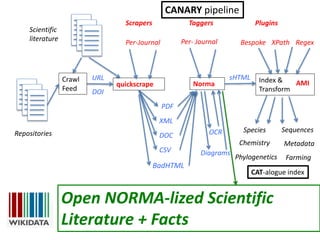
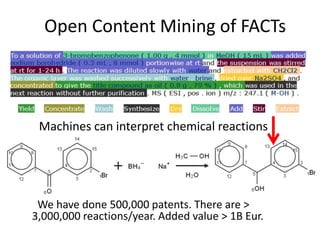
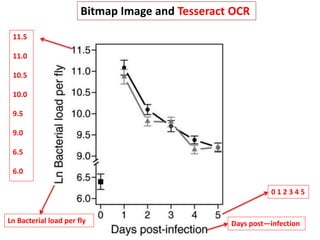
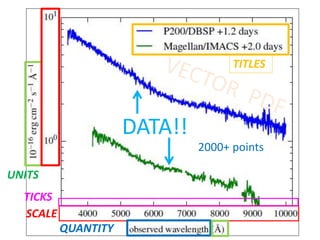
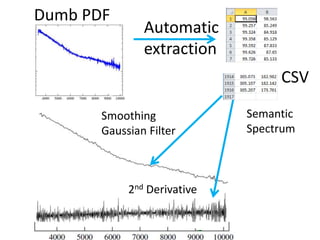
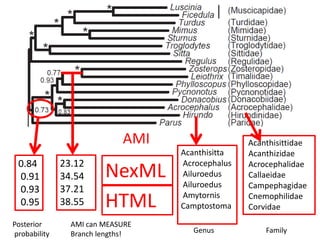
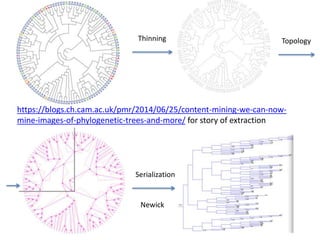
The document discusses the importance of mining bioscience literature to extract valuable scientific data hidden in various sources like articles and patents through the ContentMine platform. It emphasizes the inefficiencies and barriers in scholarly publishing that prevent access to research findings and presents a collaborative approach to make scientific knowledge more accessible and reusable. Additionally, it outlines the technical capabilities of ContentMine for data extraction, including its legal framework and community engagement in open science initiatives.


![http://www.nytimes.com/2015/04/08/opinion/yes-we-were-warned-about-
ebola.html
We were stunned recently when we stumbled across an article by European
researchers in Annals of Virology [1982]: “The results seem to indicate that
Liberia has to be included in the Ebola virus endemic zone.” In the future,
the authors asserted, “medical personnel in Liberian health centers should be
aware of the possibility that they may come across active cases and thus be
prepared to avoid nosocomial epidemics,” referring to hospital-acquired
infection.
Adage in public health: “The road to inaction is paved with research
papers.”
Bernice Dahn (chief medical officer of Liberia’s Ministry of Health)
Vera Mussah (director of county health services)
Cameron Nutt (Ebola response adviser to Partners in Health)
A System Failure of Scholarly Publishing](https://image.slidesharecdn.com/synbio-150518175559-lva1-app6891/85/ContentMining-for-Synthetic-Biology-2-320.jpg)
![Scientific and Medical publication (STM)[+]
• World Citizens pay $400,000,000,000…
• … for research in 1,500,000 articles …
• … cost $300,000 each to create …
• … $7000 each to “publish” [*]…
• … $10,000,000,000 from academic libraries …
• … to “publishers” who forbid access to 99.9% of citizens of
the world …
• 85% of medical research is wasted (not published, badly
conceived, duplicated, …)
[+] Figures probably +- 50 %
[*] arXiV preprint server costs $7 USD per paper](https://image.slidesharecdn.com/synbio-150518175559-lva1-app6891/85/ContentMining-for-Synthetic-Biology-3-320.jpg)









































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

















