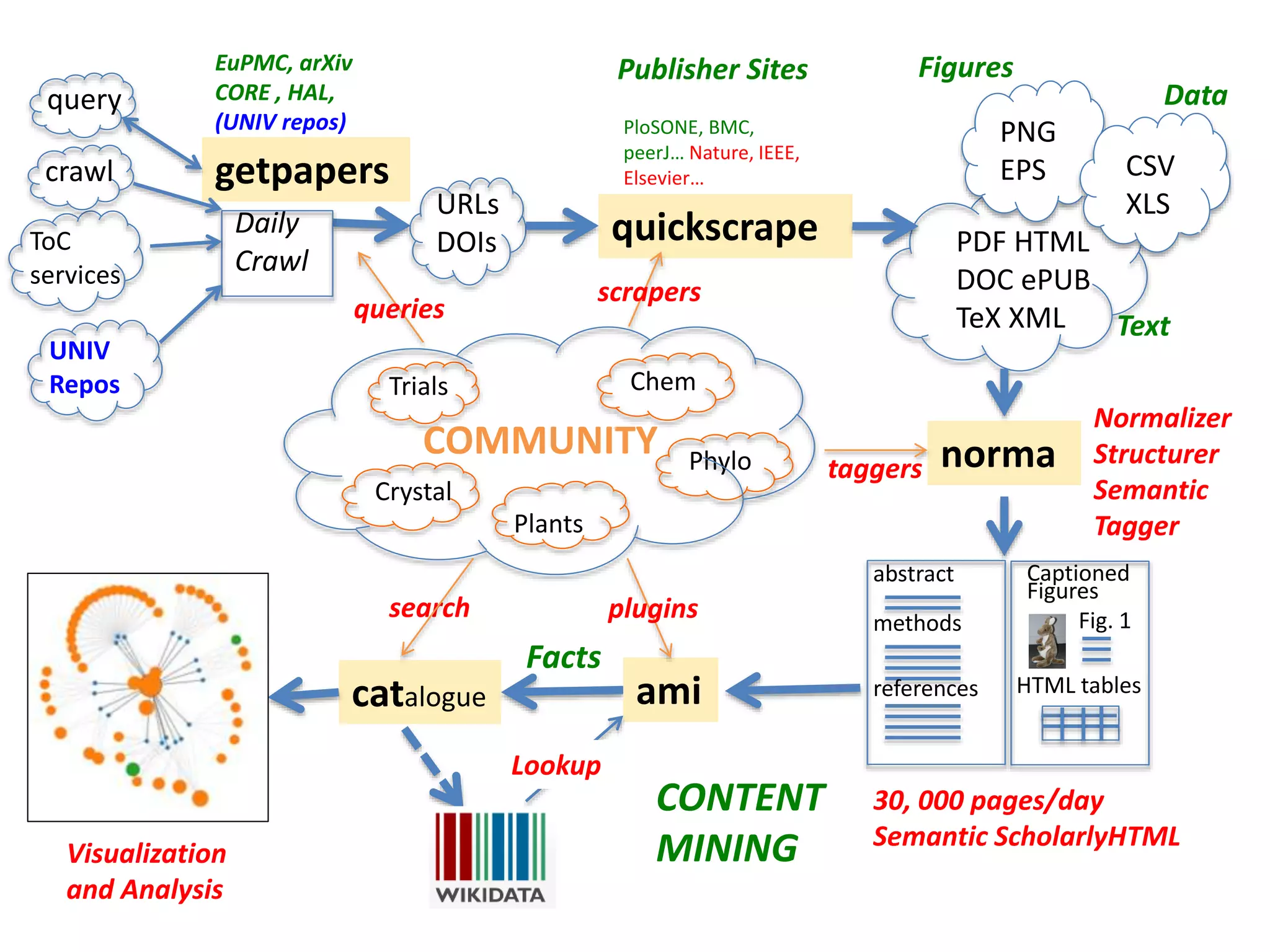
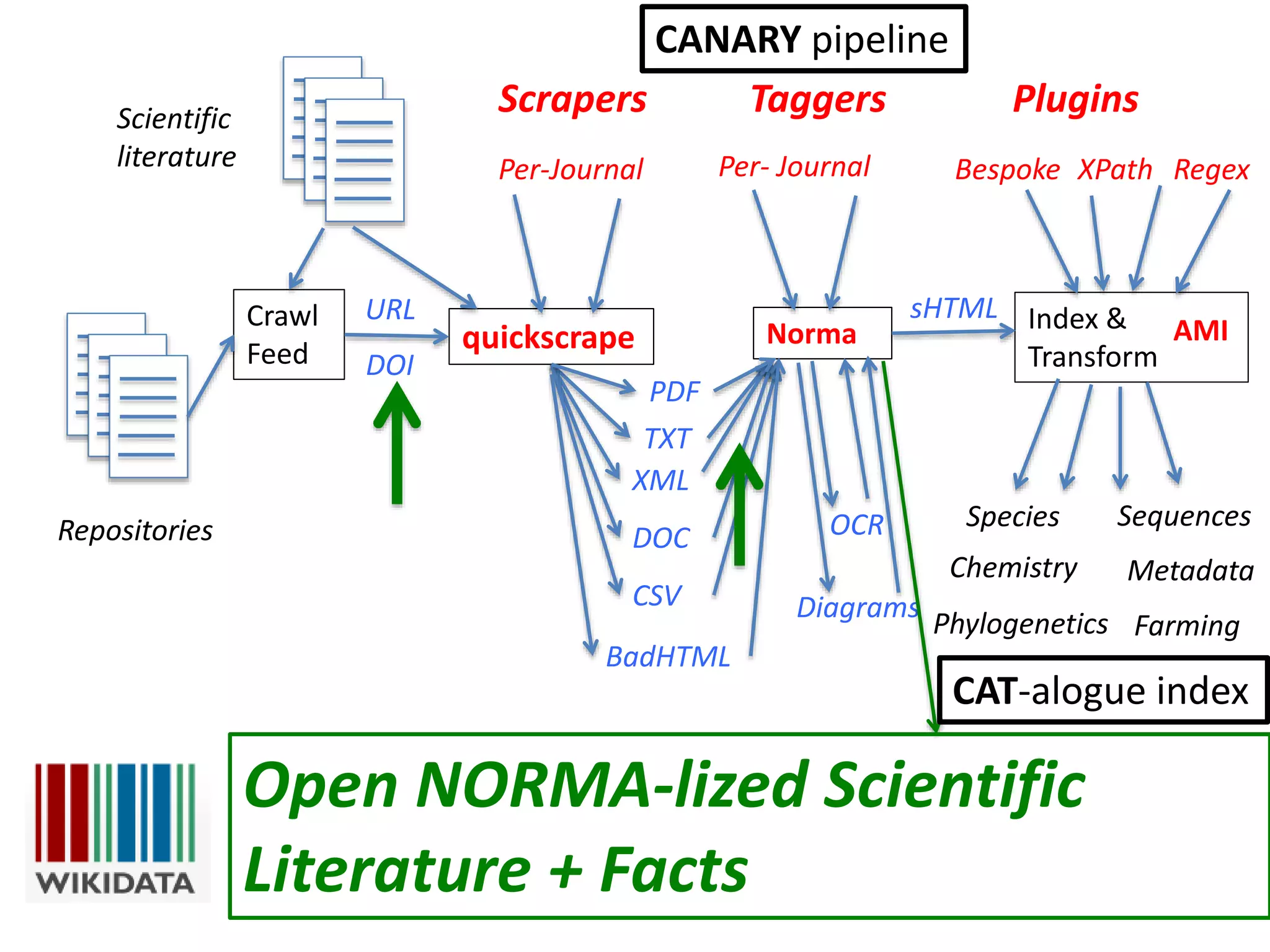
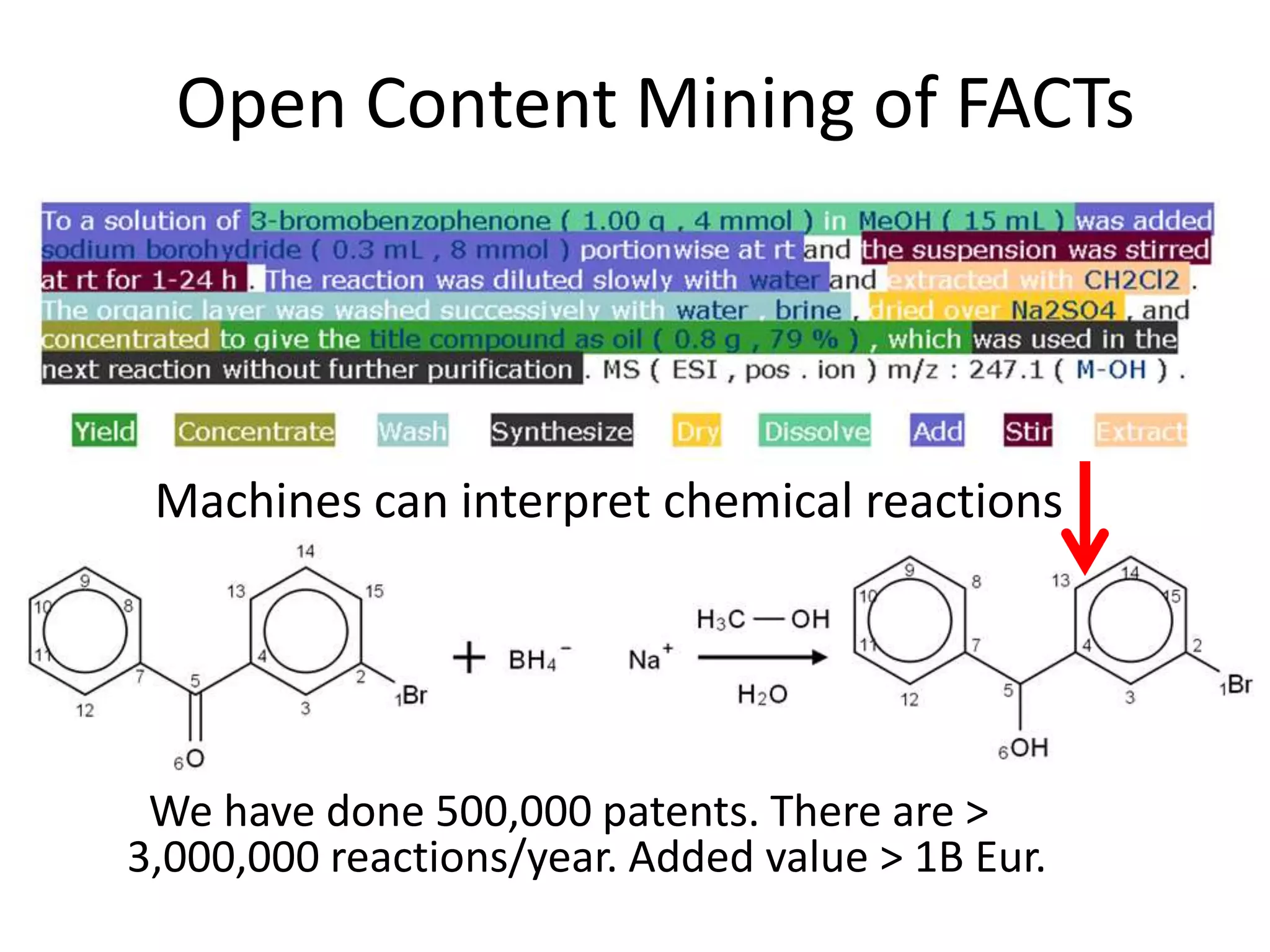
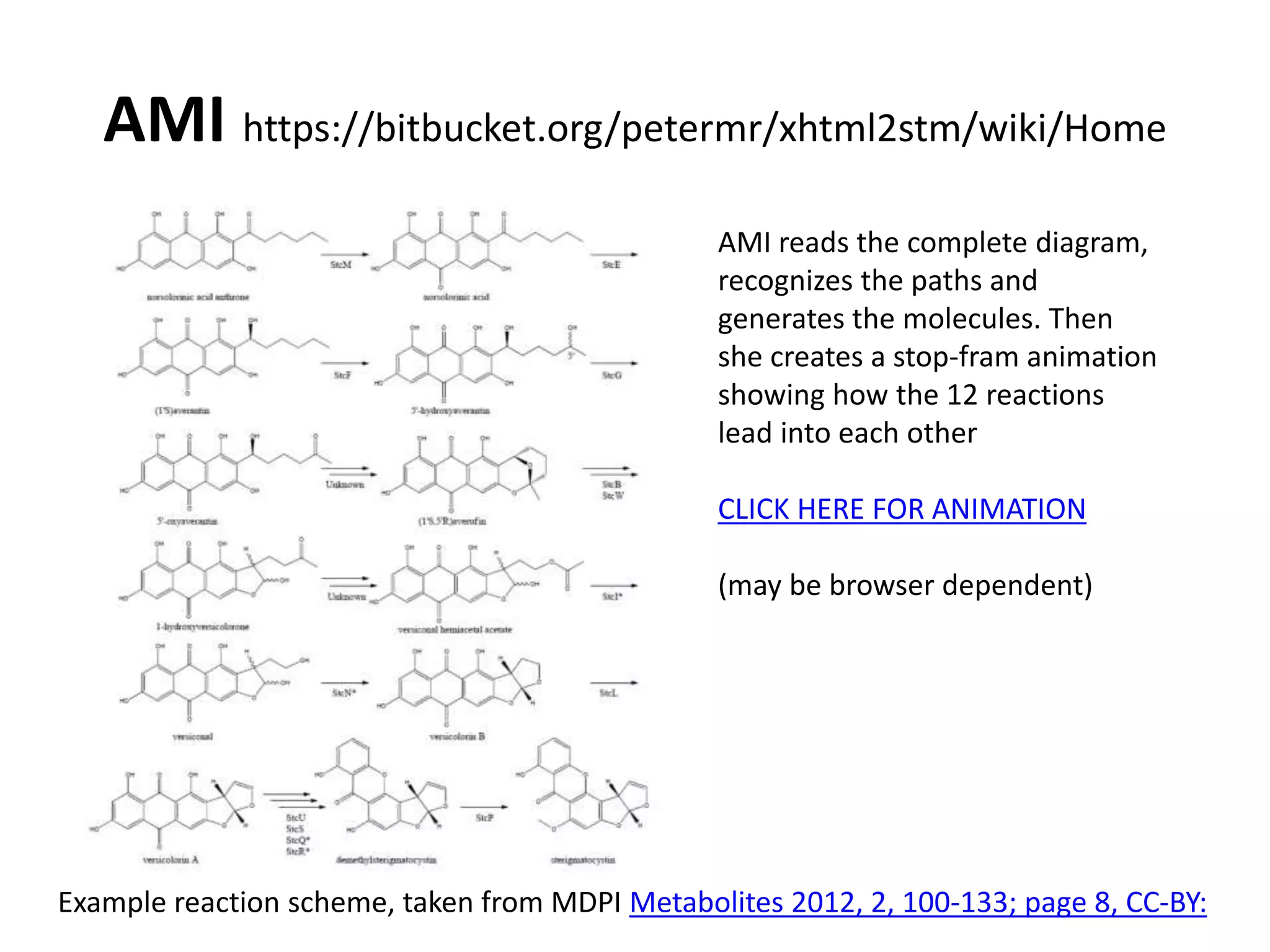
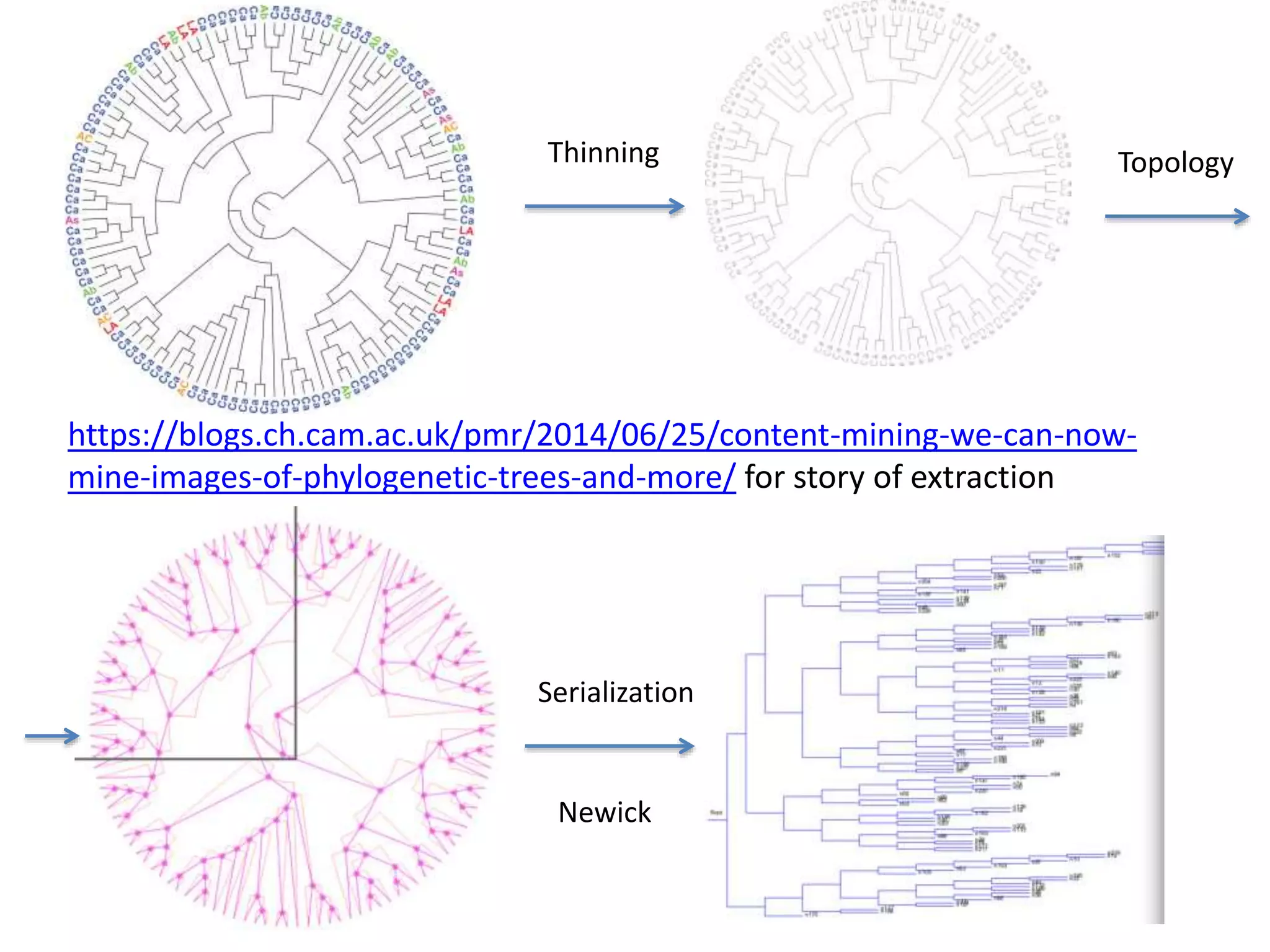
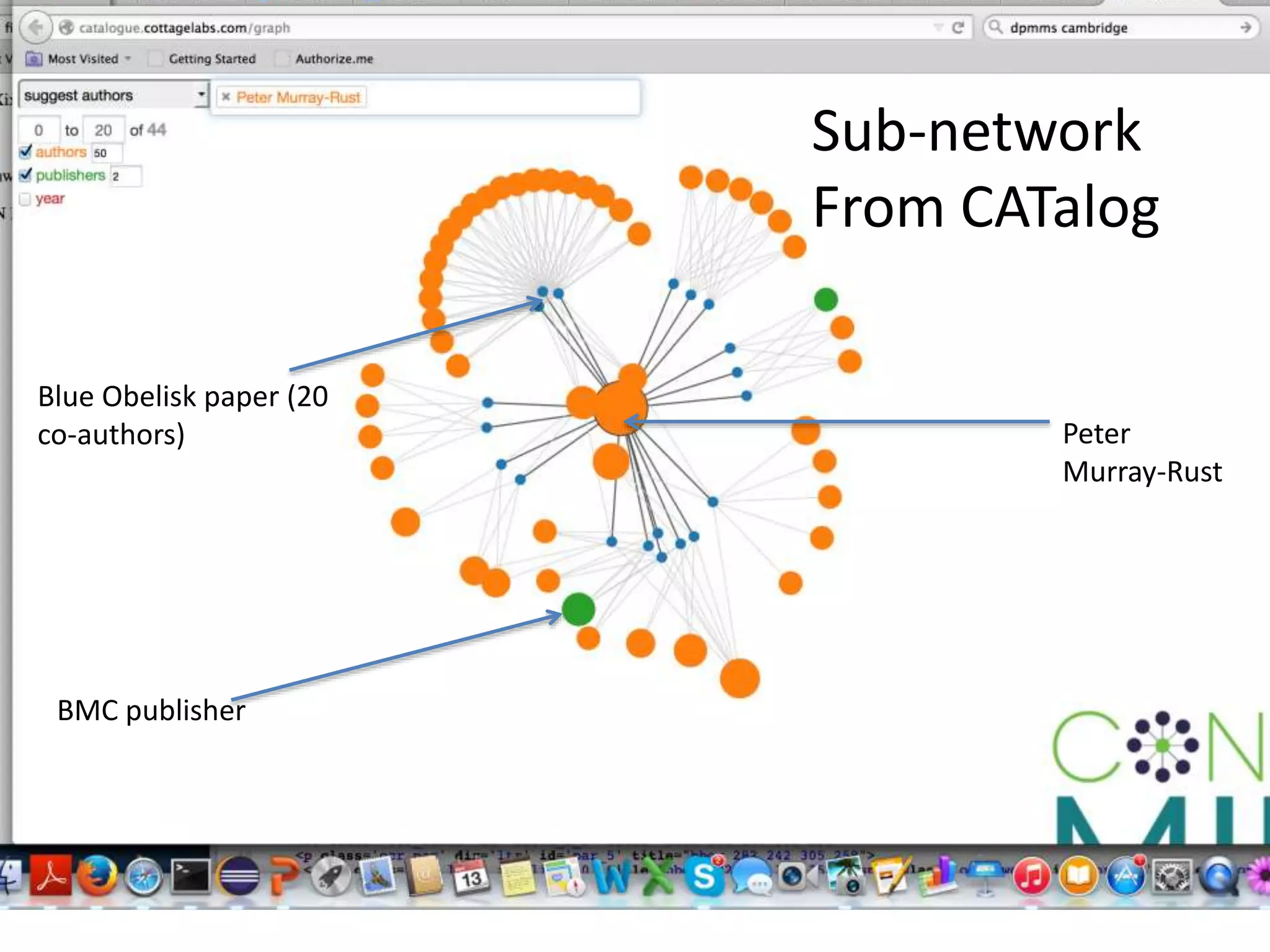
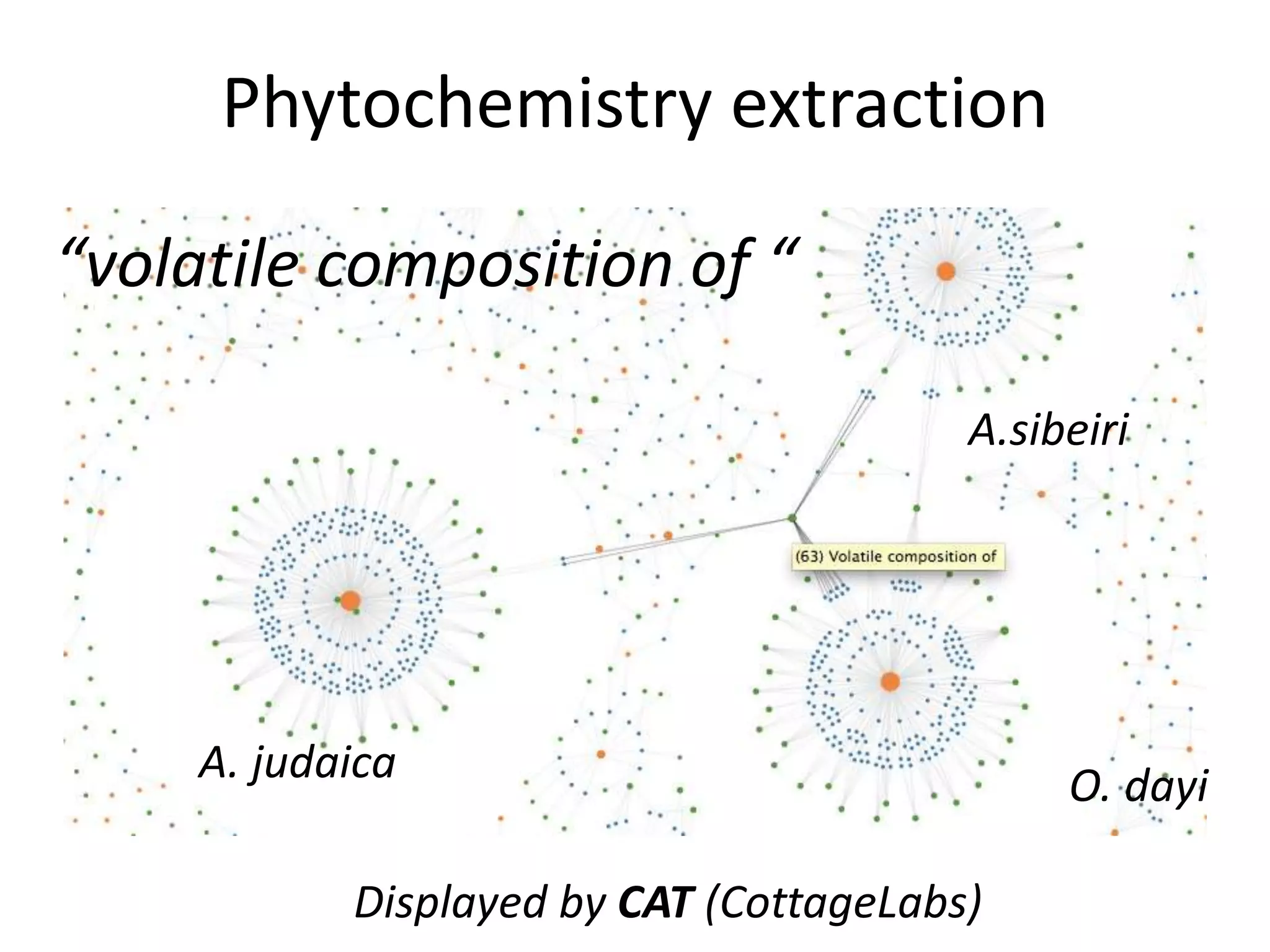
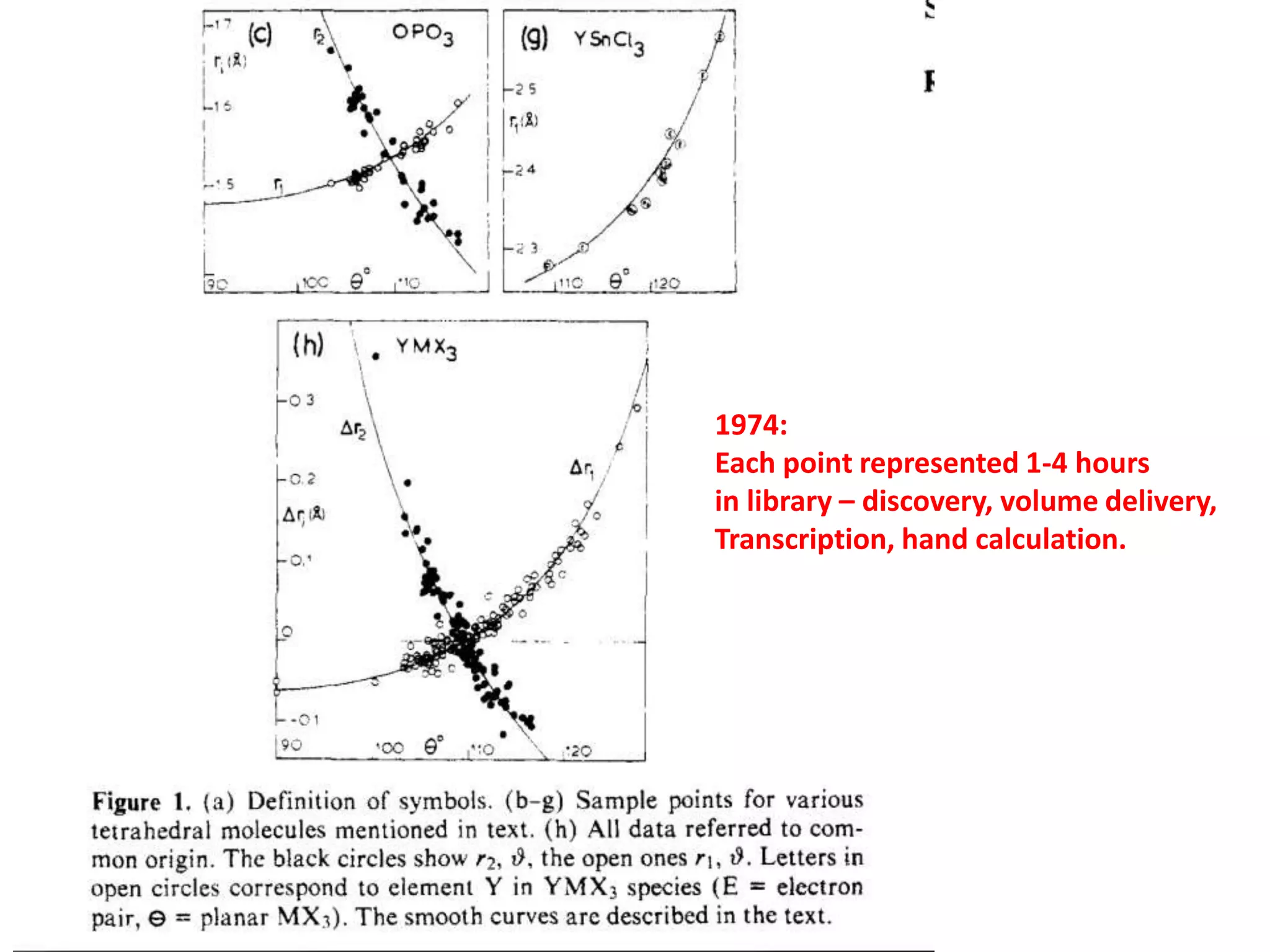
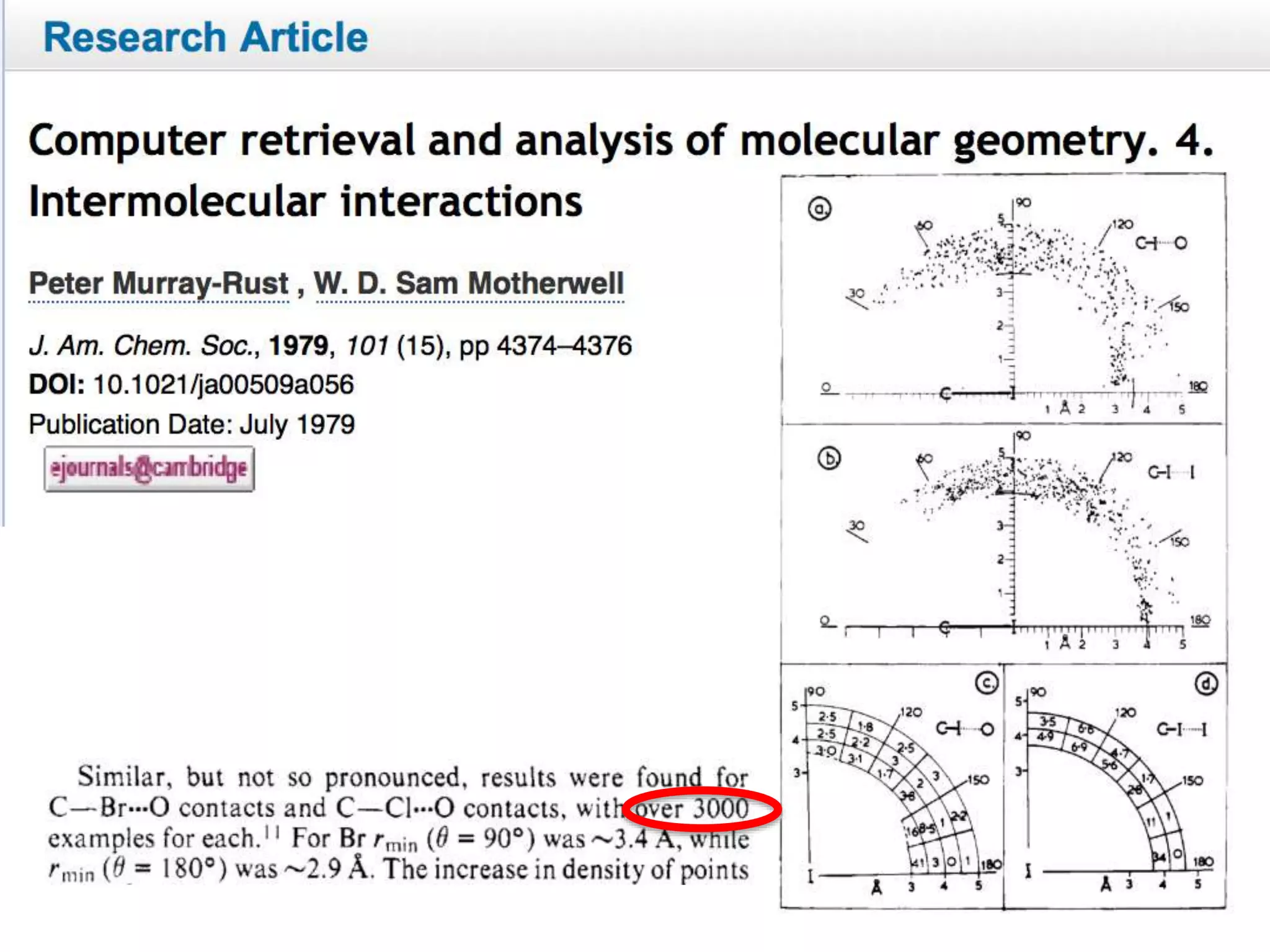
The document discusses the significant waste of publicly funded research due to the current practices in scholarly publishing, highlighting the need