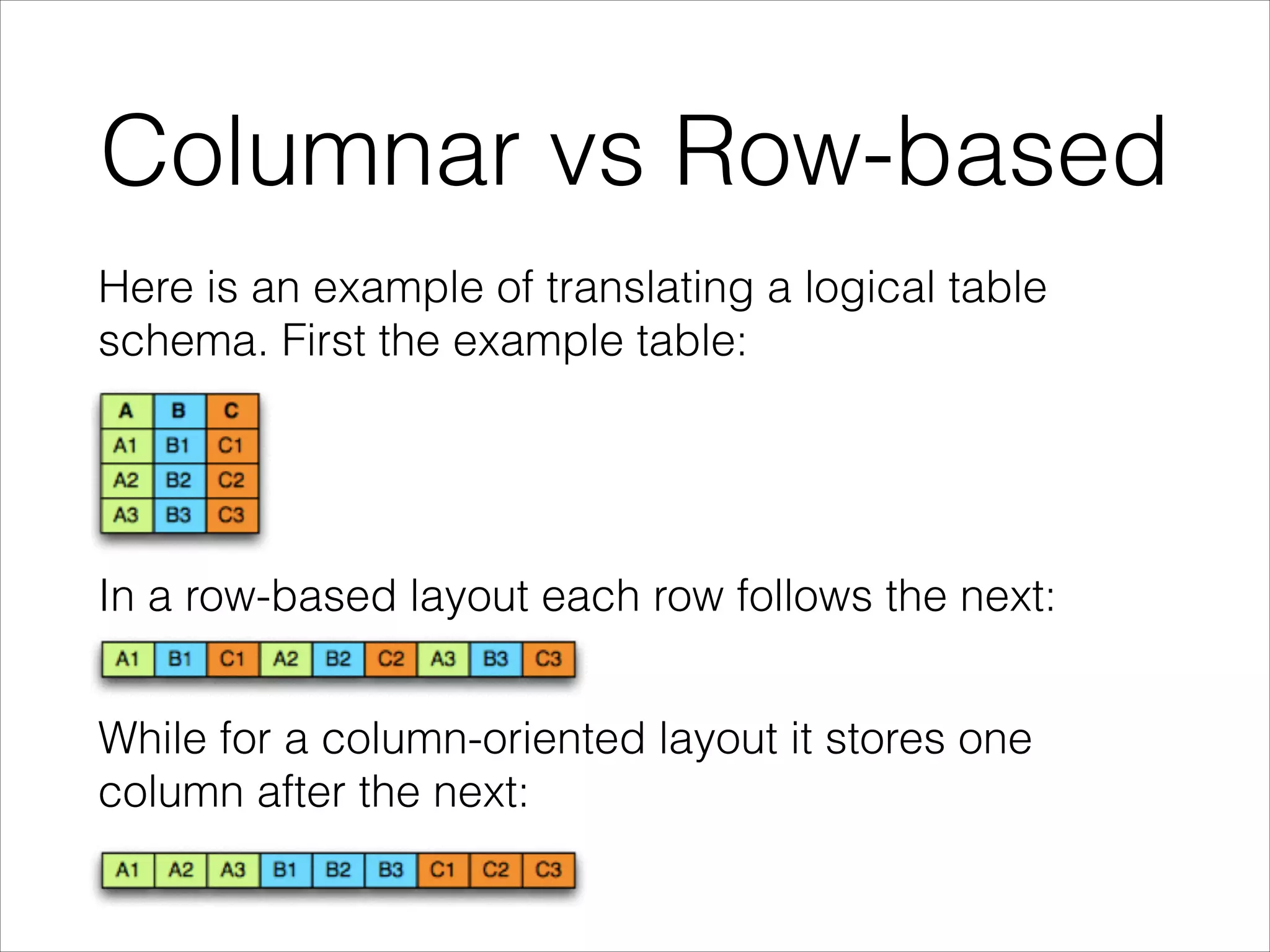
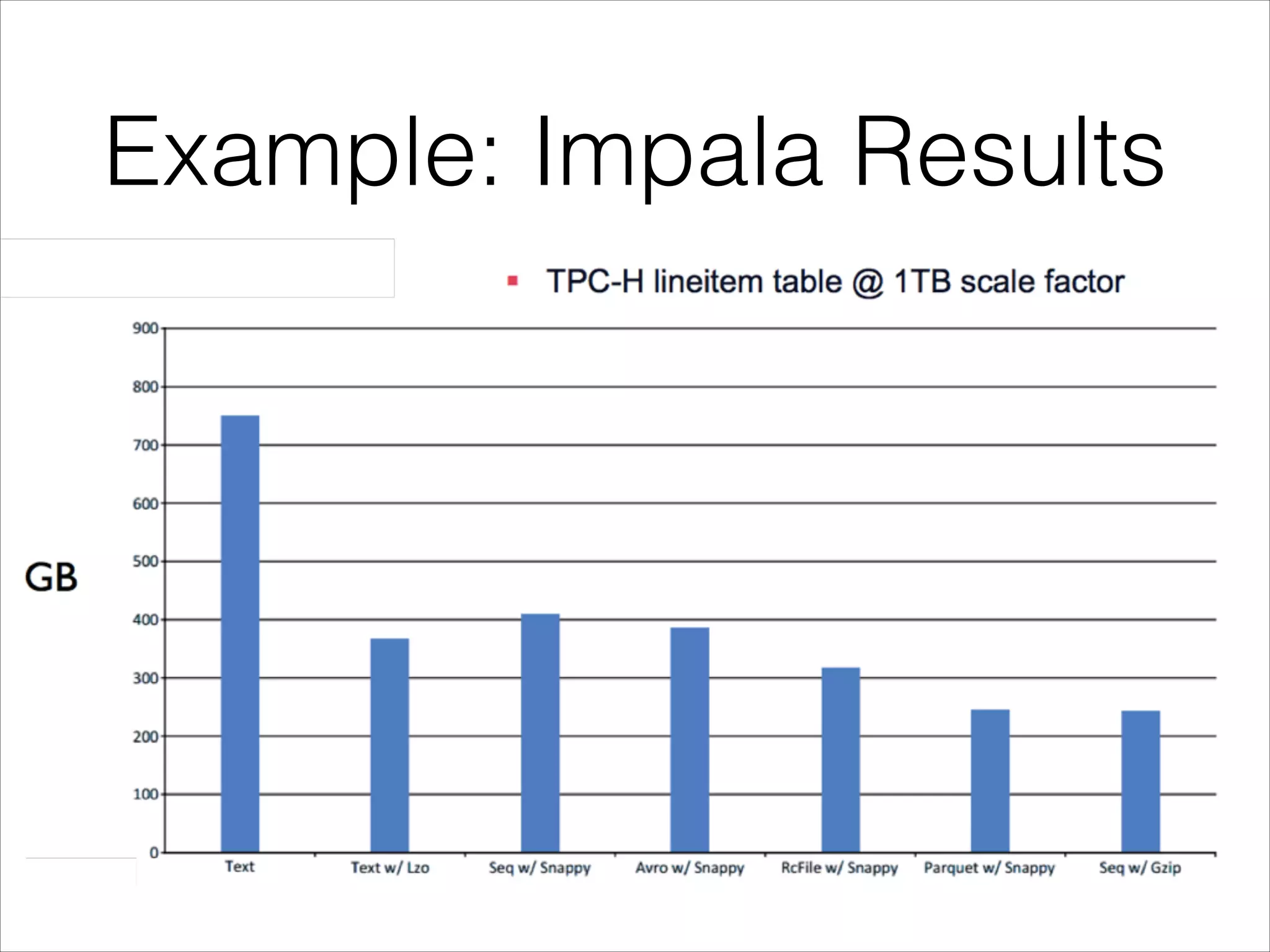
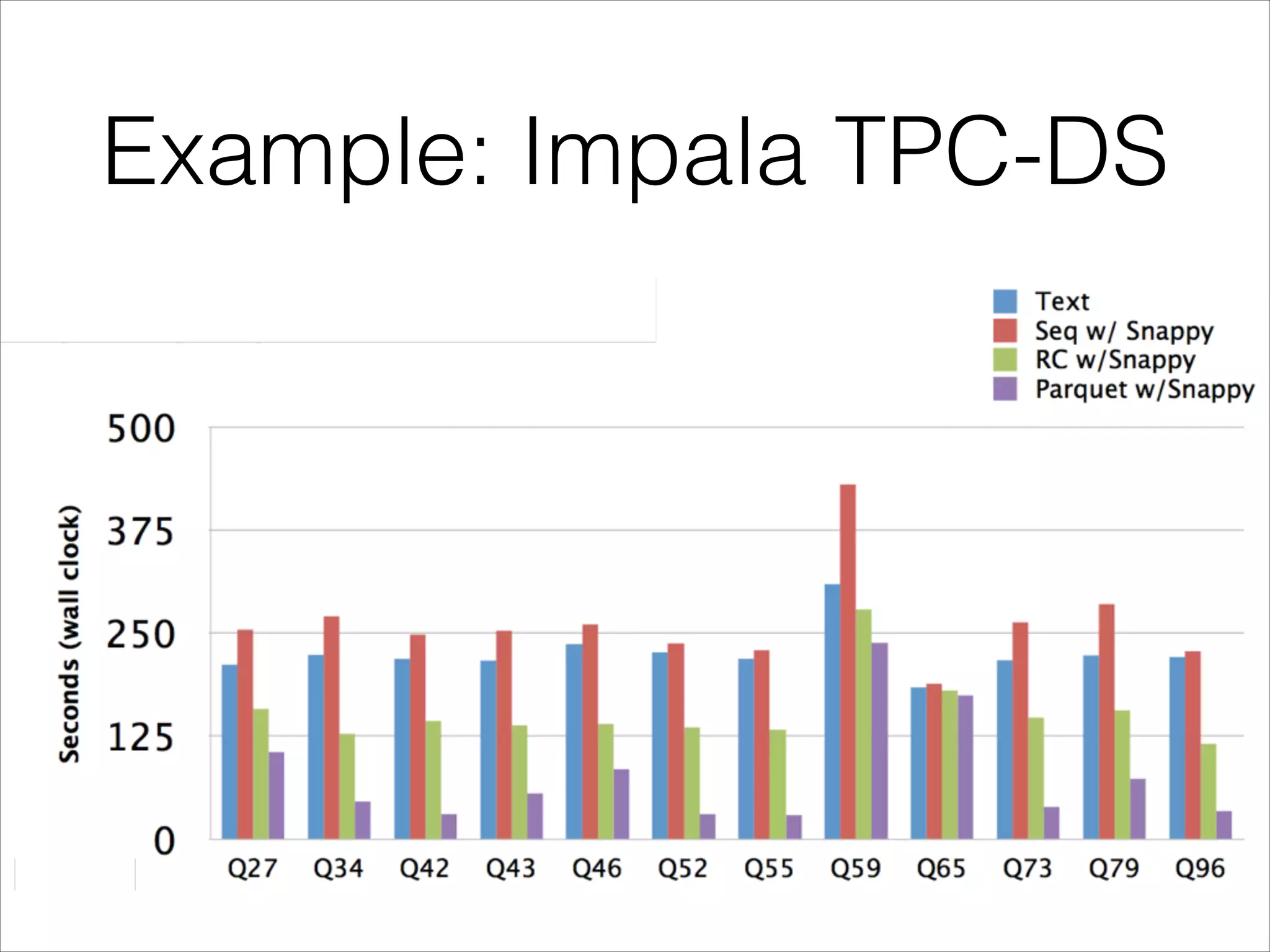
