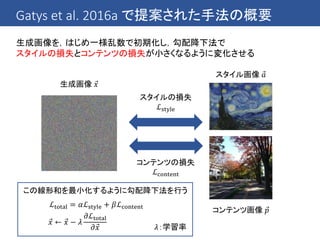
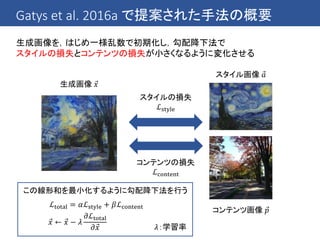
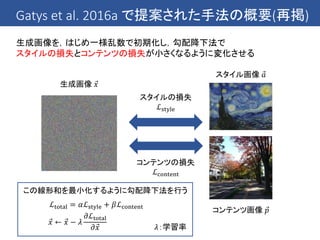
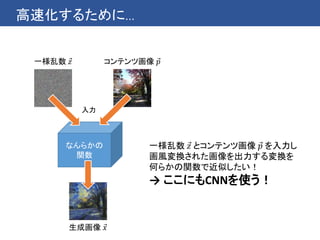
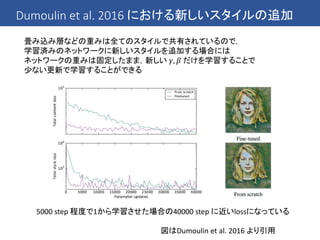
Dumoulin et al.2016 のアイディア
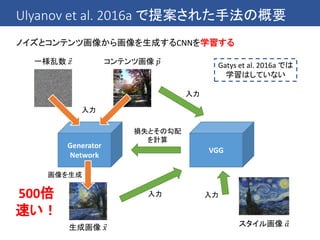
これまでの手法では1つのスタイルへの変換を1つのCNNで行っている
→ 複数のスタイルへの変換を1つのCNNで行うことはできないのか?
同じ画家の絵なら同じような筆遣いが見られる → ある程度共有できるはず!
19.
Dumoulin et al.2016 における発見
we found a very surprising fact about the role of normalization in style
transfer networks: to model a style, it is sufficient to specialize scaling and
shifting parameters after normalization to each specific style.
Dumoulin et al. 2016 より引用
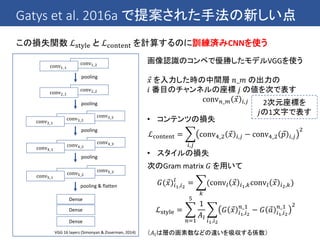
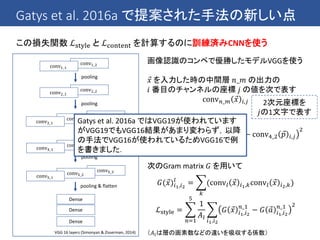
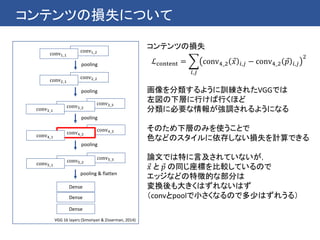
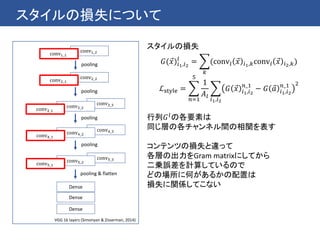
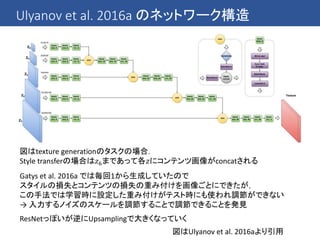
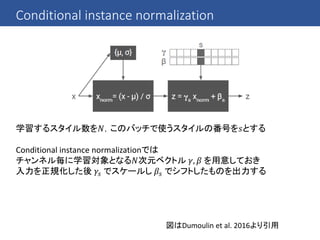
最近のCNNでは一般にBatch Normalizationというテクニックが使われている
→ 伝播してきたミニバッチの中で各次元の平均を0に分散を1にする
Batch Normalizationをかけた後に適当な定数を指定しておいて
これをスケールしたりシフトしたりすることがあるが
このスケールやシフトのパラメータを学習させてスタイル毎に切り替えるだけで
(他の畳み込み層などのパラメータは同じのままで)
複数のスタイルに変換することができるということを発見した
この発見に基づき conditional instance normalization を提案した
Reference III
絵の引用元
• Vincentvan Gogh - The Starry Night
https://commons.wikimedia.org/wiki/File:VanGogh-starry_night.jpg
• Claude Monet - Rouen Cathedral. Facade (Morning effect)
https://commons.wikimedia.org/wiki/File:Claude_Monet_-
_Rouen_Cathedral,_Facade_(Morning_effect).JPG
• Claude Monet - Poppy Field in Argenteuil
https://commons.wikimedia.org/wiki/File%3APoppy_Field_in_Argenteuil%2C_Claude_Monet.jpg
• Claude Monet - Plum Trees In Blossom At Vetheuil
https://www.wikiart.org/en/claude-monet/plum-trees-in-blossom-at-vetheuil
• Claude Monet - Les Nymphéas
https://commons.wikimedia.org/wiki/File:Claude_Monet_038.jpg




































![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Painting style transfer for head portraits using convolutional neural...](https://cdn.slidesharecdn.com/ss_thumbnails/180116dl-180208060727-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Freehand-Sketch to Image Synthesis 2018](https://cdn.slidesharecdn.com/ss_thumbnails/hozumi110918-181109001844-thumbnail.jpg?width=640&height=640&fit=bounds)

![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20210625robustnetlin-210625020332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)


