Download to read offline











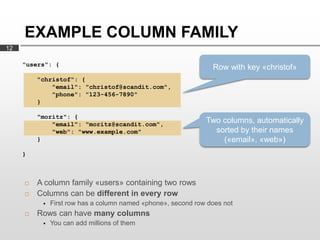


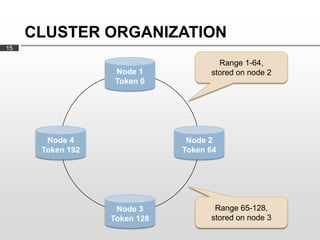
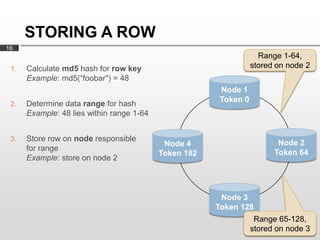


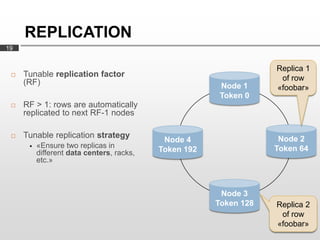
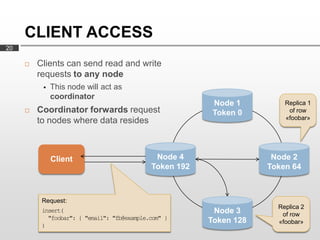





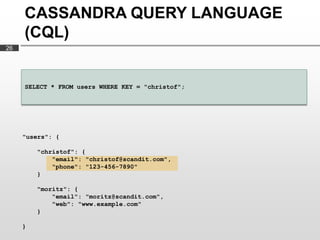
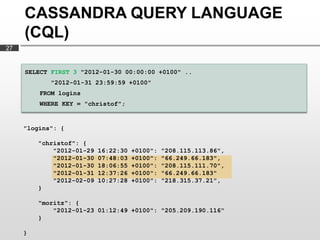




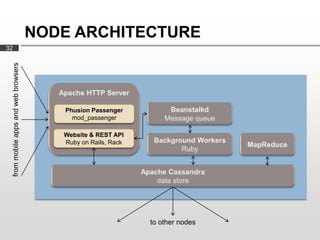


Cassandra is used as the backend database for Scandit's barcode and product scanning platform. It provides high scalability and availability needed to store large volumes of product data and scan data. Cassandra's data model uses a column family structure and allows storing data flexibly in column names. It is optimized for write-heavy workloads and scales easily by adding more nodes.









































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