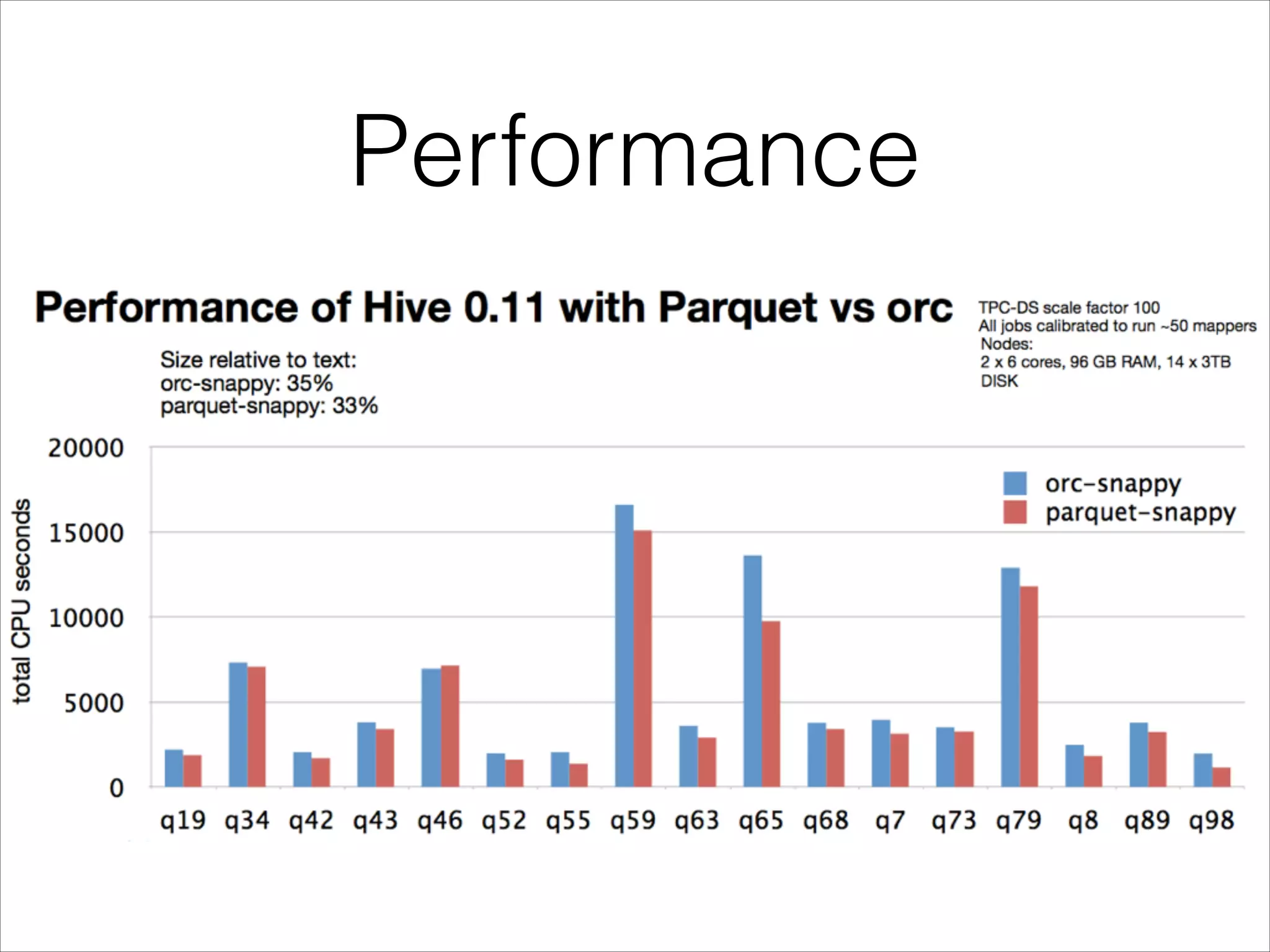
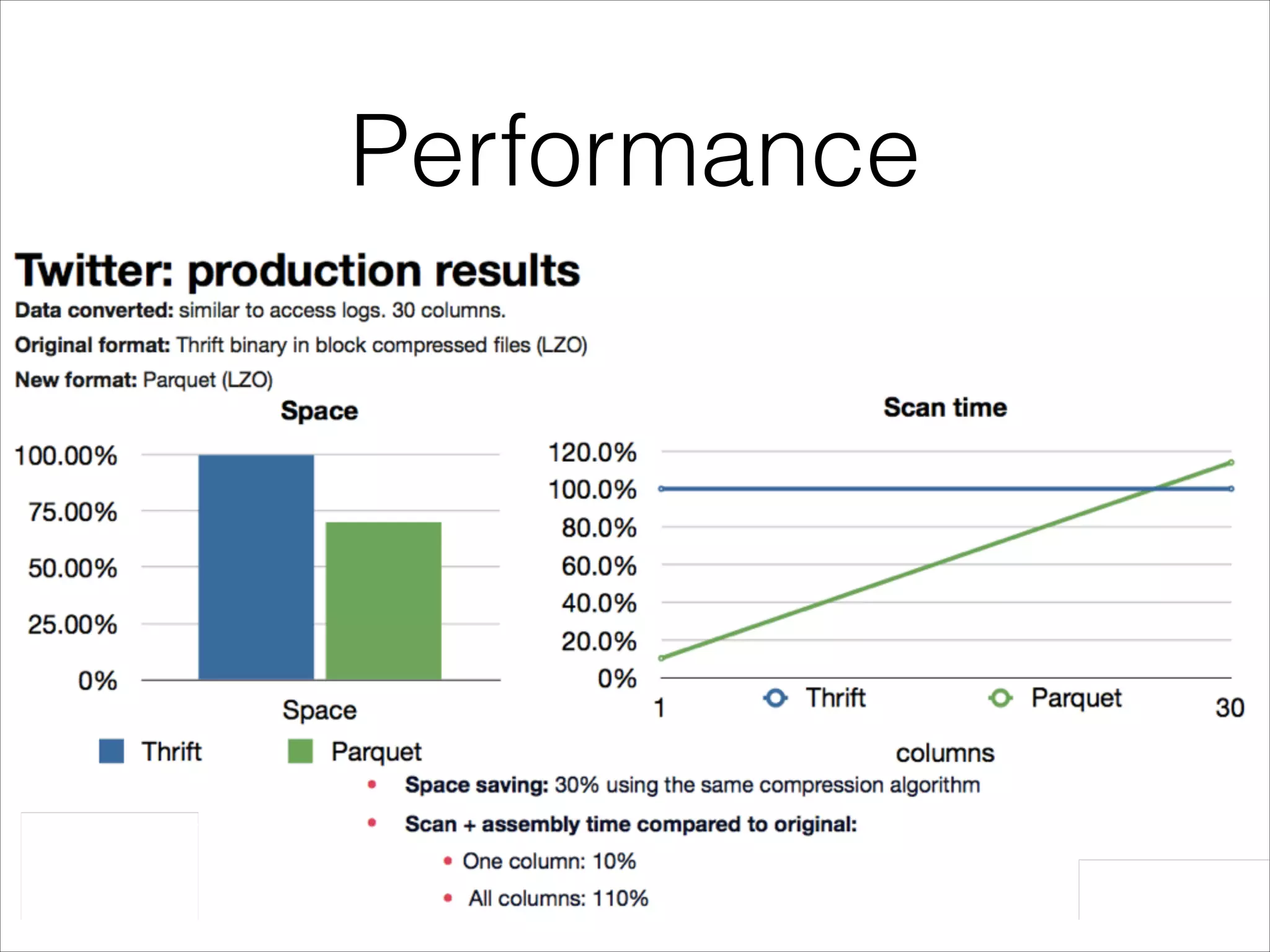
