Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kenta Ishii
PPTX, PDF
347 views
Long short-term memory (LSTM)
東大羽藤研でのゼミ資料です. 交通行動の履歴依存性を検討するために元論文をレビューしました.
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 36
2
/ 36
Most read
3
/ 36
4
/ 36
5
/ 36
6
/ 36
Most read
7
/ 36
8
/ 36
9
/ 36
10
/ 36
11
/ 36
12
/ 36
13
/ 36
14
/ 36
15
/ 36
16
/ 36
17
/ 36
18
/ 36
19
/ 36
20
/ 36
21
/ 36
22
/ 36
23
/ 36
24
/ 36
25
/ 36
26
/ 36
27
/ 36
28
/ 36
29
/ 36
30
/ 36
31
/ 36
32
/ 36
33
/ 36
34
/ 36
35
/ 36
36
/ 36
More Related Content
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PPTX
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PDF
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
PPTX
【DL輪読会】Reward Design with Language Models
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PDF
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について
by
Yusuke Nakata
「世界モデル」と関連研究について
by
Masahiro Suzuki
音声合成のコーパスをつくろう
by
Shinnosuke Takamichi
【DL輪読会】Reward Design with Language Models
by
Deep Learning JP
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
What's hot
PDF
グラフデータ分析 入門編
by
順也 山口
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
PPTX
[DL輪読会]Whole-Body Human Pose Estimation in the Wild
by
Deep Learning JP
PPTX
畳み込みLstm
by
tak9029
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
情報抽出入門 〜非構造化データを構造化させる技術〜
by
Yuya Unno
PDF
最適輸送の解き方
by
joisino
PDF
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
by
Hori Tasuku
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PDF
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PPTX
【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PPTX
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
PDF
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
グラフデータ分析 入門編
by
順也 山口
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
by
Hitomi Yanaka
[DL輪読会]Whole-Body Human Pose Estimation in the Wild
by
Deep Learning JP
畳み込みLstm
by
tak9029
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
情報抽出入門 〜非構造化データを構造化させる技術〜
by
Yuya Unno
最適輸送の解き方
by
joisino
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
by
Hori Tasuku
近年のHierarchical Vision Transformer
by
Yusuke Uchida
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
数学で解き明かす深層学習の原理
by
Taiji Suzuki
【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
SHAP値の考え方を理解する(木構造編)
by
Kazuyuki Wakasugi
【DL輪読会】Implicit Behavioral Cloning
by
Deep Learning JP
Similar to Long short-term memory (LSTM)
PDF
Lstm shannonlab
by
Shannon Lab
PDF
[論文紹介] LSTM (LONG SHORT-TERM MEMORY)
by
Tomoyuki Hioki
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PDF
Rnn+lstmを理解する
by
Arata Honda
PPTX
Hybrid computing using a neural network with dynamic external memory
by
poppyuri
PPTX
ラビットチャレンジレポート 深層学習Day3
by
ssuserf4860b
PDF
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
PDF
Deep Learning
by
Masayoshi Kondo
PPTX
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
PPTX
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
by
Shotaro Sano
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
深層学習レポートDay3(小川成)
by
ssuser441cb9
PDF
Rnncamp2handout
by
Shin Asakawa
PDF
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
PDF
ニューラルネットワーク勉強会5
by
yhide
PDF
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
PPTX
Paper: seq2seq 20190320
by
Yusuke Fujimoto
PDF
20181123 seq gan_ sequence generative adversarial nets with policy gradient
by
h m
Lstm shannonlab
by
Shannon Lab
[論文紹介] LSTM (LONG SHORT-TERM MEMORY)
by
Tomoyuki Hioki
Recurrent Neural Networks
by
Seiya Tokui
LSTM (Long short-term memory) 概要
by
Kenji Urai
Rnn+lstmを理解する
by
Arata Honda
Hybrid computing using a neural network with dynamic external memory
by
poppyuri
ラビットチャレンジレポート 深層学習Day3
by
ssuserf4860b
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
Deep Learning
by
Masayoshi Kondo
深層学習による自然言語処理 第2章 ニューラルネットの基礎
by
Shion Honda
論文紹介:「End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF」
by
Naonori Nagano
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
by
Shotaro Sano
Deep Learningの基礎と応用
by
Seiya Tokui
深層学習レポートDay3(小川成)
by
ssuser441cb9
Rnncamp2handout
by
Shin Asakawa
ChainerによるRNN翻訳モデルの実装+@
by
Yusuke Oda
ニューラルネットワーク勉強会5
by
yhide
Scikit-learn and TensorFlow Chap-14 RNN (v1.1)
by
孝好 飯塚
Paper: seq2seq 20190320
by
Yusuke Fujimoto
20181123 seq gan_ sequence generative adversarial nets with policy gradient
by
h m
Long short-term memory (LSTM)
1.
LONG SHORT-TERM MEMORY 理論談話会2020 6月16日 M2
石井 健太 Hochreiter, S., & Schmidhuber, J. (1997). Neural computation, 9(8), 1735-1780.
2.
はじめに 時系列データを扱うためのニューラルネットの構造を提案. 既往研究では扱うことが難しかった,長期的にわたる関係性も考慮できるよう, CEC・入力ゲート・出力ゲートという3つの構造を導入している. 実験により,長期短期双方の関係性を考慮したうえで予測可能なことを証明した. 2 LONG SHORT-TERM MEMORY 要旨 交通分野での用途 •
交通量予測 (Toon Bogaerts et al. 2020など) • オンデマンド交通の逐次需要予測 (Jintao Ke et al. 2017など) • レーン変更選択モデル (Xiaohui Zhang et al. 2019など) • GPSデータからの交通機関特定 (Sina Dabiri et al. 2020) • 災害時の交通レジリエンスの時空間パターン推定・予測 (Hong-Wei Wang et al. 2020) などなど
3.
はじめに 3 LONG SHORT-TERM
MEMORY 1. Introduction 2. Previous work 3. Constant error backprop 4. Long short-term memory 5. Experiments 6. Discussion 7. Conclusion 論文構成
4.
目次 1. 順伝播型ネットワーク 2. Recurrent
neural network 3. Long Short-Term Memory 4 LONG SHORT-TERM MEMORY
5.
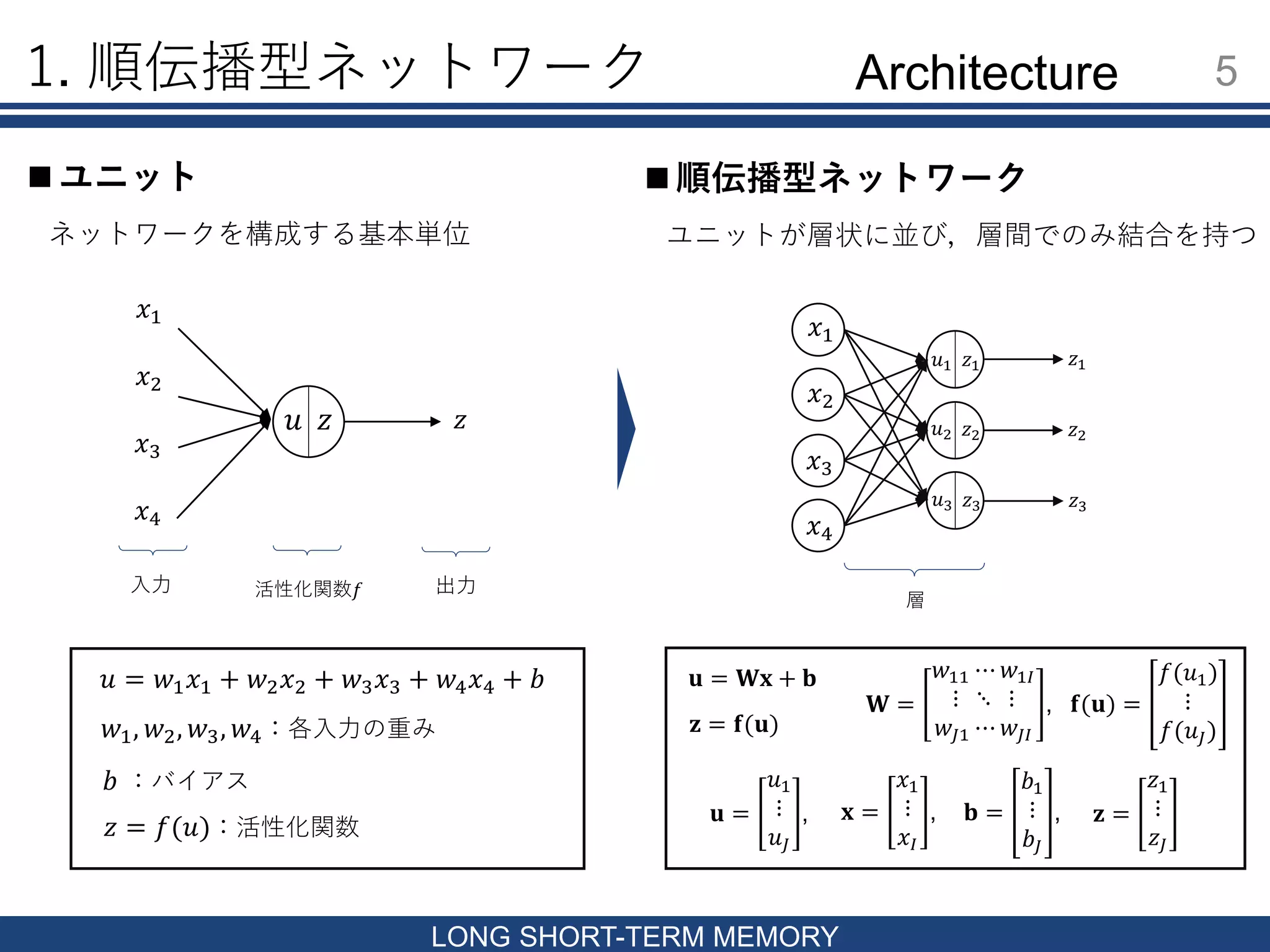
𝑧2 𝑥1 𝑥2 𝑥3 𝑥4 𝑧1 𝑢2 𝑧3 1. 順伝播型ネットワーク 5 LONG
SHORT-TERM MEMORY ユニット 𝑢 𝑥1 𝑥2 𝑥3 𝑥4 𝑧 𝑢 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑤3 𝑥3 + 𝑤4 𝑥4 + 𝑏 𝑧 = 𝑓(𝑢):活性化関数 入力 活性化関数𝑓 出力 𝑤1, 𝑤2, 𝑤3, 𝑤4:各入力の重み 𝑏 :バイアス ネットワークを構成する基本単位 𝑧 𝑢1 𝑢3 𝑧2 𝑧1 𝑧3 層 順伝播型ネットワーク ユニットが層状に並び,層間でのみ結合を持つ 𝐮 = 𝐖𝐱 + 𝐛 𝐳 = 𝐟(𝐮) 𝐮 = 𝑢1 ⋮ 𝑢𝐽 , 𝐱 = 𝑥1 ⋮ 𝑥𝐼 , 𝐛 = 𝑏1 ⋮ 𝑏𝐽 , 𝐳 = 𝑧1 ⋮ 𝑧𝐽 𝐖 = 𝑤11 ⋯ 𝑤1𝐼 ⋮ ⋱ ⋮ 𝑤𝐽1 ⋯ 𝑤𝐽𝐼 , 𝐟(𝐮) = 𝑓(𝑢1) ⋮ 𝑓(𝑢𝐽) Architecture
6.
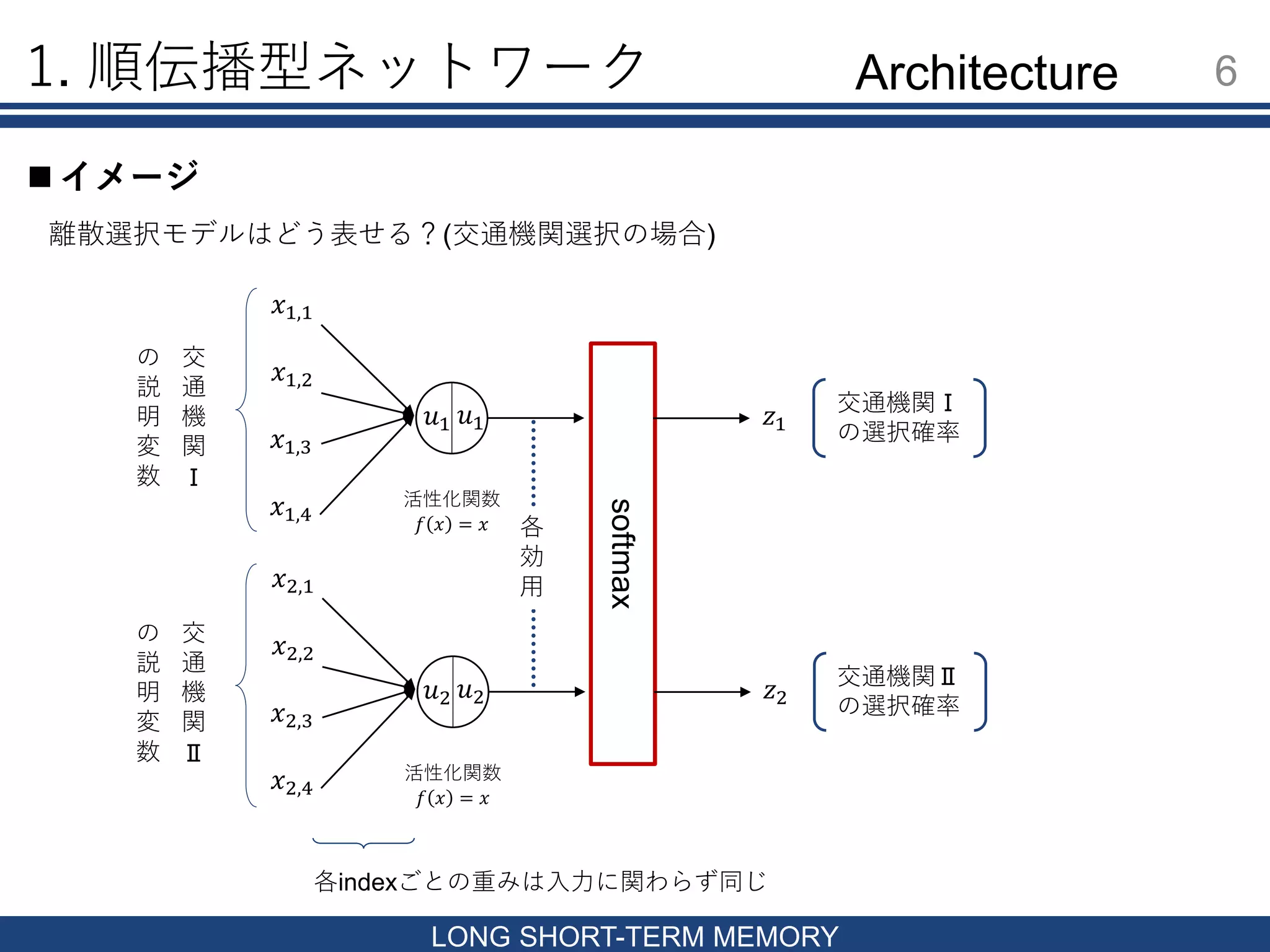
𝑢2 𝑢1 softmax 1. 順伝播型ネットワーク 6 LONG
SHORT-TERM MEMORY イメージ 𝑢1 𝑥1,1 𝑥1,2 𝑥1,3 𝑥1,4 𝑧1 活性化関数 𝑓 𝑥 = 𝑥 離散選択モデルはどう表せる?(交通機関選択の場合) 𝑥2,1 𝑥2,2 𝑥2,3 𝑥2,4 𝑧2 活性化関数 𝑓 𝑥 = 𝑥 交 通 機 関 Ⅰ の 説 明 変 数 交 通 機 関 Ⅱ の 説 明 変 数 𝑢2 交通機関Ⅰ の選択確率 交通機関Ⅱ の選択確率 各indexごとの重みは入力に関わらず同じ 各 効 用 Architecture
7.
