Downloaded 33 times




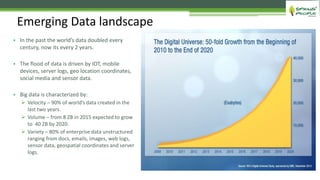

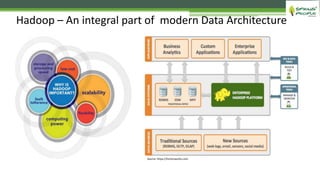

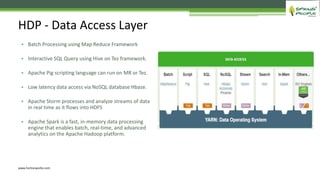
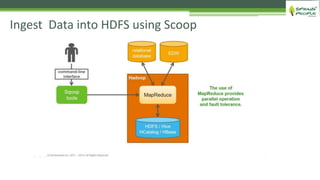
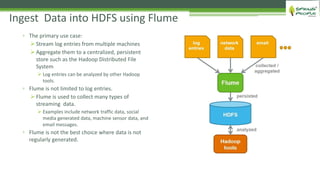
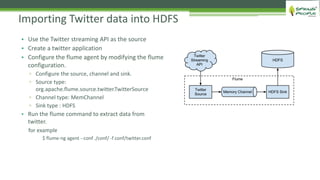
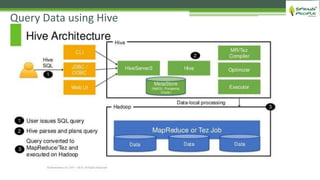


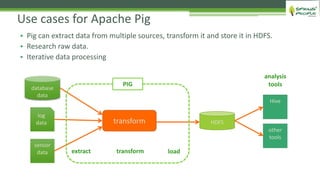

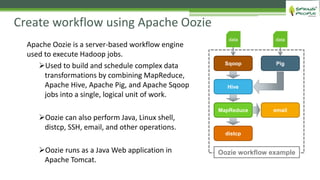
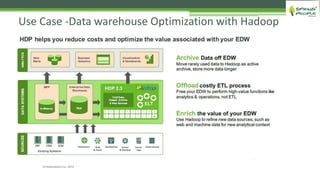


The document outlines the role of Hadoop in modern data architecture, highlighting its significance in handling big data through various components like MapReduce, Hive, and HBase. It emphasizes the growing need for efficient data processing and storage due to the rapid increase in data volume, variety, and velocity driven by technologies such as IoT and social media. Key use cases including data warehouse optimization demonstrate how Hadoop can enhance data insights and cost-effectiveness.























































































