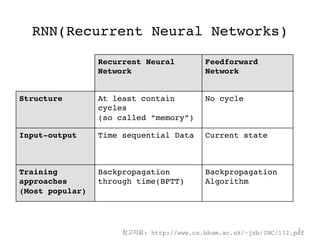
RNN(Recurrent Neural Networks)
RecurrentNeural
Network
Feedforward
Network
Structure At least contain
cycles
(so called “memory”)
No cycle
Input-output Time sequential Data Current state
Training
approaches
(Most popular)
Backpropagation
through time(BPTT)
Backpropagation
Algorithm
참고자료: http://www.cs.bham.ac.uk/~jxb/INC/l12.pdf
2
3.
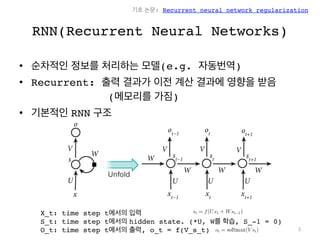
RNN(Recurrent Neural Networks)
• 순차적인 정보를 처리하는 모델(e.g. 자동번역)
• Recurrent: 출력 결과가 이전 계산 결과에 영향을 받음
(메모리를 가짐)
• 기본적인 RNN 구조
X_t: time step t에서의 입력
S_t: time step t에서의 hidden state. (*U, W를 학습, S_-1 = 0)
O_t: time step t에서의 출력, o_t = f(V_s_t)
기초 논문: Recurrent neural network regularization
3
4.
RNN(Recurrent Neural Networks)
X_t:time step t에서의 입력
S_t: time step t에서의 hidden state. (*U, W를 학습, S_-1 = 0)
O_t: time step t에서의 출력 (e.g. 자동번역, 단어 완성)
[Note]
• Hidden state S_t는 과거 모든 정보를 담고 있고, O_t는 현재 정보
애 대한 Output이다
• RNN은 모든 시간 스텝에 대하여 같은 파라미터를 공유한다. (U,V,W)
(Long-term dependency 문제 발생) 4
5.
RNN(Recurrent Neural Networks)
X_t:time step t에서의 입력
S_t: time step t에서의 hidden state. (*U, W를 학습, S_-1 = 0)
O_t: time step t에서의 출력 (e.g. 자동번역 단어 벡터)
[Note]
• Hidden state S_t는 과거 모든 정보를 담고 있고, O_t는 현재 정보
애 대한 Output이다
• RNN은 모든 시간 스텝에 대하여 같은 파라미터를 공유한다. (U,V,W)
(Long-term dependency 문제 발생) 5
6.
RNN(Recurrent Neural Networks)
RNN의학습은 BPTT(Backpropagation Through Time)으로 진행되는데,
이것은 t_n의 U,V,W를 학습하기 위해서 t_1 – t_n-1 까지의 state를 모두 더
해야 함을 의미하고, Exploding/Vanishing Gradients의 문제로 학습하기
어렵다고 발표된 바 있다.
(Bengio, On the difficulty of training recurrent neural networks)
• Explosion은 long term components를 학습할 때 일어남
• Vanish는 다음 event에 대하여 correlation을 학습하는 와중에 일어남
(delta weight가 0)
[Note] 논문 2. Exploding and vanishing gradients
6
7.
RNN(Recurrent Neural Networks)
RNN의학습은 BPTT(Backpropagation Through Time) 대신 단기 BPTT
(Truncated Backpropagation Through Time)로 대체되기도 하는데,
이와 같은 경우 장기적으로 남아있어야 할 메모리가 유실된다고 알려져 있다.
BPTT
TBPTT
7
8.
RNN(Recurrent Neural Networks)
RNN학습: BPTT(Backpropagation Through Time)
8http://kiyukuta.github.io/2013/12/09/mlac2013_day9_recurrent_neural_network_language_model.html
Green: 얼마나 잘못되었는지 기록
Orange: Green차이만큼 update
RNN(Recurrent Neural Networks)
RNN학습: BPTT(Backpropagation Through Time)
10http://kiyukuta.github.io/2013/12/09/mlac2013_day9_recurrent_neural_network_language_model.html
e_h(t): error in the hidden layer
U(t+1) = U(t) + (0 ~ t-1)시점 [weight]*err*[lr] – U(t)*beta
W(t+1) = W(t) + (0 ~ t-1)시점 [recurrent state]*err*[lr] – W(t)*beta
d_h: differential of the sigmoid function
11.