クロスエントロピー誤差 1. 順伝播型ネットワーク 7 LONG
SHORT-TERM MEMORY 損失関数:訓練データとの近さを表す尺度 出力の数によって異なり,訓練データの統計的性質に応じて選ぶのが理想. 以下に代表的なものを挙げる. 1. 回帰:主に出力が連続値をとる関数が目的関数の場合 2.多クラス分類:出力が複数次元の関数の場合 𝐸 𝐰 = 1 2 𝑛=1 𝑁 𝐝 𝑛 − 𝒚(𝐱 𝑛; 𝐰) 2 𝐱 𝑛, 𝐝 𝑛 :訓練データの𝑛番目のサンプル 𝐱 𝑛:訓練データの入力 𝐝 𝑛:訓練データの出力 二乗誤差 𝐸 𝐰 = − 𝑛=1 𝑁 𝑘=1 𝐾 𝑑 𝑛𝑘 log 𝑦 𝑘(𝐱 𝑛; 𝐰) ソフトマックス関数を通す 𝒚(𝐱 𝑛; 𝐰):関数の出力 𝐾:出力層の次元 (1) (2)
8.
1. 順伝播型ネットワーク 8 LONG
SHORT-TERM MEMORY 誤差逆伝播法 層が深くなる (多くなる) と,出力層で計算される誤差を入力層に近い層まで伝える必要がある 例) 1つの訓練サンプル 𝐱 𝑛, 𝐝 𝑛 に対する二乗誤差𝐸 𝑛を考える 𝐸 𝑛 = 1 2 𝒚 𝐱 𝑛 − 𝐝 𝑛 2 第 𝑙層の重みの1成分 𝑤𝑗𝑖 (𝑙) の更新のため, 𝐸 𝑛を𝑤𝑗𝑖 (𝑙) で偏微分する 𝜕𝐸 𝑛 𝜕𝑤𝑗𝑖 (𝑙) = 𝒚 𝐱 𝑛 − 𝐝 𝑛 T 𝜕𝑦 𝜕𝑤𝑗𝑖 (𝑙) 𝒚 𝒙 = 𝐟(𝒖(𝐿) ) = 𝐟(𝐖(𝐿) 𝒛(𝐿−1) + 𝐛(𝐿) ) = 𝐟(𝐖 𝐿 𝐟(𝐖(𝐿−1) 𝒛(𝐿−𝟐) + 𝐛(𝐿−1) ) + 𝐛(𝐿) ) 𝑤𝑗𝑖 (𝑙) は活性化関数の深い入れ子の中に現れる 微分の連鎖規則を繰り返し用いる必要がある ・プログラミングが面倒 ・計算量が大きい 誤差逆伝播法の出現 𝐿:モデルの層数 (第𝐿層は最も出力に近い層) (3)
9.
1. 順伝播型ネットワーク 9 LONG
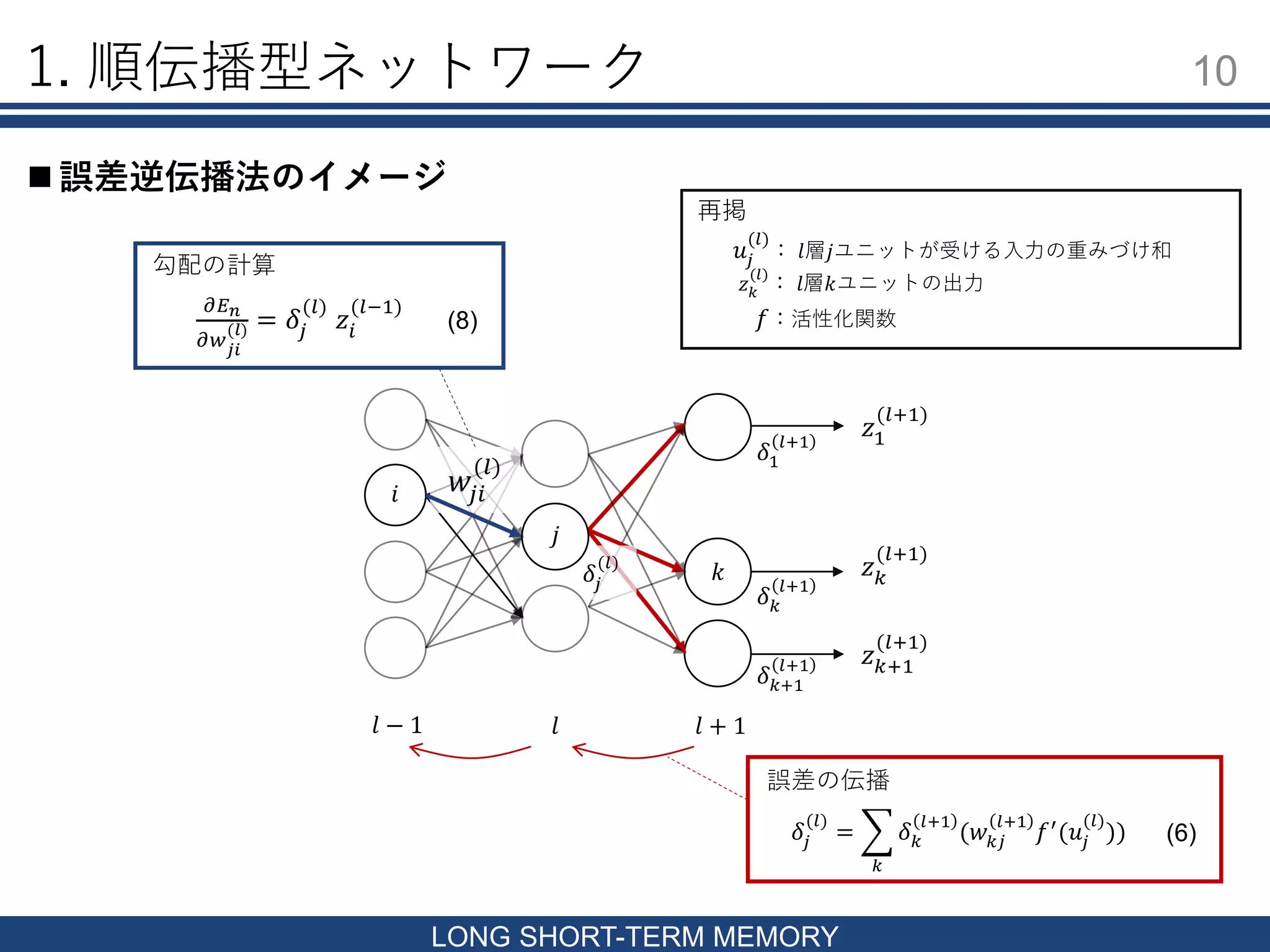
SHORT-TERM MEMORY 誤差逆伝播法 出力層から順に勾配を計算し,入力層まで伝播する手法 (向きが予測方向と逆) 第 𝑙層の重みの1成分 𝑤𝑗𝑖 (𝑙) に関する勾配を考える 𝜕𝐸 𝑛 𝜕𝑤𝑗𝑖 (𝑙) = 𝜕𝐸 𝑛 𝜕𝑢𝑗 (𝑙) 𝜕𝑢𝑗 (𝑙) 𝜕𝑤𝑗𝑖 (𝑙) 𝜕𝐸 𝑛 𝜕𝑢𝑗 (𝑙) = 𝑘 𝜕𝐸 𝑛 𝜕𝑢 𝑘 (𝑙+1) 𝜕𝑢 𝑘 (𝑙+1) 𝜕𝑢𝑗 (𝑙) 𝛿𝑗 (𝑙) ≡ 𝜕𝐸 𝑛 𝜕𝑢 𝑗 (𝑙) と置く 𝛿𝑗 (𝑙) = 𝑘 𝛿 𝑘 𝑙+1 (𝑤 𝑘𝑗 𝑙+1 𝑓′ (𝑢𝑗 (𝑙) )) 𝜕𝑢𝑗 (𝑙) 𝜕𝑤𝑗𝑖 (𝑙) = 𝑧𝑖 (𝑙−1) (∵ 𝑢𝑗 𝑙 = 𝑖 𝑤𝑗𝑖 𝑙 𝑧𝑖 𝑙−1 ) 𝜕𝐸 𝑛 𝜕𝑤 𝑗𝑖 (𝑙) = 𝛿𝑗 (𝑙) 𝑧𝑖 (𝑙−1) ◦誤差の伝播 ◦勾配の計算 層間の誤差伝播式と その誤差を用いた各重みに関する勾配を求める (4) (4)に代入して (5) (6) (7) (8)
10.
1. 順伝播型ネットワーク 10 LONG
SHORT-TERM MEMORY 誤差逆伝播法のイメージ 𝑙 + 1𝑙 𝛿𝑗 (𝑙) = 𝑘 𝛿 𝑘 𝑙+1 (𝑤 𝑘𝑗 𝑙+1 𝑓′ (𝑢𝑗 (𝑙) )) 𝜕𝐸 𝑛 𝜕𝑤 𝑗𝑖 (𝑙) = 𝛿𝑗 (𝑙) 𝑧𝑖 (𝑙−1) 𝑖 𝛿 𝑘 𝑙+1 𝛿 𝑘+1 𝑙+1 𝛿1 𝑙+1 𝑘 𝑧 𝑘 (𝑙+1) 𝑧 𝑘+1 (𝑙+1) 𝑧1 (𝑙+1) 𝑤𝑗𝑖 (𝑙) 勾配の計算 𝛿𝑗 (𝑙) 𝑗 誤差の伝播 𝑙 − 1 再掲 𝑓:活性化関数 𝑢𝑗 (𝑙) : 𝑙層𝑗ユニットが受ける入力の重みづけ和 𝑧 𝑘 (𝑙) : 𝑙層𝑘ユニットの出力 (6) (8)
11.
11 LONG SHORT-TERM MEMORY
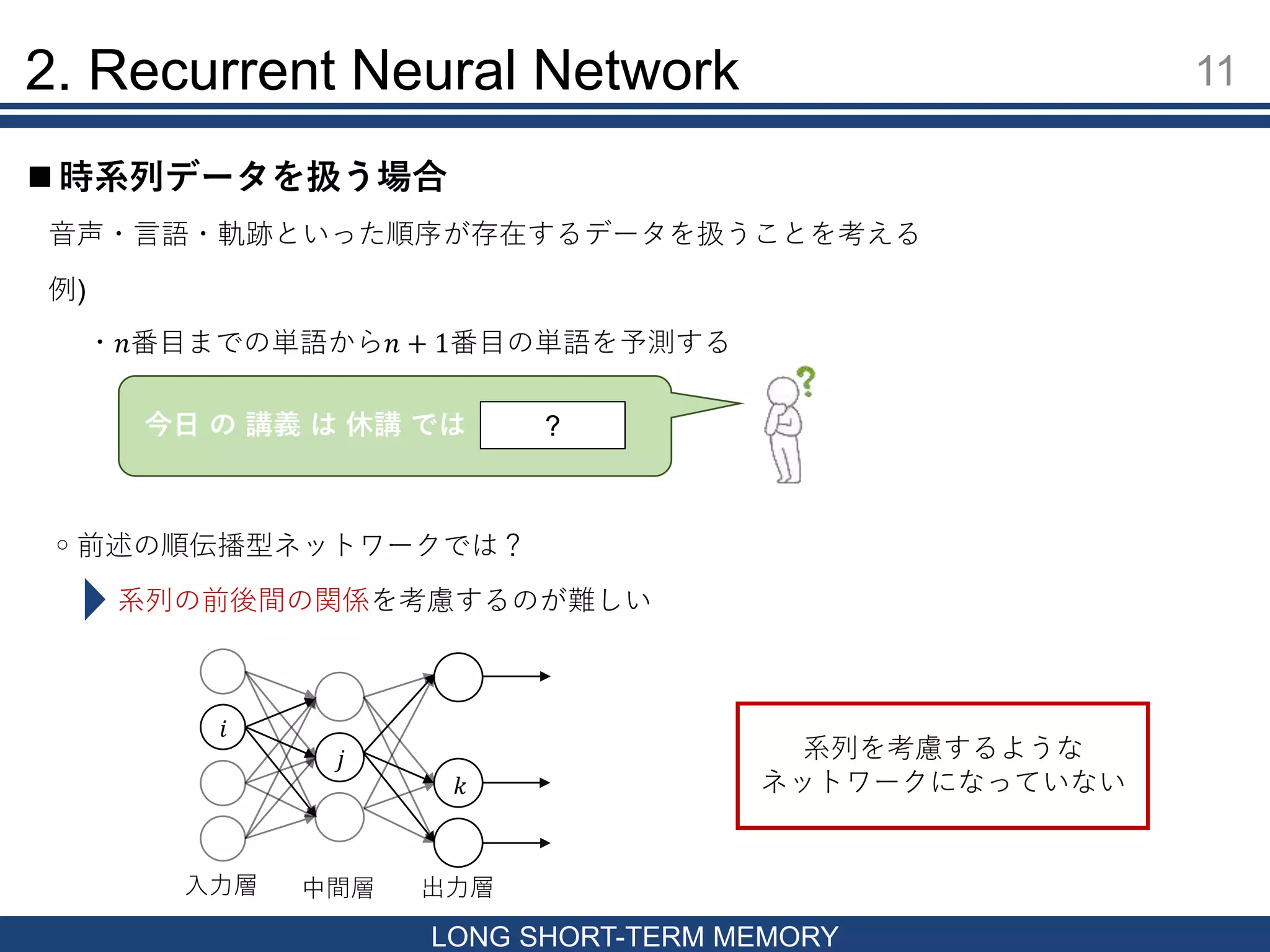
時系列データを扱う場合 2. Recurrent Neural Network 音声・言語・軌跡といった順序が存在するデータを扱うことを考える ◦前述の順伝播型ネットワークでは? 系列の前後間の関係を考慮するのが難しい 例) ・𝑛番目までの単語から𝑛 + 1番目の単語を予測する 今日 の 講義 は 休講 では ? 𝑖 𝑘 𝑗 系列を考慮するような ネットワークになっていない 入力層 中間層 出力層
12.