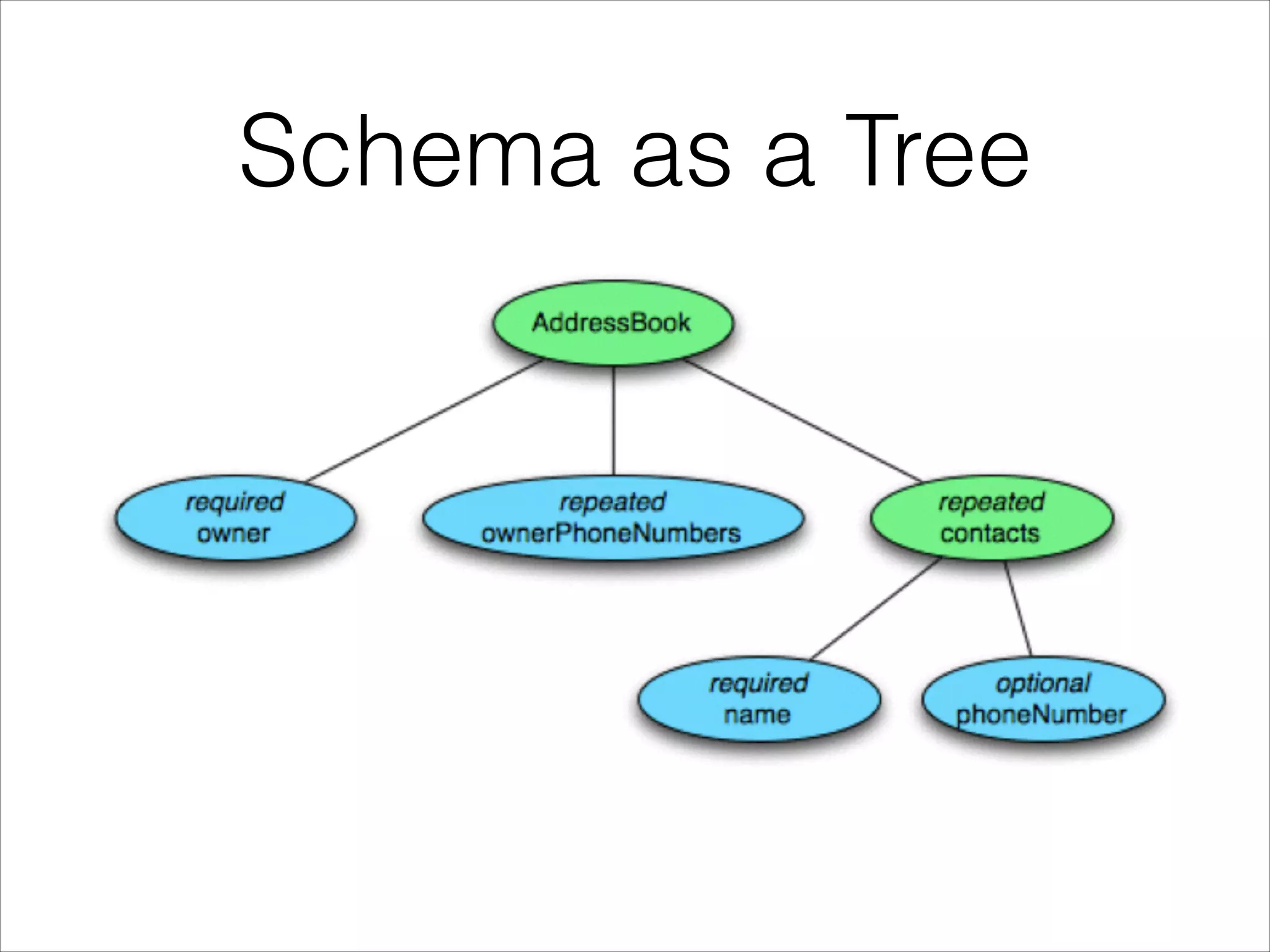
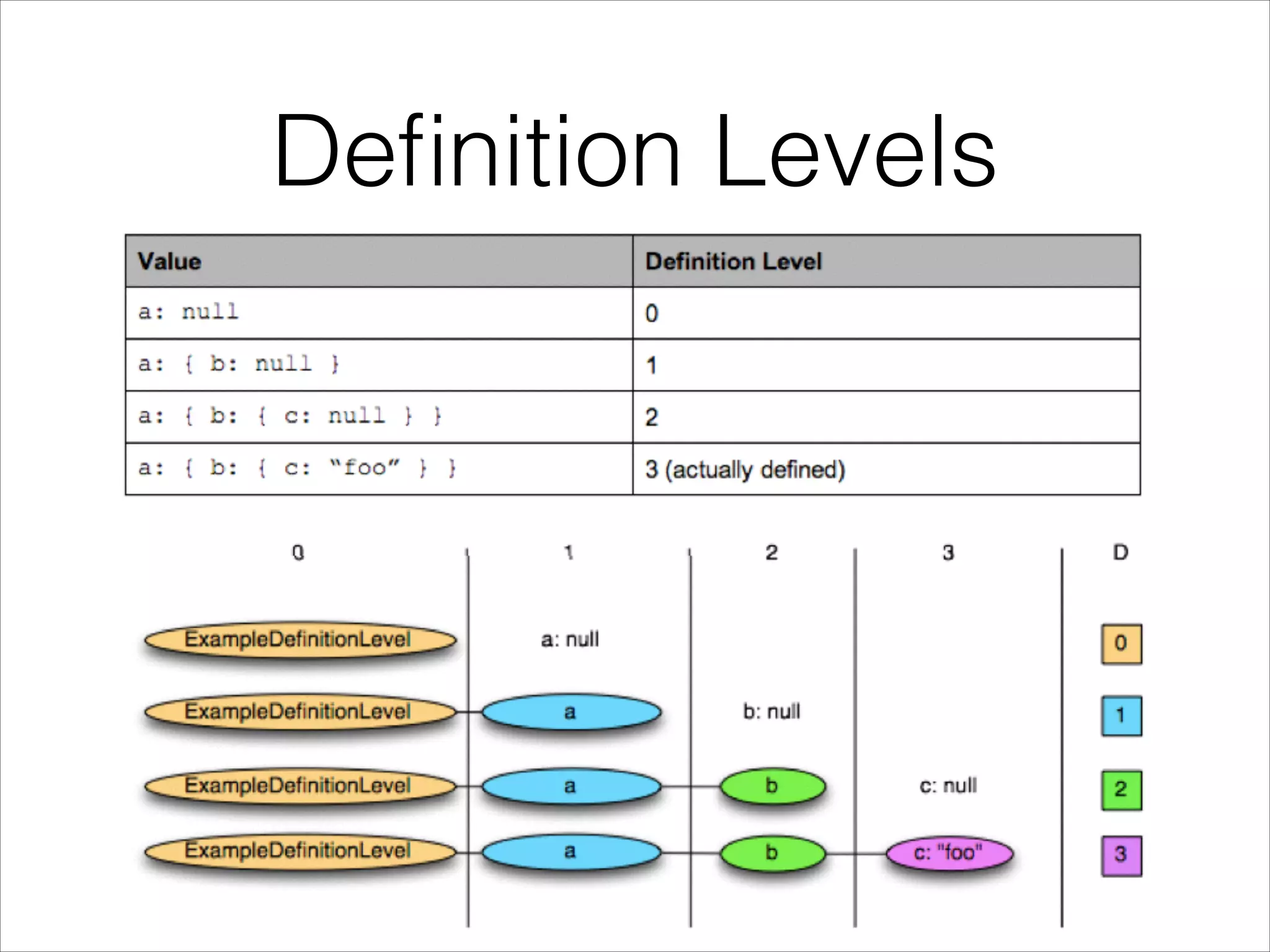
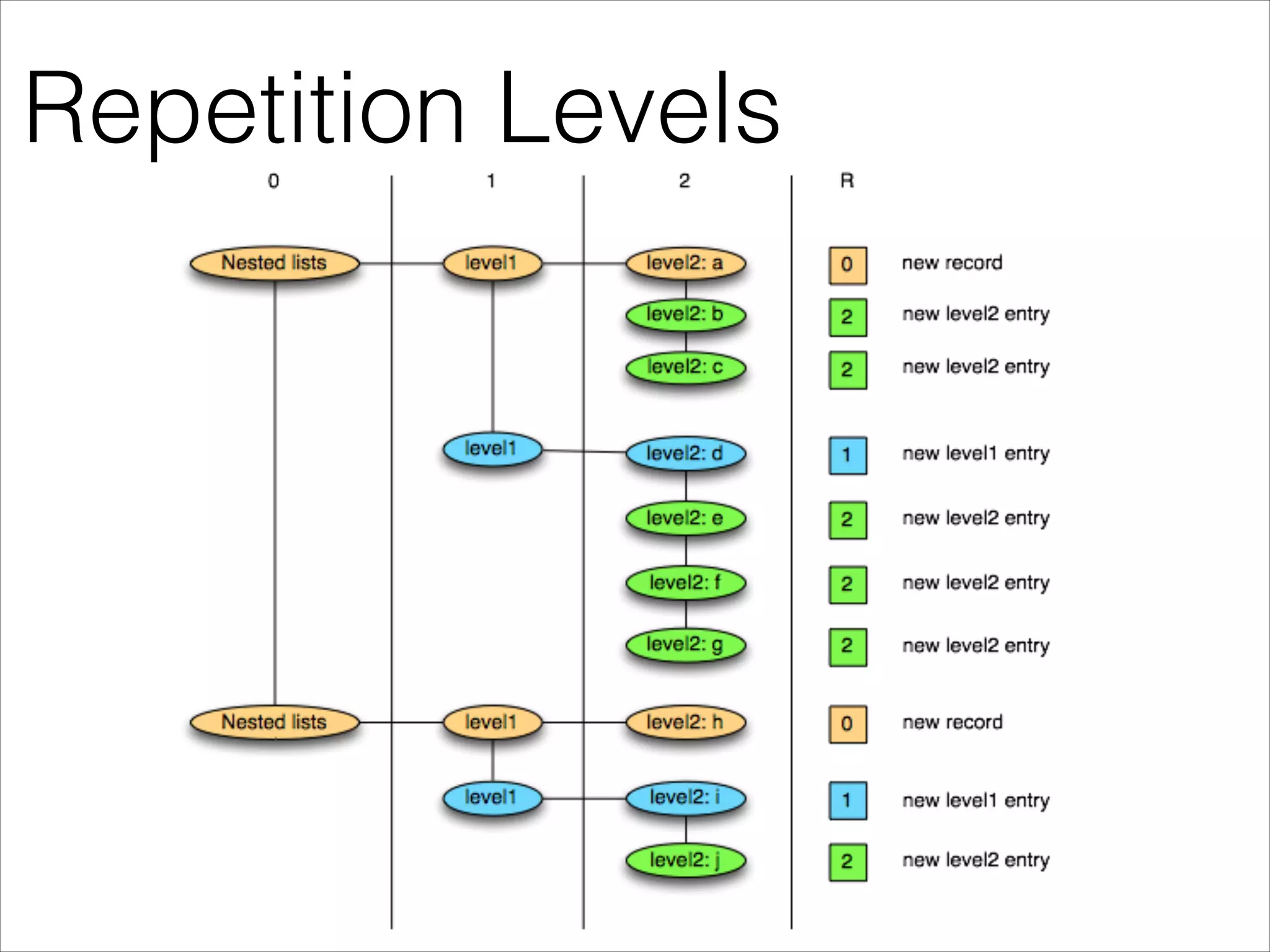