RNN(Recurrent Neural Networks)
RNN학습: BPTT(Backpropagation Through Time)
11http://kiyukuta.github.io/2013/12/09/mlac2013_day9_recurrent_neural_network_language_model.html
e_h(t-tau-1): error of the past hidden layer
e_h(t-tau): is the weight W flowing in the oppositie direction
d_h: differential of the sigmoid function
12.
RNN(Recurrent Neural Networks)
그외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
12http://aikorea.org/blog/rnn-tutorial-1/
step t 이후의 출력값이 입력값에도 영향을
받을 수 있다는 아이디어에서 나온 모델. 두 개의
RNN이 동시에 존재하고, 출력값은 두 개의 RNN
hidden state에 의존한다.
Bidirectional RNN:
13.
RNN(Recurrent Neural Networks)
그외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
13http://aikorea.org/blog/rnn-tutorial-1/
Bidirectional RNN에서 매 시간 step마
다 추가적인 layer를 두어 구성한 RNN. 계산
capacity가 크고, 학습 데이터는 훨씬 더 많
이 필요하다.
Deep Bidirectional RNN:
14.
RNN(Recurrent Neural Networks)
그외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
14http://aikorea.org/blog/rnn-tutorial-1/
RNN이 과거 time step t를 학습하여 추론하
는 과정에서 장기 의존성(long term
dependency)이 떨어진다는 단점을 극복하기
위하여 나온 네트워크. 때문에 weight를 학습
한다기 보다는 어떠한 정보를 버리고(forgot)
update할지에 초점을 맞춘 구조.
LSTM은 RNN의 뉴런 대신에 [메모리 셀]이라는
구조를 사용하여 forgot, 현재 state에 남
길 값을 결정한다.
LSTM Network:
15.
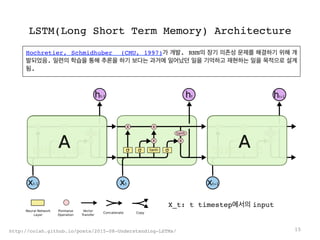
LSTM(Long Short TermMemory) Architecture
Hochretier, Schmidhuber (CMU, 1997)가 개발. RNN의 장기 의존성 문제를 해결하기 위해 개
발되었음. 일련의 학습을 통해 추론을 하기 보다는 과거에 일어났던 일을 기억하고 재현하는 일을 목적으로 설계
됨.
15http://colah.github.io/posts/2015-08-Understanding-LSTMs/
X_t: t timestep에서의 input
16.
LSTM(Long Short TermMemory) Architecture
Hochretier, Schmidhuber (CMU, 1997)가 개발. RNN의 장기 의존성 문제를 해결하기 위해 개
발되었음. 일련의 학습을 통해 추론을 하기 보다는 과거에 일어났던 일을 기억하고 재현하는 일을 목적으로 설계
됨. 메모리 셀 C가 들어간 버전은 Gers et al. 2000이 소개하였음.
16http://colah.github.io/posts/2015-08-Understanding-LSTMs/
X_t: t timestep에서의 input
C_t: Cell state, 정보를 더하거나 지울지 정함
17.
LSTM(Long Short TermMemory) Architecture
17http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Forget gate층은 h_[t-1]과 x_t를 보고, sigmoid를 통과시켜 C_[t-1]에서의 각 숫자
를 위한 0과 1 사이의 숫자를 출력함. Output인 f_t()가 forget gate.
18.
LSTM(Long Short TermMemory) Architecture
18http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Input gate층은 i_t()로 어떤 값을 갱신할지 결정한다. Tanh()층은 셀 상태에서 추가될 수
있는 후보들의 벡터인 [C_t]^~를 생성한다. 다음 단계에서 셀 스테이트 C를 갱신한다.
19.
LSTM(Long Short TermMemory) Architecture
19http://colah.github.io/posts/2015-08-Understanding-LSTMs/
새로운 셀 스테이트 C_t는 forget gate를 통과한 과거 셀 상태 C_[t-1]과 input gate를
통과한 새로운 후보 셀 스테이트 [C_t]^~와의 합으로 구성된다. 이는 셀 스테이트 값을 얼만큼 갱신
할지 결정한 값으로 크기 변경된(scaled) 새 후보들이 된다. 이러한 셀 state는 gradient 곱
이 발생하지 않기 때문에 exploding이나 vanishing이 발생하지 않는다.셀 state가 장기 기
억이 가능하게 되는 이유다.