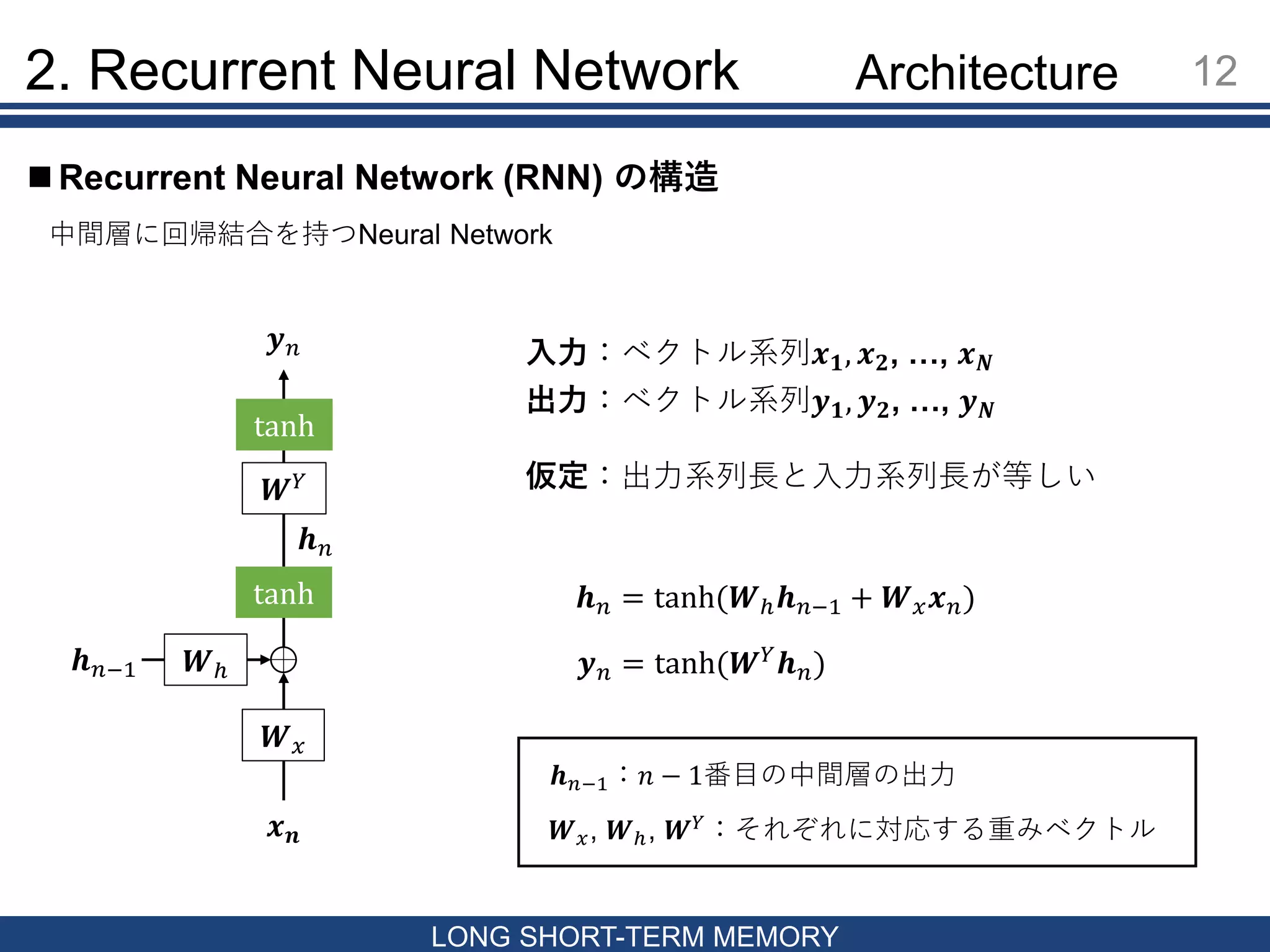
12 LONG SHORT-TERM MEMORY
Recurrent Neural Network (RNN) の構造 2. Recurrent Neural Network 中間層に回帰結合を持つNeural Network 𝒙 𝒏 𝒉 𝑛−1 𝒉 𝑛 𝑾ℎ 𝑾 𝑥 𝒉 𝑛 = tanh(𝑾ℎ 𝒉 𝑛−1 + 𝑾 𝑥 𝒙 𝑛) 𝑾 𝑌 tanh tanh 𝒚 𝑛 入力:ベクトル系列𝒙 𝟏, 𝒙 𝟐, …, 𝒙 𝑵 出力:ベクトル系列𝒚 𝟏, 𝒚 𝟐, …, 𝒚 𝑵 仮定:出力系列長と入力系列長が等しい 𝒚 𝑛 = tanh(𝑾 𝑌 𝒉 𝑛) 𝒉 𝑛−1:𝑛 − 1番目の中間層の出力 𝑾 𝑥, 𝑾ℎ, 𝑾 𝑌 :それぞれに対応する重みベクトル Architecture
13.
13 LONG SHORT-TERM MEMORY
RNNの誤差逆伝播 2. Recurrent Neural Network 前時期の中間層まで誤差を返す必要がある 𝒙 𝑵−𝟏 𝒉 𝑁−1 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁−1 𝒙 𝑵−𝟐 𝒉 𝑁−3 𝒉 𝑁−2 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁−2 𝒙 𝑵 𝒉 𝑁 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁 Architecture
14.
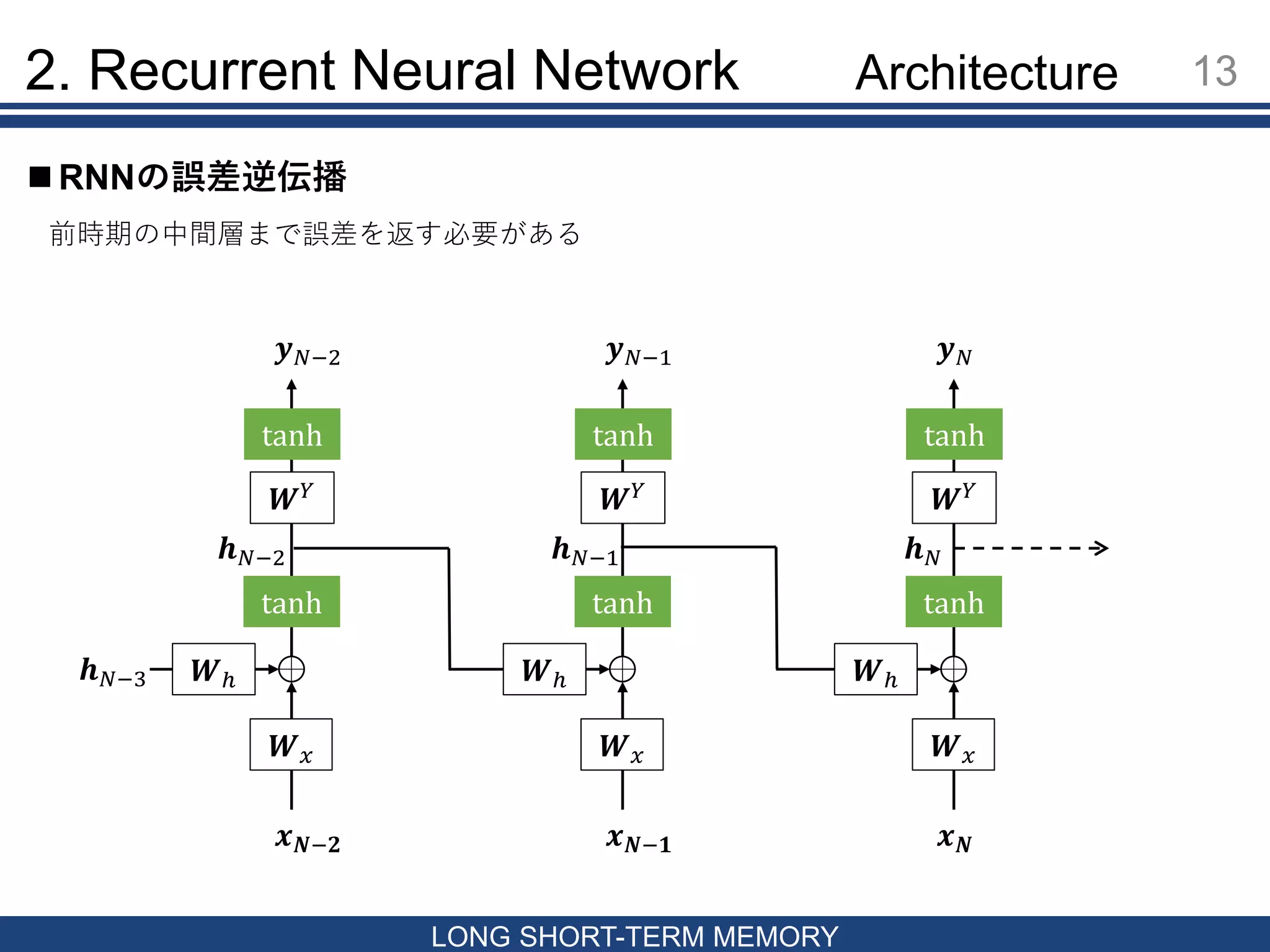
14 LONG SHORT-TERM MEMORY
RNNの誤差逆伝播 2. Recurrent Neural Network Back Propagation Through Time (BPTT) [Williams & Zipser 1992, Werbos 1988] 𝒙 𝑵−𝟏 𝒉 𝑁−1 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁−1 𝒙 𝑵−𝟐 𝒉 𝑁−3 𝒉 𝑁−2 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁−2 𝒙 𝑵 𝒉 𝑁 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑁 𝑛 = 𝑁から始め誤差の合計を計算する
15.