for open access to scientific literature. It emphasizes the inefficacy of traditional publishing models and the potential of content mining to enhance research accessibility and efficiency. Additionally, it critiques restrictive licensing practices imposed by publishers, which hinder innovative use of collected data.



![http://www.nytimes.com/2015/04/08/opinion/yes-we-were-warned-about-
ebola.html
We were stunned recently when we stumbled across an article by European
researchers in Annals of Virology [1982]: “The results seem to indicate that
Liberia has to be included in the Ebola virus endemic zone.” In the future,
the authors asserted, “medical personnel in Liberian health centers should be
aware of the possibility that they may come across active cases and thus be
prepared to avoid nosocomial epidemics,” referring to hospital-acquired
infection.
Adage in public health: “The road to inaction is paved with research
papers.”
Bernice Dahn (chief medical officer of Liberia’s Ministry of Health)
Vera Mussah (director of county health services)
Cameron Nutt (Ebola response adviser to Partners in Health)
A System Failure of Scholarly Publishing](https://image.slidesharecdn.com/plosslides-150710102657-lva1-app6892/75/Plosslides-6-2048.jpg)


![http://www.budapestopenaccessinitiative.org/read
… an unprecedented public good. …
… completely free and unrestricted access to [peer-
reviewed literature] by all scientists, scholars, teachers,
students, and other curious minds. …
…Removing access barriers to this literature will