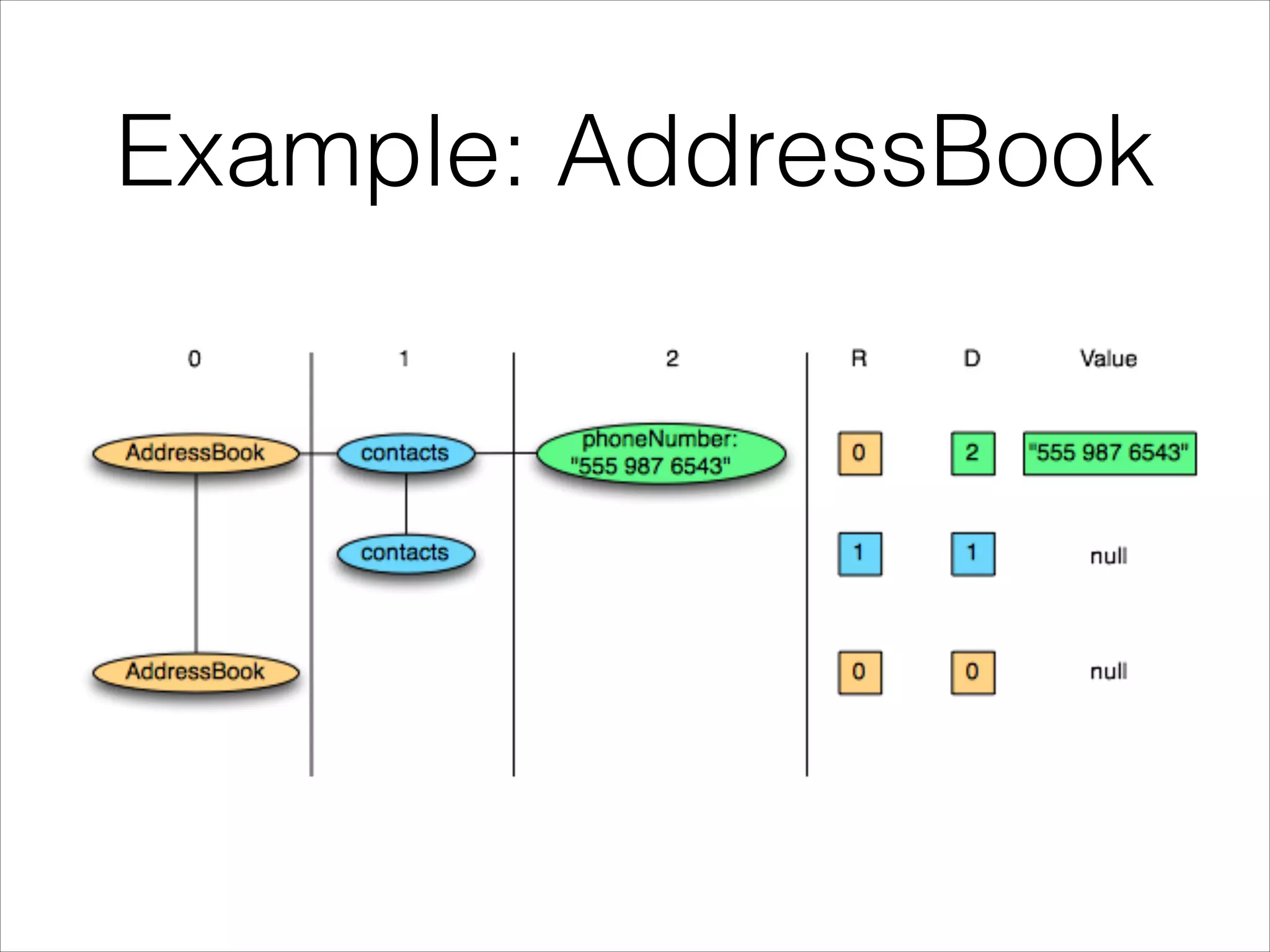
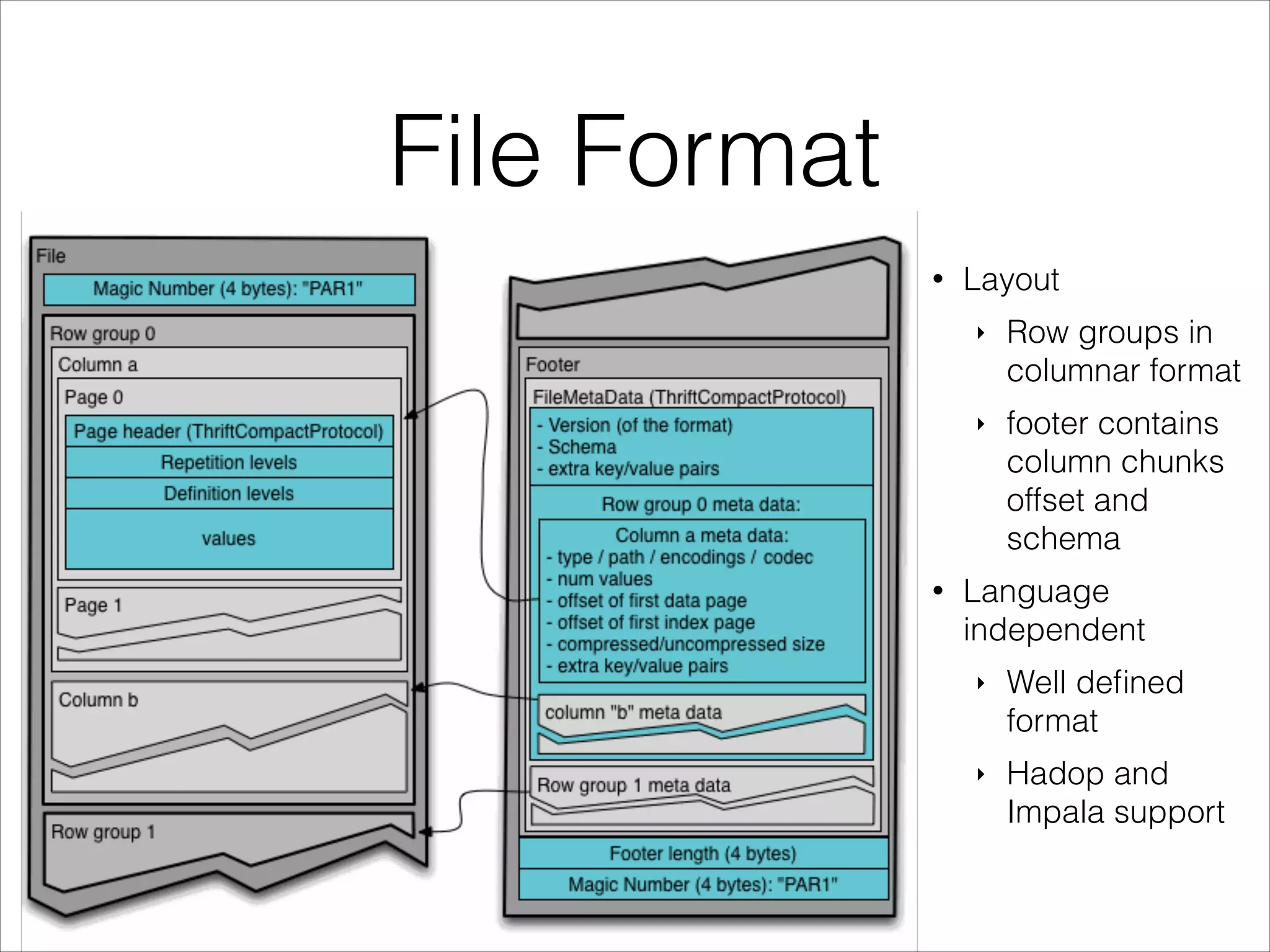
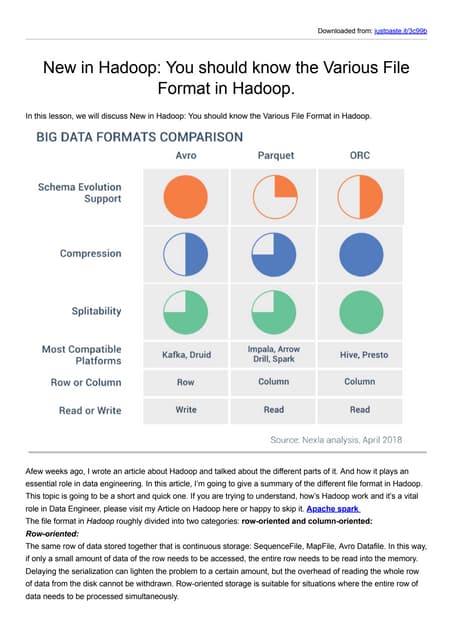
Parquet is an open-source columnar storage format that provides an efficient data layout for analytical queries. Twitter uses Parquet to store logs and analytics data across multiple large Hadoop clusters, saving petabytes of storage and reducing query times by up to 66% by reading only needed columns. Parquet defines a language-independent file format that stores data by column rather than row to optimize analytical access patterns.