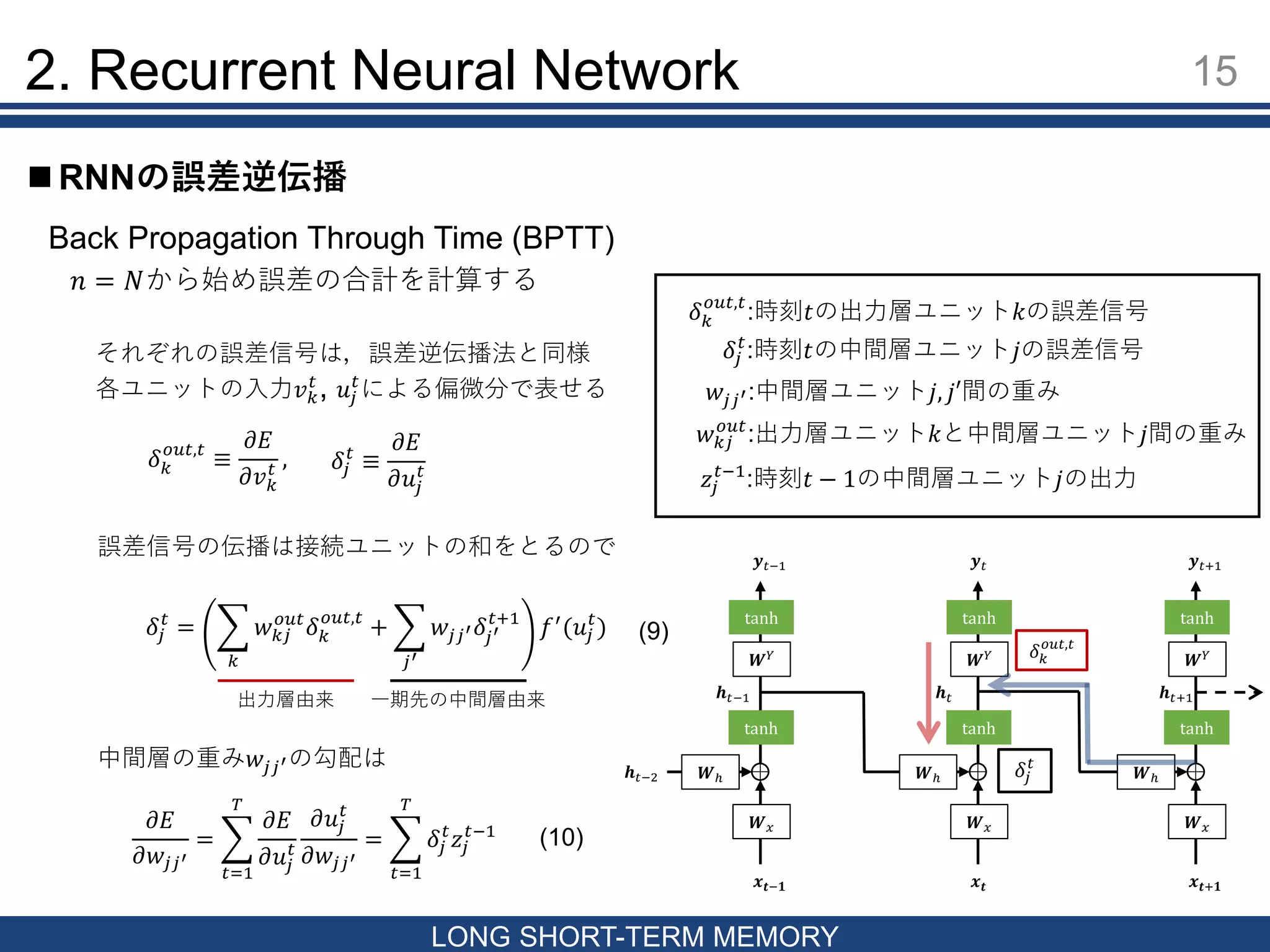
15 LONG SHORT-TERM MEMORY
RNNの誤差逆伝播 2. Recurrent Neural Network Back Propagation Through Time (BPTT) 𝒙 𝒕 𝒉 𝑡 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑡 𝒙 𝒕−𝟏 𝒉 𝑡−2 𝒉 𝑡−1 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑡−1 𝒙 𝒕+𝟏 𝒉 𝑡+1 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑡+1 𝑛 = 𝑁から始め誤差の合計を計算する 𝛿 𝑘 𝑜𝑢𝑡,𝑡 :時刻𝑡の出力層ユニット𝑘の誤差信号 𝛿𝑗 𝑡 :時刻𝑡の中間層ユニット𝑗の誤差信号 𝛿 𝑘 𝑜𝑢𝑡,𝑡 ≡ 𝜕𝐸 𝜕𝑣 𝑘 𝑡 , 𝛿𝑗 𝑡 ≡ 𝜕𝐸 𝜕𝑢𝑗 𝑡 𝛿𝑗 𝑡 = 𝑘 𝑤 𝑘𝑗 𝑜𝑢𝑡 𝛿 𝑘 𝑜𝑢𝑡,𝑡 + 𝑗′ 𝑤𝑗𝑗′ 𝛿𝑗′ 𝑡+1 𝑓′ (𝑢𝑗 𝑡 ) 𝜕𝐸 𝜕𝑤𝑗𝑗′ = 𝑡=1 𝑇 𝜕𝐸 𝜕𝑢𝑗 𝑡 𝜕𝑢𝑗 𝑡 𝜕𝑤𝑗𝑗′ = 𝑡=1 𝑇 𝛿𝑗 𝑡 𝑧𝑗 𝑡−1 𝛿 𝑘 𝑜𝑢𝑡,𝑡 𝛿𝑗 𝑡 それぞれの誤差信号は,誤差逆伝播法と同様 各ユニットの入力𝑣 𝑘 𝑡 , 𝑢𝑗 𝑡 による偏微分で表せる 誤差信号の伝播は接続ユニットの和をとるので 出力層由来 一期先の中間層由来 𝑤𝑗𝑗′:中間層ユニット𝑗, 𝑗′間の重み 𝑤 𝑘𝑗 𝑜𝑢𝑡 :出力層ユニット𝑘と中間層ユニット𝑗間の重み 中間層の重み𝑤𝑗𝑗′の勾配は 𝑧𝑗 𝑡−1 :時刻𝑡 − 1の中間層ユニット𝑗の出力 (9) (10)
16.
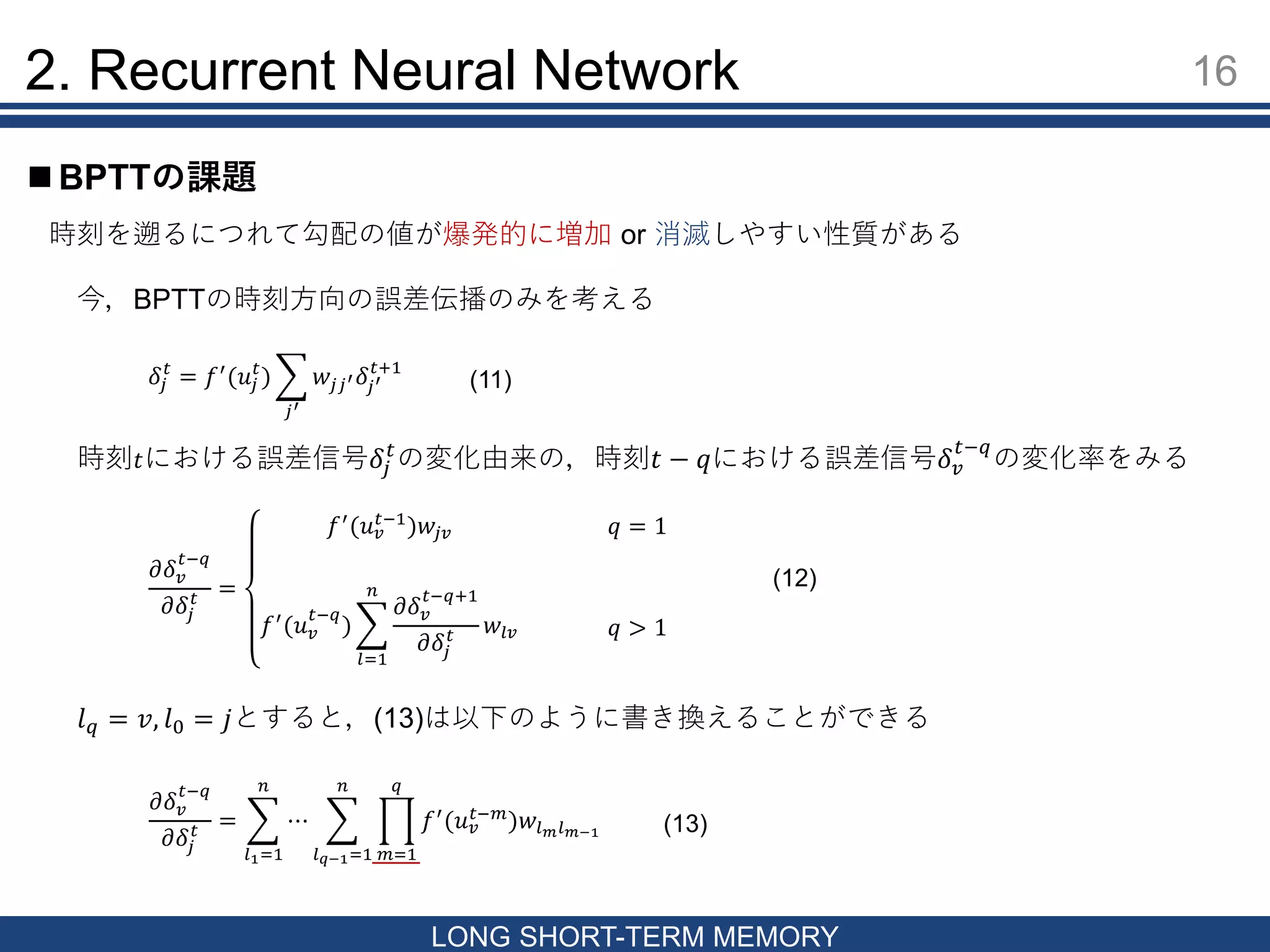
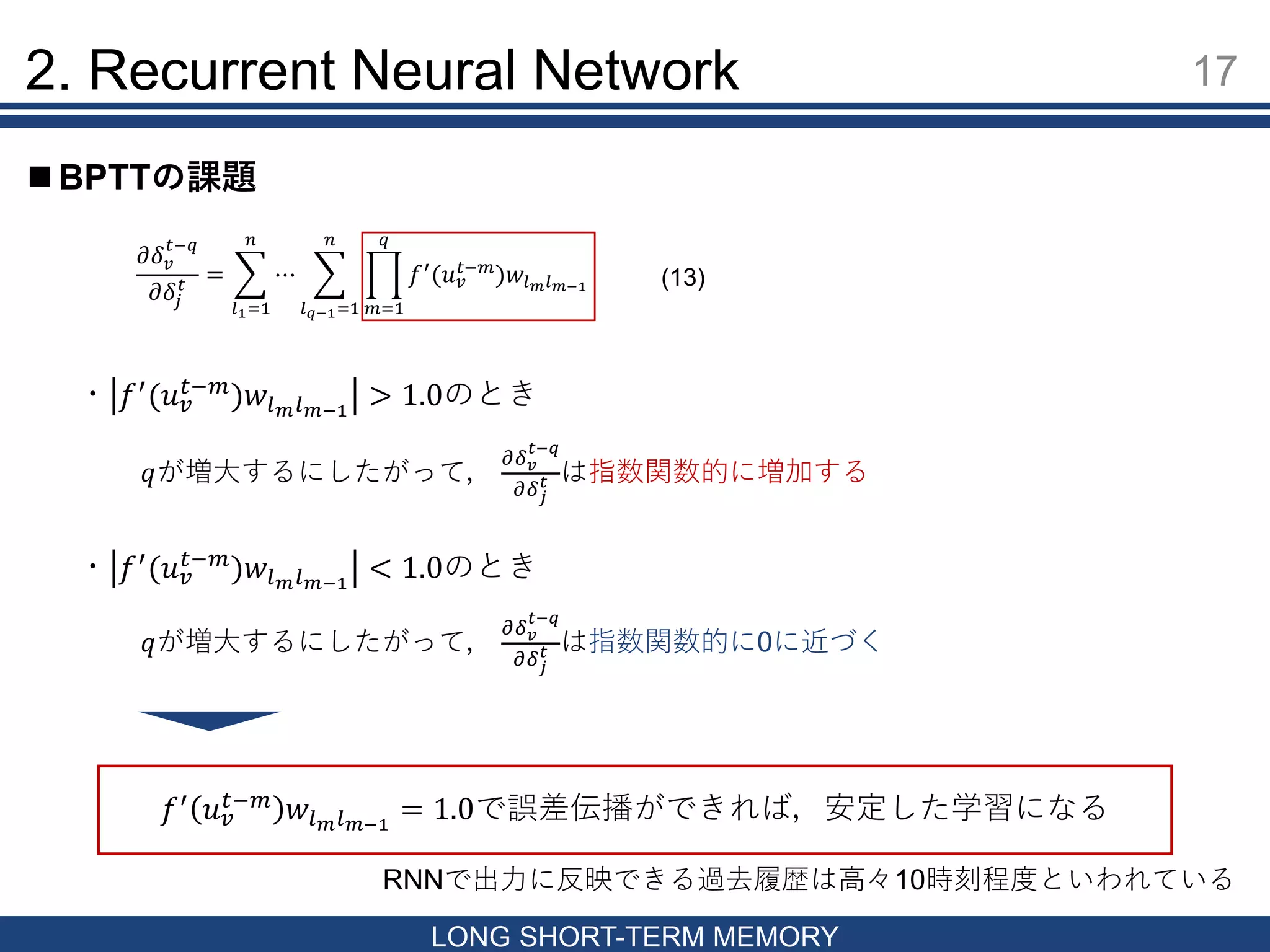
16 LONG SHORT-TERM MEMORY
BPTTの課題 2. Recurrent Neural Network 時刻を遡るにつれて勾配の値が爆発的に増加 or 消滅しやすい性質がある 今,BPTTの時刻方向の誤差伝播のみを考える 𝛿𝑗 𝑡 = 𝑓′ (𝑢𝑗 𝑡 ) 𝑗′ 𝑤𝑗𝑗′ 𝛿𝑗′ 𝑡+1 時刻 𝑡における誤差信号𝛿𝑗 𝑡 の変化由来の,時刻𝑡 − 𝑞における誤差信号𝛿 𝑣 𝑡−𝑞 の変化率をみる 𝜕𝛿 𝑣 𝑡−𝑞 𝜕𝛿𝑗 𝑡 = 𝑓′ (𝑢 𝑣 𝑡−1 )𝑤𝑗𝑣 𝑓′ (𝑢 𝑣 𝑡−𝑞 ) 𝑙=1 𝑛 𝜕𝛿 𝑣 𝑡−𝑞+1 𝜕𝛿𝑗 𝑡 𝑤𝑙𝑣 𝑞 = 1 𝑞 > 1 𝜕𝛿 𝑣 𝑡−𝑞 𝜕𝛿𝑗 𝑡 = 𝑙1=1 𝑛 ⋯ 𝑙 𝑞−1=1 𝑛 𝑚=1 𝑞 𝑓′ (𝑢 𝑣 𝑡−𝑚 )𝑤𝑙 𝑚 𝑙 𝑚−1 𝑙 𝑞 = 𝑣, 𝑙0 = 𝑗とすると,(13)は以下のように書き換えることができる (12) (11) (13)
17.