accelerate research, enrich education, share the
learning of the rich with the poor and the poor with
the rich, make this literature as useful as it can be, and
lay the foundation for uniting humanity in a common
intellectual conversation and quest for knowledge.
(Budapest Open Access Initiative, 2003)](https://image.slidesharecdn.com/plosslides-150710102657-lva1-app6892/75/Plosslides-9-2048.jpg)
![Scientific and Medical publication (STM)[+]
• World Citizens pay $400,000,000,000…
• … for research in 1,500,000 articles …
• … cost $300,000 each to create …
• … $7000 each to “publish” [*]…
• … $10,000,000,000 from academic libraries …
• … to “publishers” who forbid access to 99.9% of citizens of
the world …
• 85% of medical research is wasted (not published, badly
conceived, duplicated, …)
[+] Figures probably +- 50 %
[*] arXiV preprint server costs $7 USD per paper](https://image.slidesharecdn.com/plosslides-150710102657-lva1-app6892/75/Plosslides-10-2048.jpg)
![• “creative use of these large data sets in the US health care sector
could generate more than $300bn in value per annum” [MGI,
McKinsey]
• Gartner Inc. has identified 'Big Data' and 'Next-Generation
Analytics' as two of the 'Top 10 Strategic Technologies' for 2012.
• Given the volume of text generated by business, academic and
social activities – in for example competitor reports, research
publications or customer opinions on social networking sites – text
mining is, however, highly important. [JISC]
• there are some tasks that simply could not be achieved without
using text mining. For example, a major pharmaceutical company
used text mining tools to evaluate 50,000 patents in 18 months.
This would have taken 50 person years to achieve manually,
meaning that it would not even have been contemplated. [JISC]
“Big Data – and Analytics (ContentMining)](https://image.slidesharecdn.com/plosslides-150710102657-lva1-app6892/75/Plosslides-11-2048.jpg)


![Elsevier wants to control Open Data
[asked by Michelle Brook]](https://image.slidesharecdn.com/plosslides-150710102657-lva1-app6892/75/Plosslides-14-2048.jpg)