20.
LSTM(Long Short TermMemory) Architecture
20http://colah.github.io/posts/2015-08-Understanding-LSTMs/
h_t는 출력을 의미하며 o_t()는 Output gate이다. Output gate는 Hidden
state(h_[t-1])와 현재 input x_t를 확인하고 어떤 부분을 출력할지 결정한다. 새로운
Hidden layer는 새로 갱신한 Cell state에 Output gate 결과를 반영하여 결정된다.
21.
LSTM(Long Short TermMemory) Architecture
21http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
¤: element-wise multiplication
h_t^l: layer l의 time stamp t일때 hidden state
• RNN에는 Dropout을 붙이면 잘 동작하지 않는다고 알려져 있는데, dropout이 지워버려선 안
되는 과거 information이 지워지기 때문이라고 한다.(Recurrent Neural Network
Regularization, ICLR 2015) 참고로 이러한 이유 때문에 Dropout 연산은
Recurrent connection이 아닌 곳에서만 적용하는 것이 위 논문의 아이디어다.
g^t() = cell state 후보
[LSTM feed forward pass]
22.
LSTM(Long Short TermMemory) Architecture
22http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• LSTM은 구조에 따라 다양한 용례로 사용할 수 있음
• 2D Tensor는 # of inputs,# of examples로 구성되며
• 3D Tensor는 [2D Tensor]에 Timesteps가 포함된다. 즉 (덩어리)를 input으로 사용
[LSTM 용례]
23.
LSTM(Long Short TermMemory) Architecture
23http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• 각 게이트(forget, input, output)마다 셀 상태를 추가로 참고할 수 있도록 하여 게이트
들이 과거 데이터에 조금 더 의존적으로 계산을 수행하도록 만든 LSTM
• Gers and Schmidhuber (2000)
[LSTM 변형: Peephole connection]
24.
LSTM(Long Short TermMemory) Architecture
24http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• Forget gate와 input gate를 단일 Cell update gate로 통합함
• Input gate가 사라지는 대신, input은 후보 셀 스테이트를 결정하고 새 hidden state
를 결정하는데 사용됨
• 결과 모델은 표준 LSTM 모델보다 단순함
• Cho et al. (2014)
[LSTM 변형: GRU(Gated Recurrent Unit)]
25.
LSTM(Long Short TermMemory) Architecture
25
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
[LSTM 변형: 그 외]
26.
LSTM(Long Short TermMemory) Architecture
26
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
[LSTM 변형: 그 외]
27.
LSTM(Long Short TermMemory) Architecture
27
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
• [Answer]: 거실
[LSTM 변형: 그 외]
28.
LSTM(Long Short TermMemory) Architecture
28
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
• [Answer]: 거실
• Show, Attend and Tell, Kelvin Xu et al. (2015)
[LSTM 변형: 그 외]

![RNN(Recurrent Neural Networks)
X_t: time step t에서의 입력
S_t: time step t에서의 hidden state. (*U, W를 학습, S_-1 = 0)
O_t: time step t에서의 출력 (e.g. 자동번역, 단어 완성)
[Note]
• Hidden state S_t는 과거 모든 정보를 담고 있고, O_t는 현재 정보
애 대한 Output이다
• RNN은 모든 시간 스텝에 대하여 같은 파라미터를 공유한다. (U,V,W)
(Long-term dependency 문제 발생) 4](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-4-320.jpg)
![RNN(Recurrent Neural Networks)
X_t: time step t에서의 입력
S_t: time step t에서의 hidden state. (*U, W를 학습, S_-1 = 0)
O_t: time step t에서의 출력 (e.g. 자동번역 단어 벡터)
[Note]
• Hidden state S_t는 과거 모든 정보를 담고 있고, O_t는 현재 정보
애 대한 Output이다
• RNN은 모든 시간 스텝에 대하여 같은 파라미터를 공유한다. (U,V,W)
(Long-term dependency 문제 발생) 5](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-5-320.jpg)
![RNN(Recurrent Neural Networks)
RNN의 학습은 BPTT(Backpropagation Through Time)으로 진행되는데,
이것은 t_n의 U,V,W를 학습하기 위해서 t_1 – t_n-1 까지의 state를 모두 더
해야 함을 의미하고, Exploding/Vanishing Gradients의 문제로 학습하기
어렵다고 발표된 바 있다.