17 LONG SHORT-TERM MEMORY
BPTTの課題 2. Recurrent Neural Network 𝜕𝛿 𝑣 𝑡−𝑞 𝜕𝛿𝑗 𝑡 = 𝑙1=1 𝑛 ⋯ 𝑙 𝑞−1=1 𝑛 𝑚=1 𝑞 𝑓′ (𝑢 𝑣 𝑡−𝑚 )𝑤𝑙 𝑚 𝑙 𝑚−1 ・ 𝑓′(𝑢 𝑣 𝑡−𝑚)𝑤𝑙 𝑚 𝑙 𝑚−1 > 1.0のとき 𝑞が増大するにしたがって, 𝜕𝛿 𝑣 𝑡−𝑞 𝜕𝛿 𝑗 𝑡 は指数関数的に増加する ・ 𝑓′ (𝑢 𝑣 𝑡−𝑚 )𝑤𝑙 𝑚 𝑙 𝑚−1 < 1.0のとき 𝑞が増大するにしたがって, 𝜕𝛿 𝑣 𝑡−𝑞 𝜕𝛿 𝑗 𝑡 は指数関数的に0に近づく 𝑓′ 𝑢 𝑣 𝑡−𝑚 𝑤𝑙 𝑚 𝑙 𝑚−1 = 1.0で誤差伝播ができれば,安定した学習になる RNNで出力に反映できる過去履歴は高々10時刻程度といわれている (13)
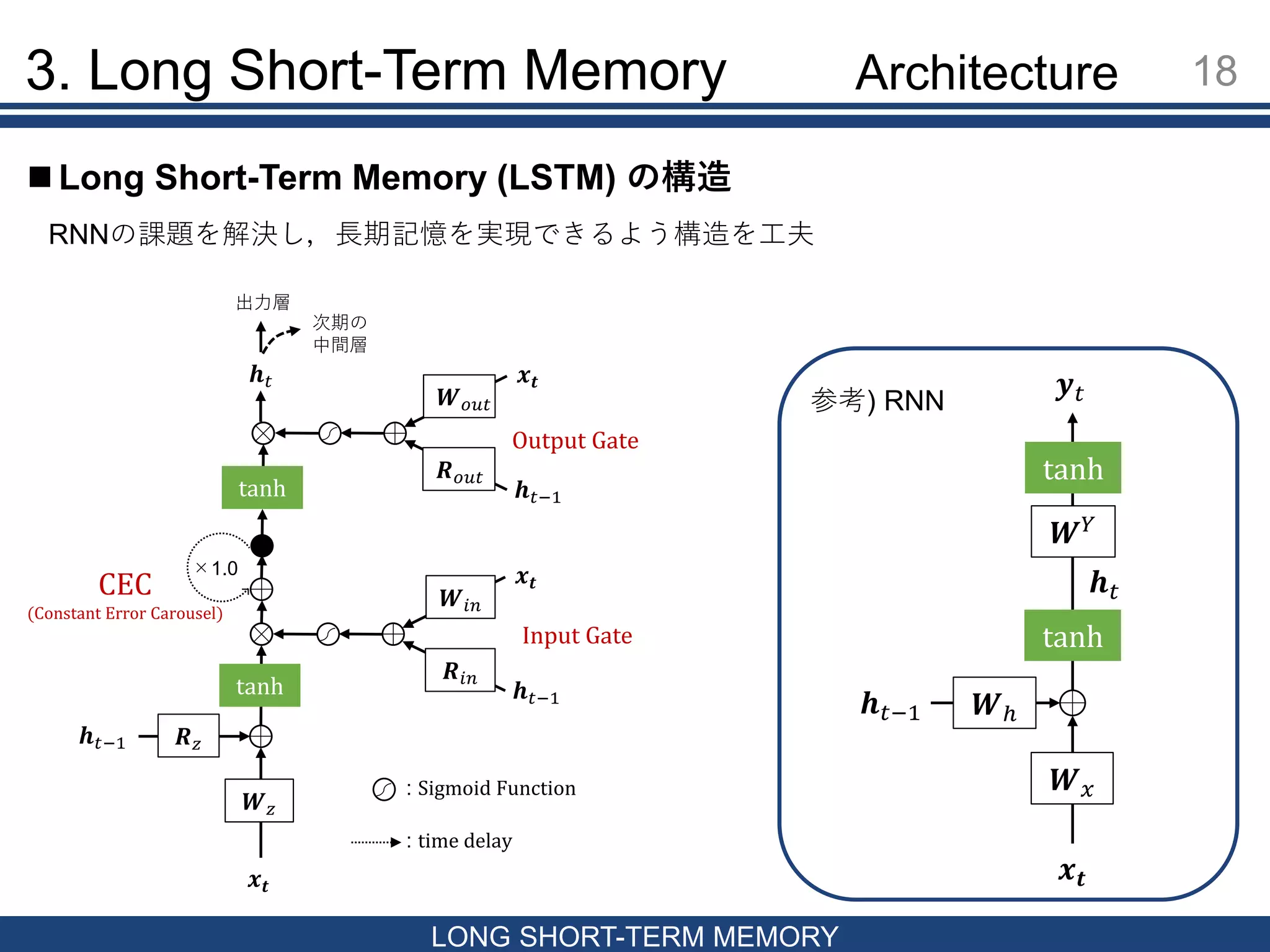
18.
3. Long Short-Term
Memory 18 LONG SHORT-TERM MEMORY Long Short-Term Memory (LSTM) の構造 RNNの課題を解決し,長期記憶を実現できるよう構造を工夫 𝒙𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate CEC (Constant Error Carousel) : Sigmoid Function : time delay 𝒙 𝒕 𝒉 𝑡−1 𝒉 𝑡 𝑾ℎ 𝑾 𝑥 𝑾 𝑌 tanh tanh 𝒚 𝑡参考) RNN Architecture
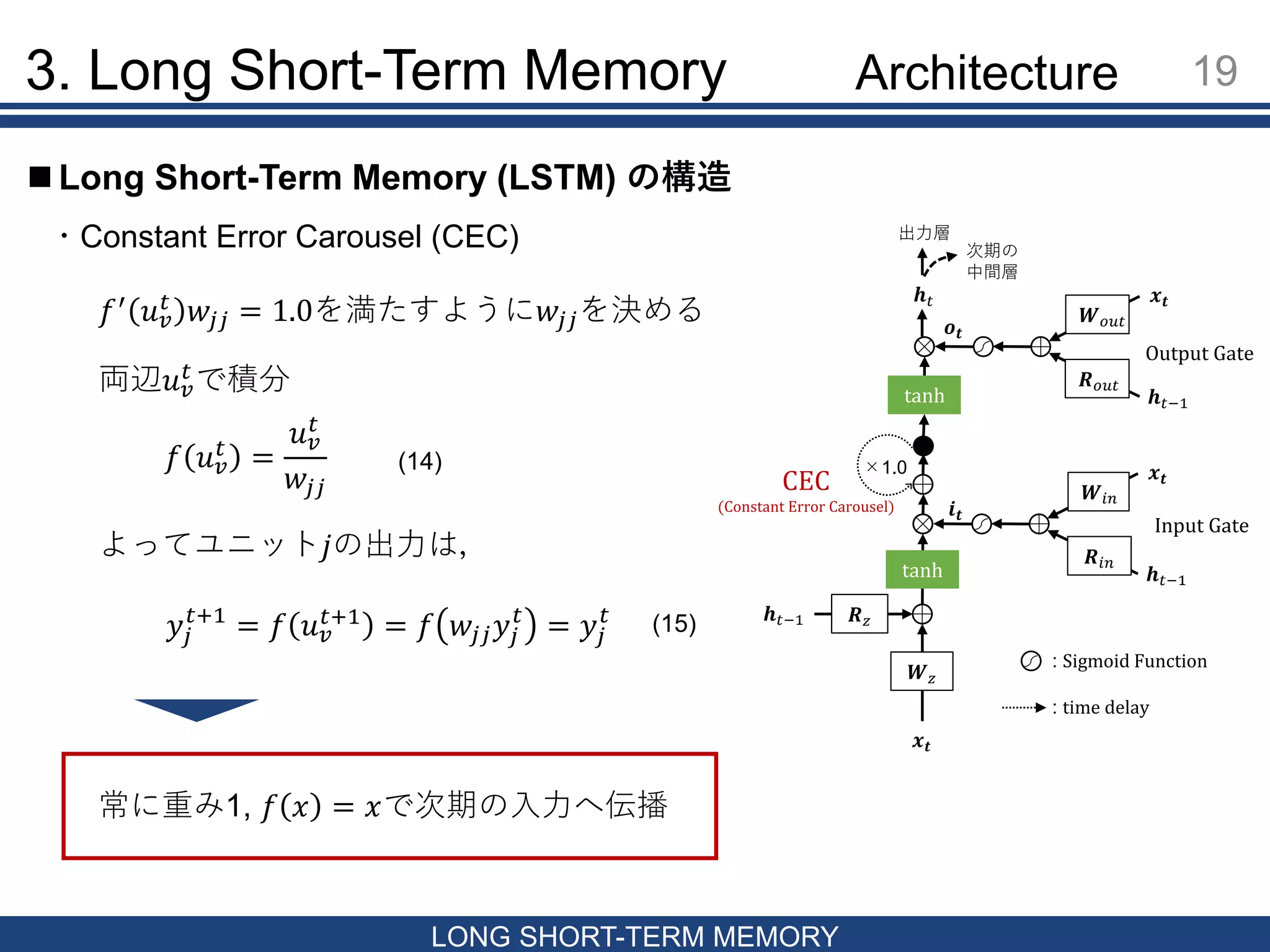
19.
3. Long Short-Term
Memory 19 LONG SHORT-TERM MEMORY Long Short-Term Memory (LSTM) の構造 ・Constant Error Carousel (CEC) 𝑓′ 𝑢 𝑣 𝑡 𝑤𝑗𝑗 = 1.0を満たすように𝑤𝑗𝑗を決める 𝑓 𝑢 𝑣 𝑡 = 𝑢 𝑣 𝑡 𝑤𝑗𝑗 両辺𝑢 𝑣 𝑡 で積分 よってユニット𝑗の出力は, 𝑦𝑗 𝑡+1 = 𝑓 𝑢 𝑣 𝑡+1 = 𝑓 𝑤𝑗𝑗 𝑦𝑗 𝑡 = 𝑦𝑗 𝑡 常に重み1, 𝑓 𝑥 = 𝑥で次期の入力へ伝播 𝒙 𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙 𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙 𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate CEC (Constant Error Carousel) : Sigmoid Function : time delay 𝒊 𝒕 𝒐 𝒕 Architecture (14) (15)
20.
3. Long Short-Term
Memory 20 LONG SHORT-TERM MEMORY Long Short-Term Memory (LSTM) の構造 ・CECが引き起こす問題 𝒙 𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙 𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙 𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate CEC (Constant Error Carousel) : Sigmoid Function : time delay 1. Input weight conflict 時系列データ{𝑠1, 𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑠2} を予測する. ここで𝑠同士, 𝑎同士が関連を持つ場合を考える. ①入力を保持する 𝑠2を予測するために 𝑠1の情報を用いたい. よって入力を受け入れたい ②入力を防ぐ 𝑠2を予測するために 𝑎1, 𝑎2, 𝑎3, 𝑎4の情報は 必要ない.よって入力を妨げたい. シグモイド関数により各要素[0, 1]となるInput Gateの出力𝒊 𝒕と 入力の内積をとることで,重み以外で入力可否を決定 𝒊 𝒕 𝒐 𝒕 Architecture
21.
3. Long Short-Term
Memory 21 LONG SHORT-TERM MEMORY Long Short-Term Memory (LSTM) の構造 ・CECが引き起こす問題 𝒙 𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙 𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙 𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate CEC (Constant Error Carousel) : Sigmoid Function : time delay 2. Output weight conflict 時系列データ{𝑠1, 𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑠2} を予測する. ここで𝑠同士, 𝑎同士が関連を持つ場合を考える. ①出力を保持する 𝑠2を予測するために 𝑠1の情報を用いたい. よって出力を受け入れたい ②出力を防ぐ 𝑠2を予測するために 𝑎1, 𝑎2, 𝑎3, 𝑎4の情報は 必要ない.よって出力を妨げたい. シグモイド関数により各要素[0, 1]となるOutput Gateの出力𝒐 𝒕 と入力の内積をとることで,重み以外で入力可否を決定 𝒊 𝒕 𝒐 𝒕 Architecture
22.
3. Long Short-Term
Memory 22 LONG SHORT-TERM MEMORY LSTMのその他の課題とその対処 ・Abuse Problem 学習の初期段階では,前時期の情報を蓄えていなくても誤差は減少する メモリセルを乱用されてしまう (例:バイアスを考慮するためのセルに充てられる) ⇒この場合,本来の用途へ学習を転換するのに時間がかかる 2つのメモリセルが同じ情報を記憶してしまう問題も現れる (1) 誤差の減少が止まったとき,メモリセルとそれに対応するゲートを追加していく (2) 出力ゲートを負の値で初期化する ⇒ゼロで初期化するより,メモリセルの学習に時間がかかるため, 序盤で別用途で学習されるのを防ぐ 解決策
23.
3. Long Short-Term
Memory 23 LONG SHORT-TERM MEMORY LSTMのその他の課題とその対処 ・Initial state drift CECでは活性化関数が線形 学習初期入力ゲートの出力をゼロに近づくようfine-tuning 解決策 メモリセルへの入力がほとんど正 or ほとんど負 の場合,メモリセルの値が大きくなる ⇒中間状態が相対的に小さくなり,勾配が消失してしまう ⇒他のユニットが学習を進めるのを待つ効果を持つ
24.
