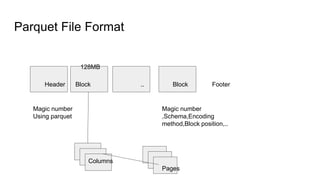
Apache Parquet is a columnar storage format that can efficiently store nested data. It allows nested fields to be read independently of other fields. Many data processing systems like Hive, Spark, Pig and MapReduce can understand the Avro format used by Parquet. Parquet uses encoding and compression techniques like run-length encoding, dictionary encoding, and compression algorithms like Snappy and gzip to improve file size and query performance. The Parquet file format consists of a header, blocks with columns and pages, and a footer to store metadata.



























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)








![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









