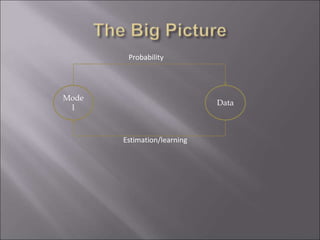
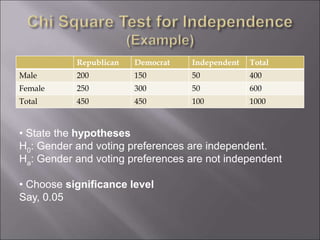
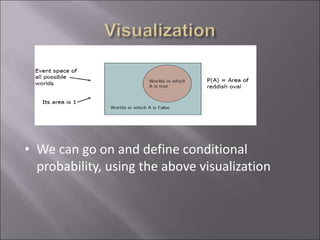
The document provides an overview of probability and statistics, highlighting key concepts such as probability distributions, random variables, and essential statistical principles like conditional probability and independence. It emphasizes the relationship between probability theory and statistical analysis, detailing various probability functions and laws governing random variables. Additionally, the document covers topics like mean, variance, covariance, and the significance of joint and marginal distributions in understanding data relationships.










![ Uniform X U[1, …, N]
X takes values 1, 2, … N
P(X = i) = 1/N
E.g. picking balls of different colors from a box
Binomial X Bin(n, p)
X takes values 0, 1, …, n
E.g. coin flips
p(X = i) =
n
i
pi
(1 p)ni](https://image.slidesharecdn.com/probabilitystatisticsassignmenthelp-190920152427/85/Probability-statistics-assignment-help-11-320.jpg)