3. Long Short-Term
Memory 24 LONG SHORT-TERM MEMORY Outline of experiments 1. 短期記憶用ベンチマークテスト 多くの論文で使用されており.既往手法でも成功を収めているテストでの確認 2. 長期記憶用データ,入力にノイズなし 長期記憶に対して,既往手法と精度の比較 3. 長期記憶用データ,入力にノイズあり 2. でLSTMの優位性を確認し,ここではノイズへの頑健性を確認 4, 5. 入力が連続値 1~3までは入力がone-hot vector.ここでは連続値が入力の場合の精度を確認 6. その他のリカレントアルゴリズムで解けなかったタスク experiments
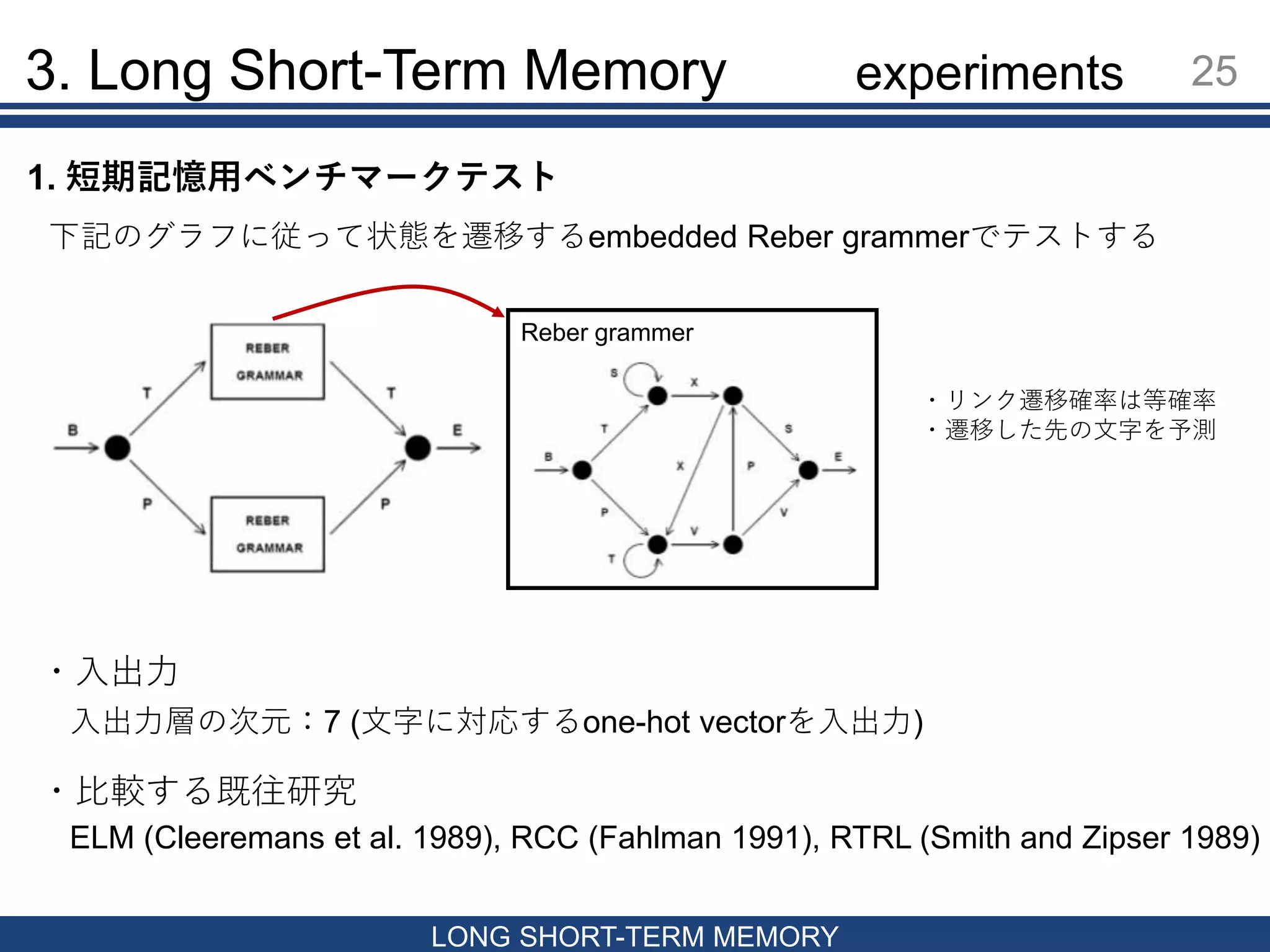
25.
3. Long Short-Term
Memory 25 LONG SHORT-TERM MEMORY 1. 短期記憶用ベンチマークテスト 下記のグラフに従って状態を遷移するembedded Reber grammerでテストする ・リンク遷移確率は等確率 ・遷移した先の文字を予測 Reber grammer ・入出力 入出力層の次元:7 (文字に対応するone-hot vectorを入出力) ・比較する既往研究 ELM (Cleeremans et al. 1989), RCC (Fahlman 1991), RTRL (Smith and Zipser 1989) experiments
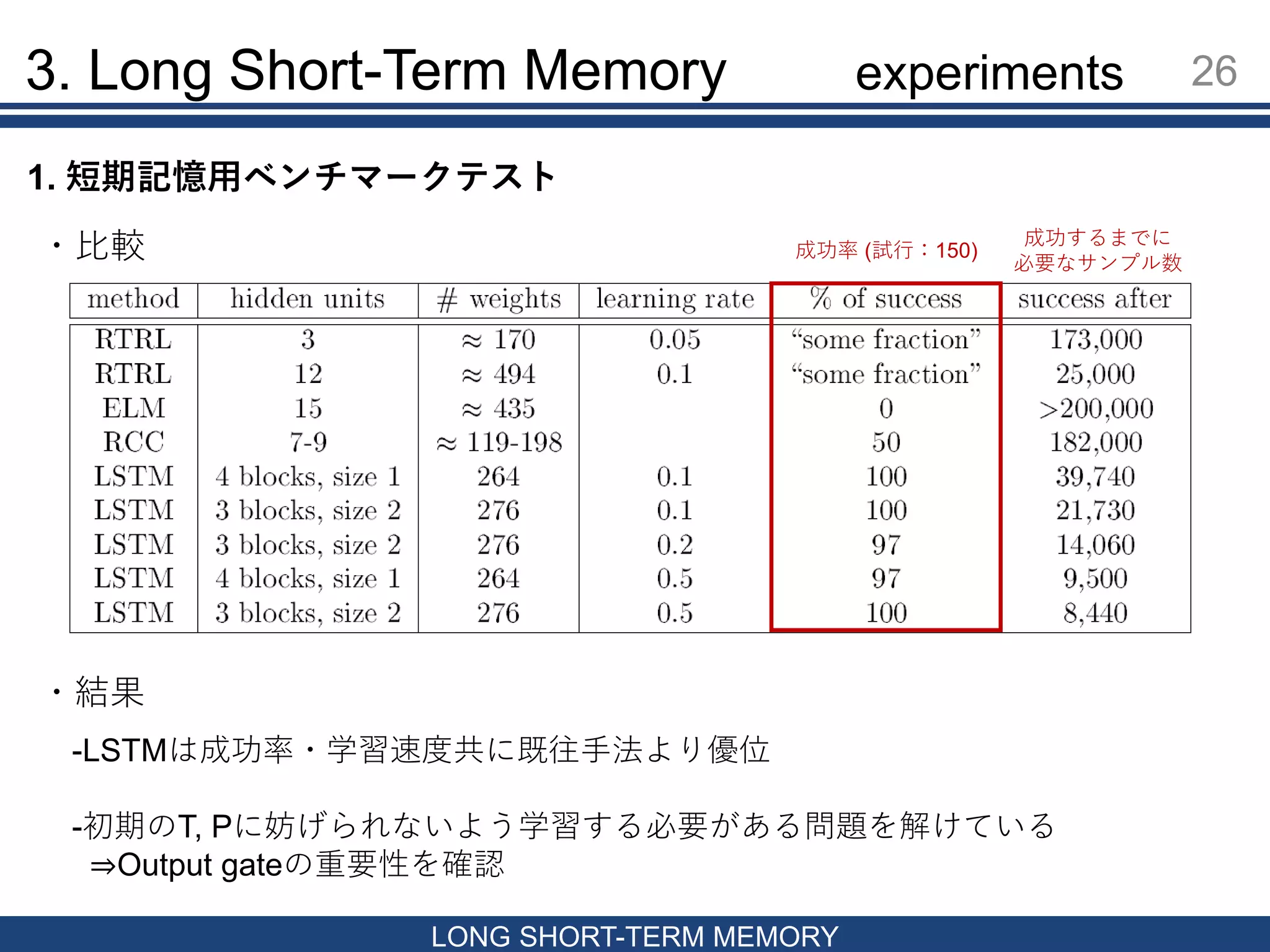
26.
3. Long Short-Term
Memory 26 LONG SHORT-TERM MEMORY 1. 短期記憶用ベンチマークテスト 成功するまでに 必要なサンプル数 成功率 (試行:150)・比較 ・結果 -LSTMは成功率・学習速度共に既往手法より優位 -初期のT, Pに妨げられないよう学習する必要がある問題を解けている ⇒Output gateの重要性を確認 experiments
27.
3. Long Short-Term
Memory 27 LONG SHORT-TERM MEMORY 2. 長期記憶用データ,入力にノイズなし 以下の2つの系列を用意 (𝑦, 𝑎1, 𝑎2, … , 𝑎 𝑝−1, 𝑦) (𝑥, 𝑎1, 𝑎2, … , 𝑎 𝑝−1, 𝑥) 𝑎𝑖: 𝑖番目要素のみ1, それ以外0の𝑝 + 1次元ベクトル 𝑥 = 𝑎 𝑝, 𝑦 = 𝑎 𝑝+1 ・入出力 入出力層の次元: 𝑝 + 1 ・比較する既往研究 RTRL (Smith and Zipser 1989) BPTT (Williams & Zipser 1992, Werbos 1988) Neural Sequence Chunker (CH, Schmidhuber 1992) 学習時,試行ごとにどちらかの系列を等確率で採択 末尾を予測するためには冒頭を記憶しておく必要がある experiments
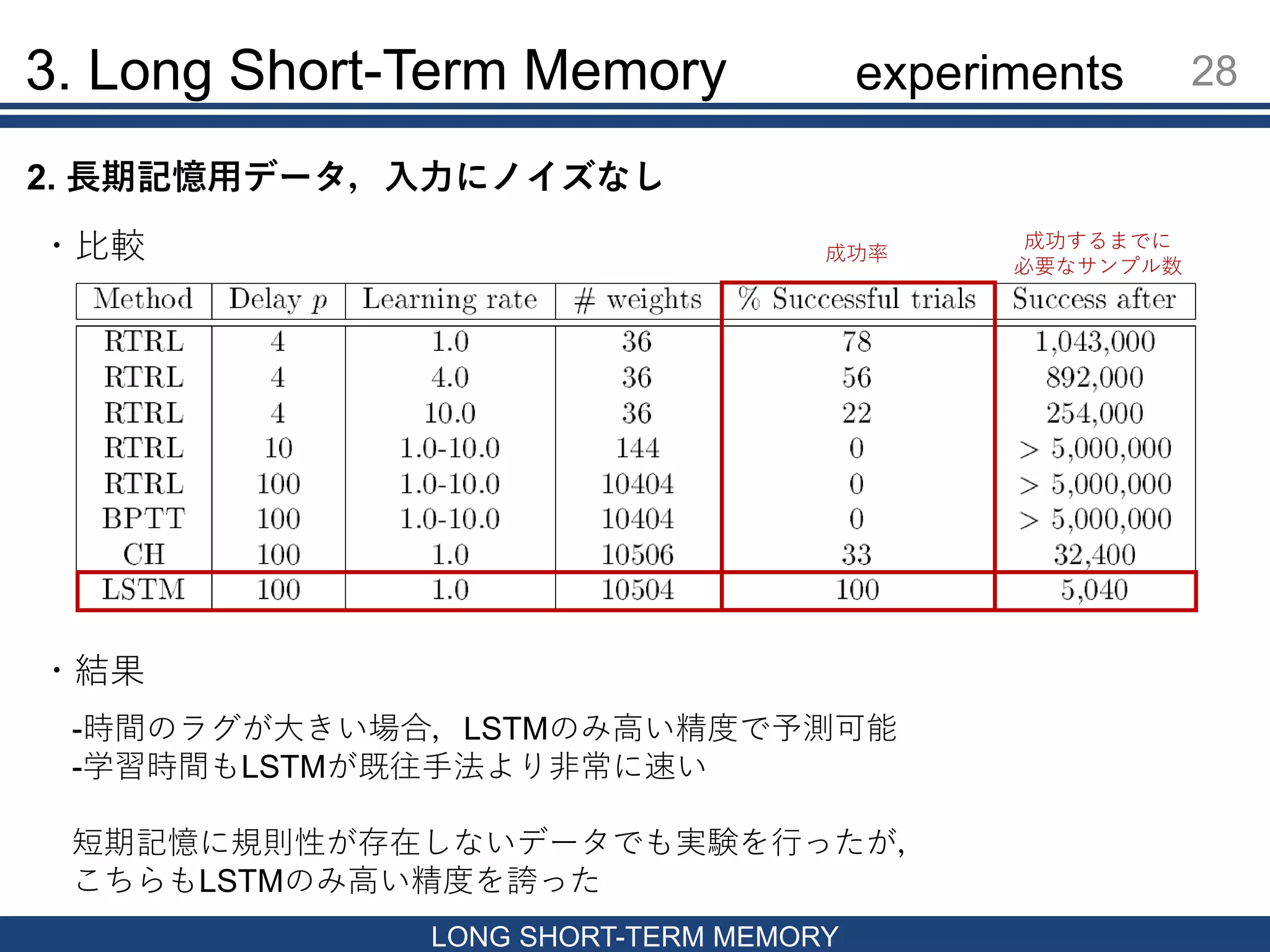
28.
3. Long Short-Term
Memory 28 LONG SHORT-TERM MEMORY 成功するまでに 必要なサンプル数 成功率・比較 ・結果 -時間のラグが大きい場合,LSTMのみ高い精度で予測可能 -学習時間もLSTMが既往手法より非常に速い 短期記憶に規則性が存在しないデータでも実験を行ったが, こちらもLSTMのみ高い精度を誇った 2. 長期記憶用データ,入力にノイズなし experiments
29.