(Bengio, On the difficulty of training recurrent neural networks)
• Explosion은 long term components를 학습할 때 일어남
• Vanish는 다음 event에 대하여 correlation을 학습하는 와중에 일어남
(delta weight가 0)
[Note] 논문 2. Exploding and vanishing gradients
6](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-6-320.jpg)



![RNN(Recurrent Neural Networks)
RNN 학습: BPTT(Backpropagation Through Time)
10http://kiyukuta.github.io/2013/12/09/mlac2013_day9_recurrent_neural_network_language_model.html
e_h(t): error in the hidden layer
U(t+1) = U(t) + (0 ~ t-1)시점 [weight]*err*[lr] – U(t)*beta
W(t+1) = W(t) + (0 ~ t-1)시점 [recurrent state]*err*[lr] – W(t)*beta
d_h: differential of the sigmoid function](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-10-320.jpg)

![RNN(Recurrent Neural Networks)
그 외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
12http://aikorea.org/blog/rnn-tutorial-1/
step t 이후의 출력값이 입력값에도 영향을
받을 수 있다는 아이디어에서 나온 모델. 두 개의
RNN이 동시에 존재하고, 출력값은 두 개의 RNN
hidden state에 의존한다.
Bidirectional RNN:](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-12-320.jpg)
![RNN(Recurrent Neural Networks)
그 외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
13http://aikorea.org/blog/rnn-tutorial-1/
Bidirectional RNN에서 매 시간 step마
다 추가적인 layer를 두어 구성한 RNN. 계산
capacity가 크고, 학습 데이터는 훨씬 더 많
이 필요하다.
Deep Bidirectional RNN:](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-13-320.jpg)
![RNN(Recurrent Neural Networks)
그 외 RNN, [Bidirectional RNN, Deep (Bidirectional RNN),
LSTM]
14http://aikorea.org/blog/rnn-tutorial-1/
RNN이 과거 time step t를 학습하여 추론하
는 과정에서 장기 의존성(long term
dependency)이 떨어진다는 단점을 극복하기
위하여 나온 네트워크. 때문에 weight를 학습
한다기 보다는 어떠한 정보를 버리고(forgot)
update할지에 초점을 맞춘 구조.
LSTM은 RNN의 뉴런 대신에 [메모리 셀]이라는
구조를 사용하여 forgot, 현재 state에 남
길 값을 결정한다.
LSTM Network:](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-14-320.jpg)

![LSTM(Long Short Term Memory) Architecture
17http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Forget gate층은 h_[t-1]과 x_t를 보고, sigmoid를 통과시켜 C_[t-1]에서의 각 숫자
를 위한 0과 1 사이의 숫자를 출력함. Output인 f_t()가 forget gate.](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-17-320.jpg)
![LSTM(Long Short Term Memory) Architecture
18http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Input gate층은 i_t()로 어떤 값을 갱신할지 결정한다. Tanh()층은 셀 상태에서 추가될 수
있는 후보들의 벡터인 [C_t]^~를 생성한다. 다음 단계에서 셀 스테이트 C를 갱신한다.](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-18-320.jpg)
![LSTM(Long Short Term Memory) Architecture
19http://colah.github.io/posts/2015-08-Understanding-LSTMs/
새로운 셀 스테이트 C_t는 forget gate를 통과한 과거 셀 상태 C_[t-1]과 input gate를
통과한 새로운 후보 셀 스테이트 [C_t]^~와의 합으로 구성된다. 이는 셀 스테이트 값을 얼만큼 갱신
할지 결정한 값으로 크기 변경된(scaled) 새 후보들이 된다. 이러한 셀 state는 gradient 곱
이 발생하지 않기 때문에 exploding이나 vanishing이 발생하지 않는다.셀 state가 장기 기
억이 가능하게 되는 이유다.](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-19-320.jpg)
![LSTM(Long Short Term Memory) Architecture
20http://colah.github.io/posts/2015-08-Understanding-LSTMs/
h_t는 출력을 의미하며 o_t()는 Output gate이다. Output gate는 Hidden
state(h_[t-1])와 현재 input x_t를 확인하고 어떤 부분을 출력할지 결정한다. 새로운
Hidden layer는 새로 갱신한 Cell state에 Output gate 결과를 반영하여 결정된다.](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-20-320.jpg)
![LSTM(Long Short Term Memory) Architecture
21http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
¤: element-wise multiplication
h_t^l: layer l의 time stamp t일때 hidden state
• RNN에는 Dropout을 붙이면 잘 동작하지 않는다고 알려져 있는데, dropout이 지워버려선 안
되는 과거 information이 지워지기 때문이라고 한다.(Recurrent Neural Network
Regularization, ICLR 2015) 참고로 이러한 이유 때문에 Dropout 연산은
Recurrent connection이 아닌 곳에서만 적용하는 것이 위 논문의 아이디어다.
