Download as PDF, PPTX


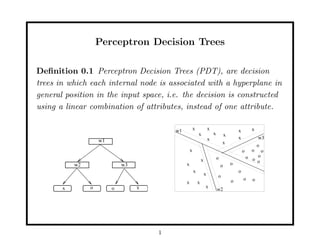
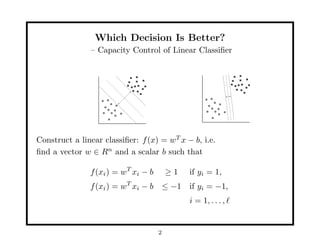




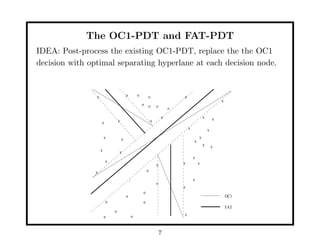

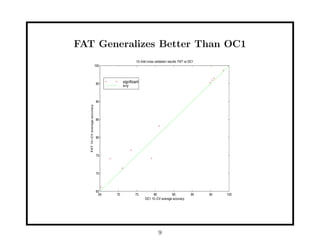
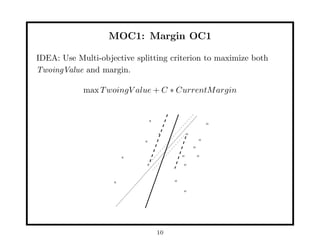
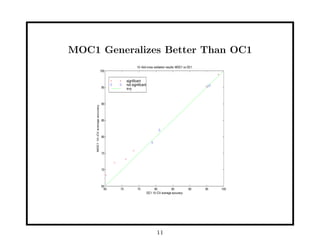


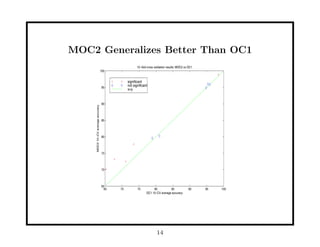
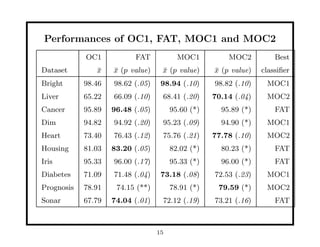


This document discusses methods for improving perceptron decision trees (PDTs) by enlarging their margins. It proposes three algorithms: 1. FAT (Find-And-Replace Trees) post-processes existing decision trees by replacing each node's decision with an optimal separating hyperplane found via perceptron learning, maximizing the margin. 2. MOC1 (Margin OC1) modifies the OC1 algorithm to use a multi-objective splitting criterion that maximizes both information gain and margin size. 3. MOC2 modifies the splitting criterion (Twoing rule) to incorporate margin. Experimental results show FAT and MOC1 generalize better than the basic OC1 algorithm on benchmark datasets.








































































