3. Long Short-Term
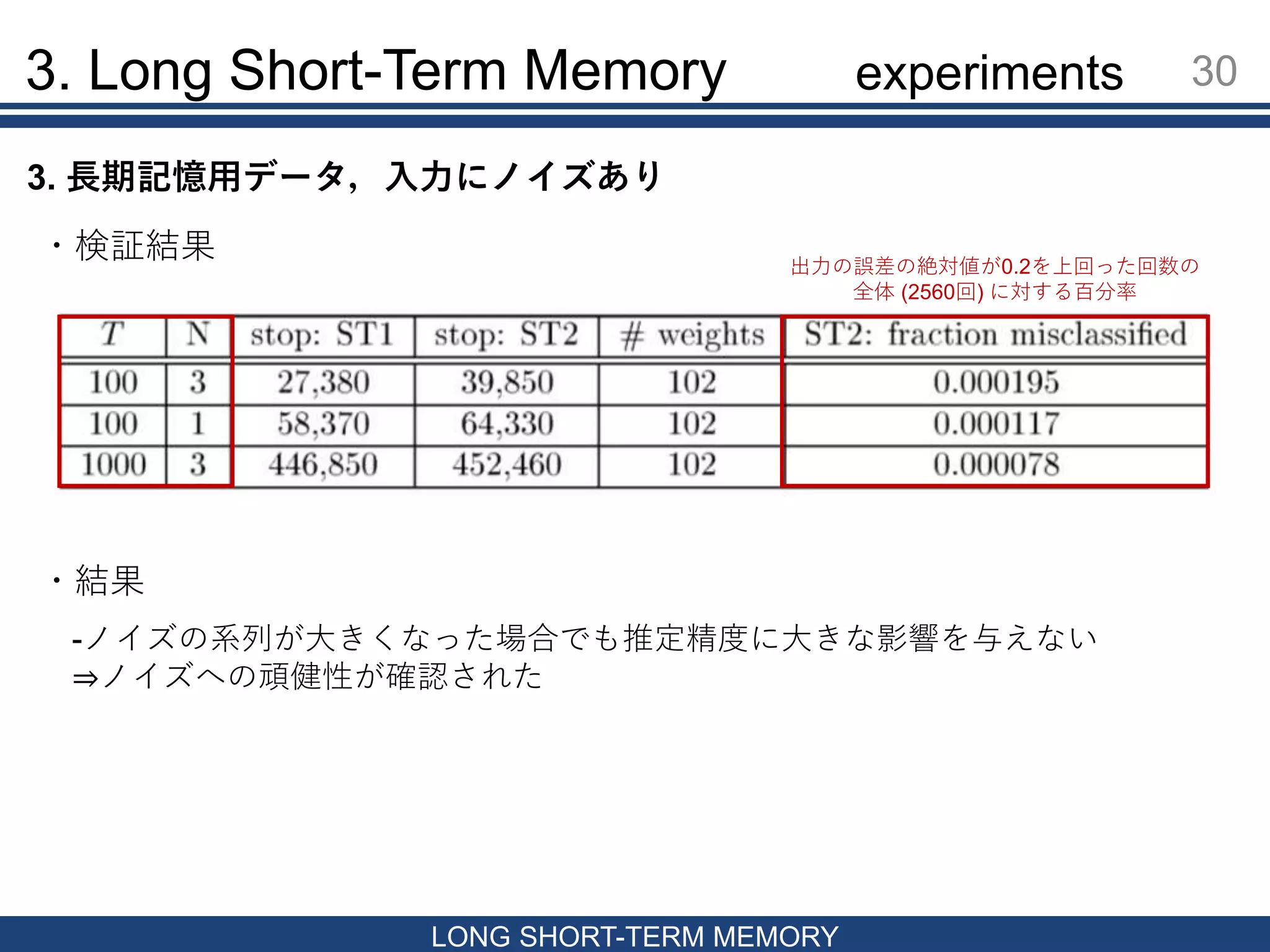
Memory 29 LONG SHORT-TERM MEMORY 3. 長期記憶用データ,入力にノイズあり 以下の2つの系列を用意 (1.0, 1.0, … , 1.0, 𝑎1, 𝑎2, … , 𝑎 𝑇−𝑁, 1.0) 𝑎𝑖: 平均0, 分散2.0のガウス分布より生成 ・入出力 入出力層の次元: 1 ・比較対象 𝑇, 𝑁 : 100, 3 , 100, 1 , (1000, 3) の三通りについてLSTMの精度を検証 𝑡 > 𝑁に存在するノイズが,LSTMにとって根本的な課題にならないことを示す (−1.0, −1.0, … , −1.0, 𝑎1, 𝑎2, … , 𝑎 𝑇−𝑁, 0.0) 𝑁 𝑁 𝑡 ≤ 𝑁まで class1は1.0, class2は-1.0を要素に持つ experiments
30.
3. Long Short-Term
Memory 30 LONG SHORT-TERM MEMORY ・検証結果 ・結果 -ノイズの系列が大きくなった場合でも推定精度に大きな影響を与えない ⇒ノイズへの頑健性が確認された 3. 長期記憶用データ,入力にノイズあり 出力の誤差の絶対値が0.2を上回った回数の 全体 (2560回) に対する百分率 experiments
31.
3. Long Short-Term
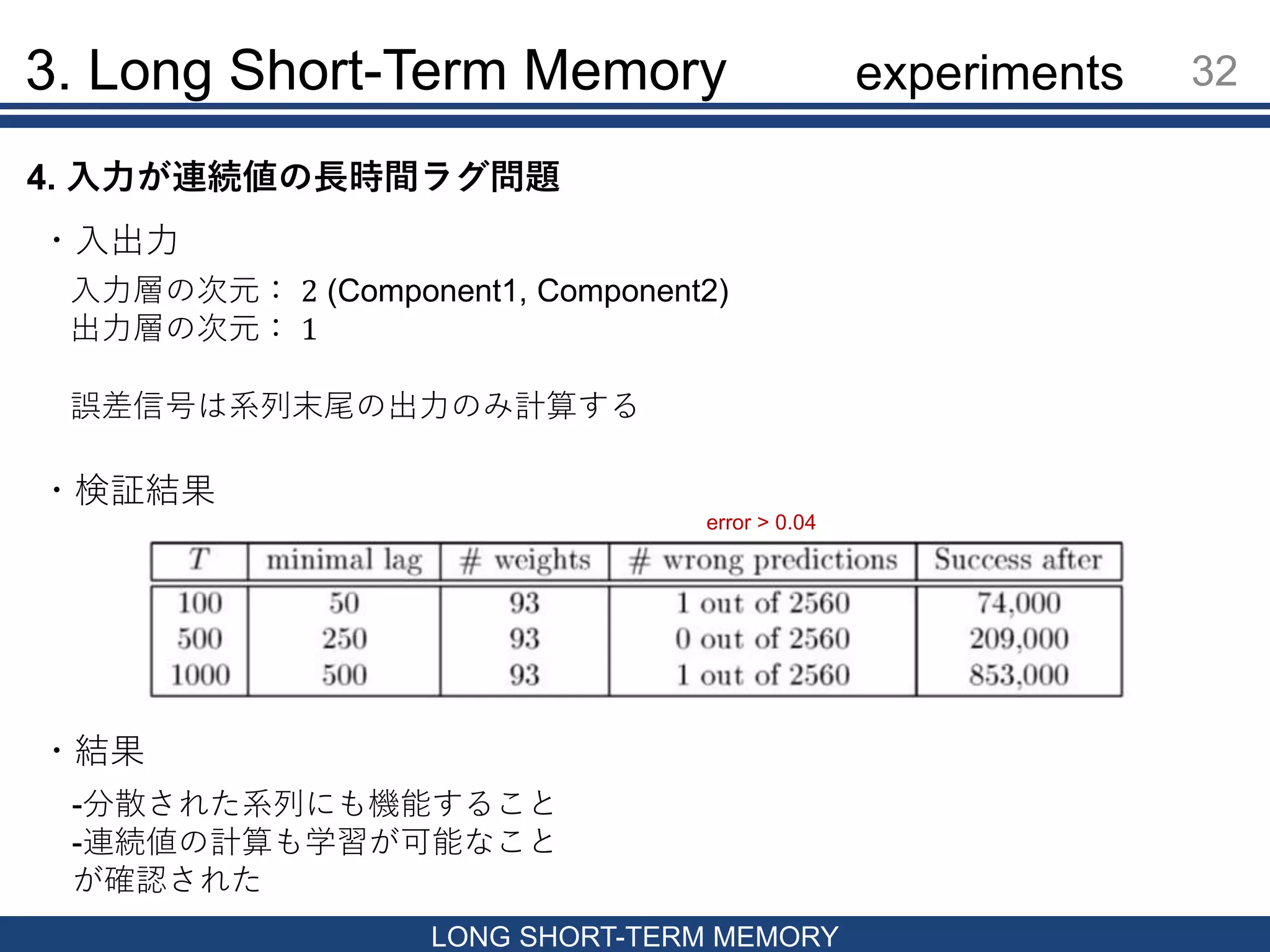
Memory 31 LONG SHORT-TERM MEMORY 4. 入力が連続値の長時間ラグ問題 2つのComponentのペアで構成される2次元ベクトルを入力 Component2でマークされた値の合計値を予測する問題 • Component1:[-1, 1]からランダムで抽出される • Component2:1.0, 0.0, -1.0のいずれか Component2の割り付けルール 最初から10番目までの要素からランダムで1ペアだけ1.0 (対応する値を𝑋1とする) 上記でマークされていない最初から 𝑇 2 − 1まで要素からランダムで1ペアのみ1.0 (対応する値を𝑋2とする) それ以外は基本0.0 最初と最後のペアのみ-1.0 予測値 0.5 + 𝑋1 + 𝑋2 4.0 experiments
32.
3. Long Short-Term
Memory 32 LONG SHORT-TERM MEMORY 4. 入力が連続値の長時間ラグ問題 ・入出力 入力層の次元: 2 (Component1, Component2) 出力層の次元: 1 誤差信号は系列末尾の出力のみ計算する ・検証結果 error > 0.04 ・結果 -分散された系列にも機能すること -連続値の計算も学習が可能なこと が確認された experiments
33.
3. Long Short-Term
Memory 33 LONG SHORT-TERM MEMORY conclusion • RNNの課題であった誤差の消失,爆発問題をCECの導入により解決した ⇒これにより,長期ラグをもつ系列の予測も可能になった • 入力ゲートと出力ゲートを導入することにより,CECの情報にアクセス するか否かを判断できるようになった ⇒これにより,長期と短期の予測の矛盾を解消できるようになった Future work Conclusion • 実問題に適用し,LSTMの実践的な限界を発見すること 時系列予測,作曲,音声処理など
34.
Appendix 34 LONG SHORT-TERM
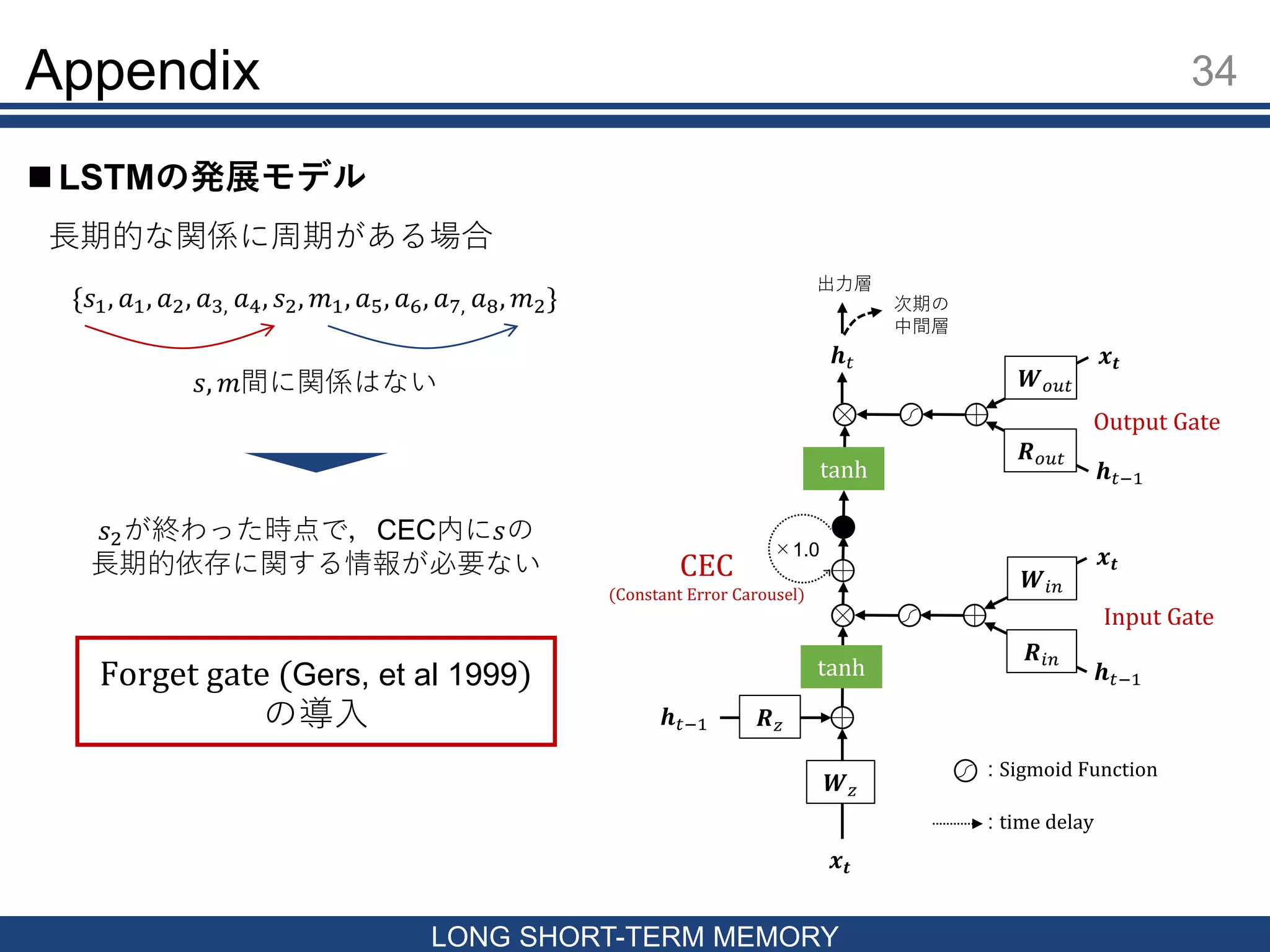
MEMORY LSTMの発展モデル 𝒙𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate CEC (Constant Error Carousel) : Sigmoid Function : time delay 長期的な関係に周期がある場合 {𝑠1, 𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑠2, 𝑚1, 𝑎5, 𝑎6, 𝑎7, 𝑎8, 𝑚2} 𝑠, 𝑚間に関係はない 𝑠2が終わった時点で,CEC内に𝑠の 長期的依存に関する情報が必要ない Forget gate (Gers, et al 1999) の導入
35.