g^t() = cell state 후보
[LSTM feed forward pass]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-21-320.jpg)
![LSTM(Long Short Term Memory) Architecture
22http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• LSTM은 구조에 따라 다양한 용례로 사용할 수 있음
• 2D Tensor는 # of inputs,# of examples로 구성되며
• 3D Tensor는 [2D Tensor]에 Timesteps가 포함된다. 즉 (덩어리)를 input으로 사용
[LSTM 용례]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-22-320.jpg)
![LSTM(Long Short Term Memory) Architecture
23http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• 각 게이트(forget, input, output)마다 셀 상태를 추가로 참고할 수 있도록 하여 게이트
들이 과거 데이터에 조금 더 의존적으로 계산을 수행하도록 만든 LSTM
• Gers and Schmidhuber (2000)
[LSTM 변형: Peephole connection]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-23-320.jpg)
![LSTM(Long Short Term Memory) Architecture
24http://www.slideshare.net/jpatanooga/modeling-electronic-health-records-with-recurrent-neural-networks
• Forget gate와 input gate를 단일 Cell update gate로 통합함
• Input gate가 사라지는 대신, input은 후보 셀 스테이트를 결정하고 새 hidden state
를 결정하는데 사용됨
• 결과 모델은 표준 LSTM 모델보다 단순함
• Cho et al. (2014)
[LSTM 변형: GRU(Gated Recurrent Unit)]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-24-320.jpg)
![LSTM(Long Short Term Memory) Architecture
25
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
[LSTM 변형: 그 외]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-25-320.jpg)
![LSTM(Long Short Term Memory) Architecture
26
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
[LSTM 변형: 그 외]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-26-320.jpg)
![LSTM(Long Short Term Memory) Architecture
27
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
• [Answer]: 거실
[LSTM 변형: 그 외]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-27-320.jpg)
![LSTM(Long Short Term Memory) Architecture
28
• Yao et al. (2015)가 소개한 Depth gated RNNs와 같은 스타일도 있음
• Clockwork RNNs, Koutnik et al. (2014)는 장기 의존성에 효율적으로 작동하도록
변형한 RNN임
• Greff et al. (2015)는 유명한 변형(GRU, Peephole 등)을 비교하는 실험을 통해 결
과가 비슷하다는 것을 발견
• Jozefowics et al. (2015)는 다양한 RNN 변형 모델들을 실험하고 비교함으로써 특정
데이터 세트에 맞는 구조들이 있음을 확인하였음
• LSTM의 다음 단계는 Attention이라고 하는데, 예를 들면 다른것들보다 더 중요한 정보 여러
개를 취합하는 것임
• [Input]: 재현이 침대에서 일어났다.
• [Input]: 재현이 테이블로 가서 사과를 집어들었다.
• [Input]: 그는 사과를 먹었다.
• [Input]: 재현이 거실로 이동했다.
• [Input]: 사과를 떨어뜨렸다.
• [Question]: 재현이 사과를 떨어뜨린 곳은?
• [Answer]: 거실
• Show, Attend and Tell, Kelvin Xu et al. (2015)
[LSTM 변형: 그 외]](https://image.slidesharecdn.com/lstm-161006175729/85/LSTM-28-320.jpg)




![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)












![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[SW Maestro] Team Loclas 1-2 Final Presentation](https://cdn.slidesharecdn.com/ss_thumbnails/smaestrolocals-141122001909-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