Appendix 35 LONG SHORT-TERM
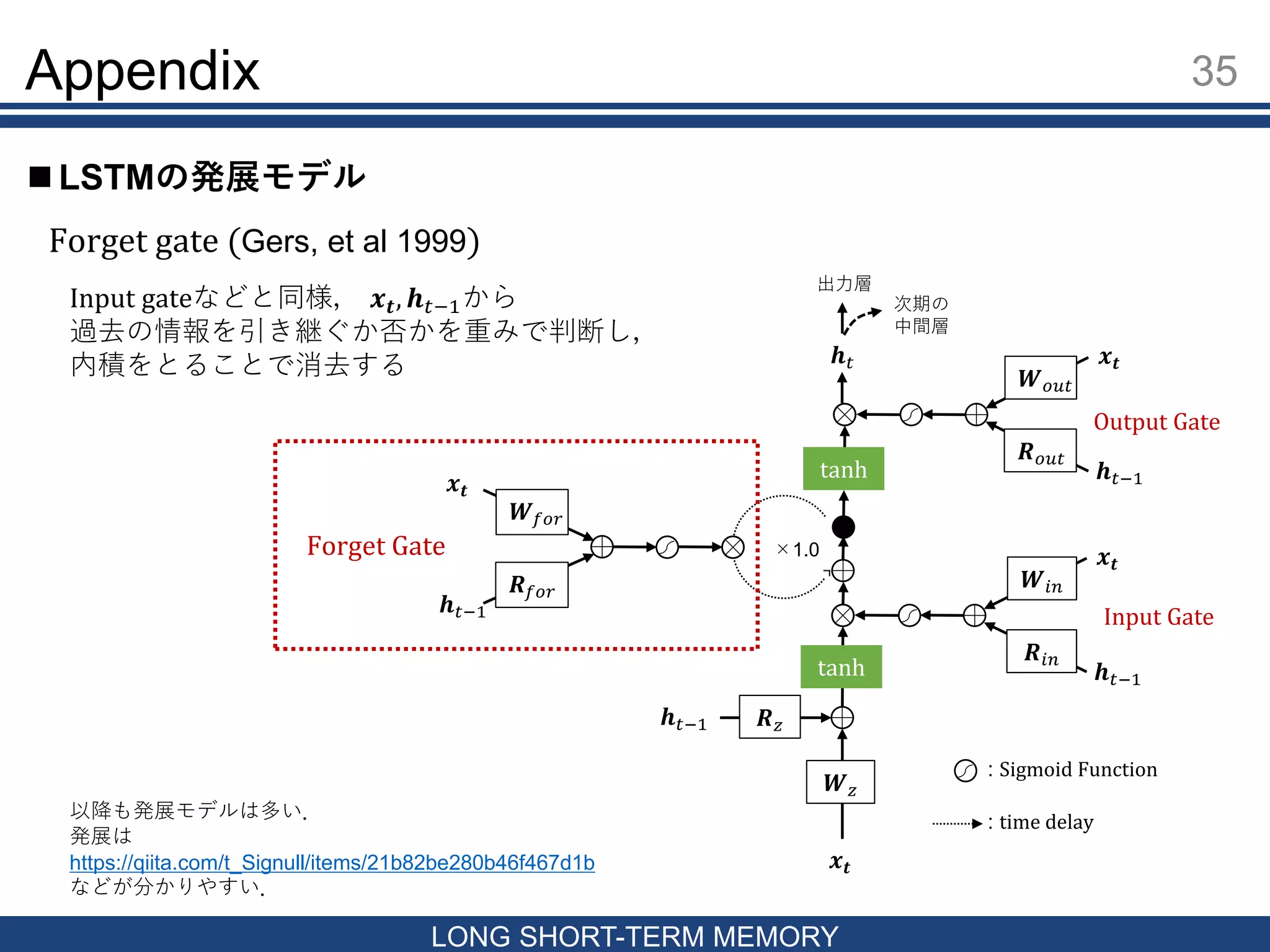
MEMORY LSTMの発展モデル 𝒙𝒕 𝒉 𝑡−1 𝑹 𝑧 𝑾 𝑧 tanh 𝒙𝒕 𝒉 𝑡−1 𝑾𝑖𝑛 𝑹𝑖𝑛 𝒙𝒕 𝒉 𝑡−1 𝑾 𝑜𝑢𝑡 𝑹 𝑜𝑢𝑡 tanh 𝒉 𝑡 出力層 次期の 中間層 ×1.0 Input Gate Output Gate : Sigmoid Function : time delay Forget gate (Gers, et al 1999) 𝒙𝒕 𝒉 𝑡−1 𝑾 𝑓𝑜𝑟 𝑹 𝑓𝑜𝑟 Forget Gate Input gateなどと同様, 𝒙 𝒕, 𝒉 𝑡−1から 過去の情報を引き継ぐか否かを重みで判断し, 内積をとることで消去する 以降も発展モデルは多い. 発展は https://qiita.com/t_Signull/items/21b82be280b46f467d1b などが分かりやすい.
36.
36 LONG SHORT-TERM MEMORY Appendix
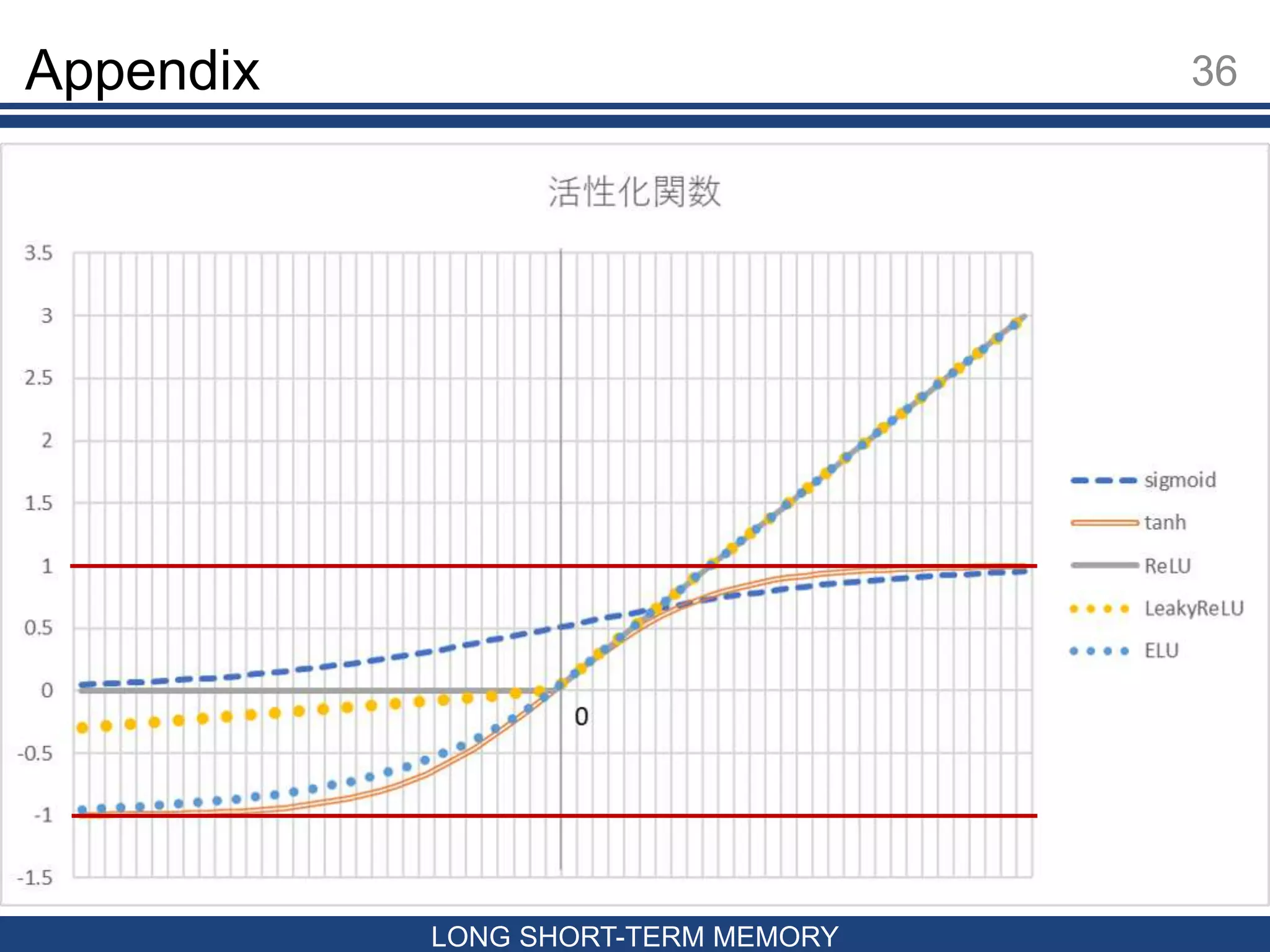
活性化関数
Download








![14
LONG SHORT-TERM MEMORY
RNNの誤差逆伝播
2. Recurrent Neural Network
Back Propagation Through Time (BPTT) [Williams & Zipser 1992, Werbos 1988]
𝒙 𝑵−𝟏
𝒉 𝑁−1
𝑾ℎ
𝑾 𝑥
𝑾 𝑌
tanh
tanh
𝒚 𝑁−1
𝒙 𝑵−𝟐
𝒉 𝑁−3
𝒉 𝑁−2
𝑾ℎ
𝑾 𝑥
𝑾 𝑌
tanh
tanh
𝒚 𝑁−2
𝒙 𝑵
𝒉 𝑁
𝑾ℎ
𝑾 𝑥
𝑾 𝑌
tanh
tanh
𝒚 𝑁
𝑛 = 𝑁から始め誤差の合計を計算する](https://image.slidesharecdn.com/06ishii-200617020533/75/Long-short-term-memory-LSTM-14-2048.jpg)
![3. Long Short-Term Memory 20
LONG SHORT-TERM MEMORY
Long Short-Term Memory (LSTM) の構造
・CECが引き起こす問題
𝒙 𝒕
𝒉 𝑡−1 𝑹 𝑧
𝑾 𝑧
tanh
𝒙 𝒕
𝒉 𝑡−1
𝑾𝑖𝑛
𝑹𝑖𝑛
𝒙 𝒕
𝒉 𝑡−1
𝑾 𝑜𝑢𝑡
𝑹 𝑜𝑢𝑡
tanh
𝒉 𝑡
出力層
次期の
中間層
×1.0
Input Gate
Output Gate
CEC
(Constant Error Carousel)
: Sigmoid Function
: time delay
1. Input weight conflict
時系列データ{𝑠1, 𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑠2} を予測する.
ここで𝑠同士, 𝑎同士が関連を持つ場合を考える.
①入力を保持する
𝑠2を予測するために 𝑠1の情報を用いたい.
よって入力を受け入れたい
②入力を防ぐ
𝑠2を予測するために 𝑎1, 𝑎2, 𝑎3, 𝑎4の情報は
必要ない.よって入力を妨げたい.
シグモイド関数により各要素[0, 1]となるInput Gateの出力𝒊 𝒕と
入力の内積をとることで,重み以外で入力可否を決定
𝒊 𝒕
𝒐 𝒕
Architecture](https://image.slidesharecdn.com/06ishii-200617020533/75/Long-short-term-memory-LSTM-20-2048.jpg)
![3. Long Short-Term Memory 21
LONG SHORT-TERM MEMORY
Long Short-Term Memory (LSTM) の構造
・CECが引き起こす問題
𝒙 𝒕
𝒉 𝑡−1 𝑹 𝑧
𝑾 𝑧
tanh
𝒙 𝒕
𝒉 𝑡−1
𝑾𝑖𝑛
𝑹𝑖𝑛
𝒙 𝒕
𝒉 𝑡−1
𝑾 𝑜𝑢𝑡
𝑹 𝑜𝑢𝑡
tanh
𝒉 𝑡
出力層
次期の
中間層
×1.0
Input Gate
Output Gate
CEC
(Constant Error Carousel)
: Sigmoid Function
: time delay
2. Output weight conflict
時系列データ{𝑠1, 𝑎1, 𝑎2, 𝑎3, 𝑎4, 𝑠2} を予測する.
ここで𝑠同士, 𝑎同士が関連を持つ場合を考える.
①出力を保持する
𝑠2を予測するために 𝑠1の情報を用いたい.
よって出力を受け入れたい
②出力を防ぐ
𝑠2を予測するために 𝑎1, 𝑎2, 𝑎3, 𝑎4の情報は
必要ない.よって出力を妨げたい.
シグモイド関数により各要素[0, 1]となるOutput Gateの出力𝒐 𝒕
と入力の内積をとることで,重み以外で入力可否を決定
𝒊 𝒕
𝒐 𝒕
Architecture](https://image.slidesharecdn.com/06ishii-200617020533/75/Long-short-term-memory-LSTM-21-2048.jpg)





![3. Long Short-Term Memory 31
LONG SHORT-TERM MEMORY
4. 入力が連続値の長時間ラグ問題
2つのComponentのペアで構成される2次元ベクトルを入力
Component2でマークされた値の合計値を予測する問題
• Component1:[-1, 1]からランダムで抽出される
• Component2:1.0, 0.0, -1.0のいずれか
Component2の割り付けルール
最初から10番目までの要素からランダムで1ペアだけ1.0 (対応する値を𝑋1とする)
上記でマークされていない最初から
𝑇
2
− 1まで要素からランダムで1ペアのみ1.0
(対応する値を𝑋2とする)
それ以外は基本0.0
最初と最後のペアのみ-1.0
予測値
0.5 +
𝑋1 + 𝑋2
4.0
experiments](https://image.slidesharecdn.com/06ishii-200617020533/75/Long-short-term-memory-LSTM-31-2048.jpg)

![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Whole-Body Human Pose Estimation in the Wild](https://cdn.slidesharecdn.com/ss_thumbnails/20200731wholebodyhumanposeestimationinthewildkuboshizuma-200804012445-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)



![[論文紹介] LSTM (LONG SHORT-TERM MEMORY)](https://cdn.slidesharecdn.com/ss_thumbnails/2018-181019021803-thumbnail.jpg?width=640&height=640&fit=bounds)

















