Downloaded 46 times






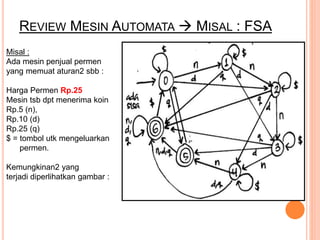
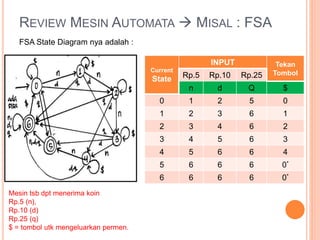
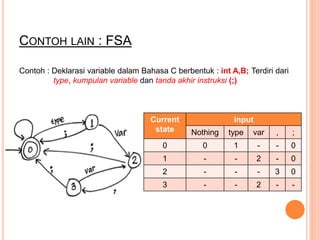
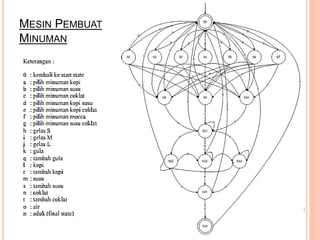

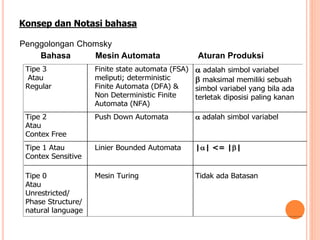







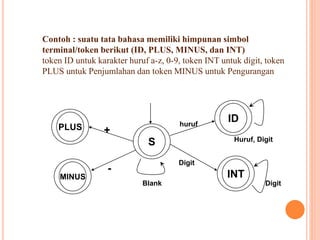

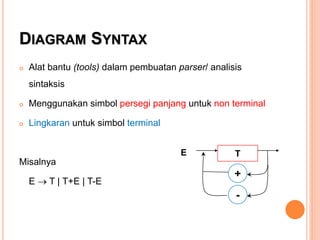
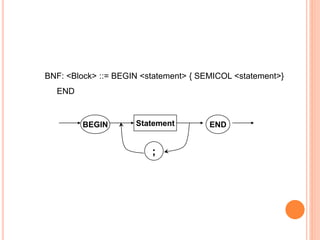



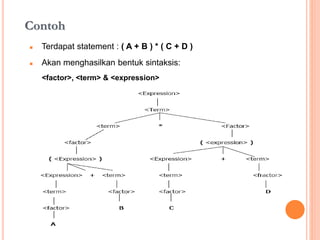
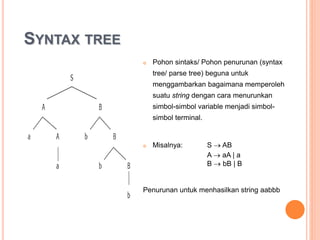

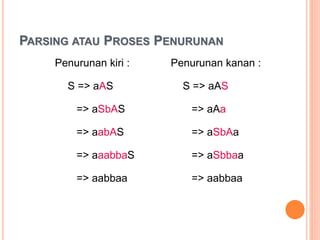
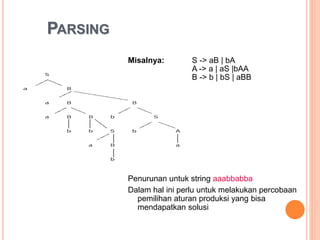


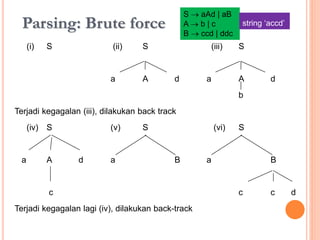


























Dokumen ini membahas konsep dan notasi dalam teori bahasa dan automata, termasuk penggolongan bahasa menurut Hirarki Chomsky, serta tata bahasa dan aturan produksi yang digunakan dalam kompilasi. Selain itu, terdapat penjelasan mengenai mesin otomatis, parsing, dan berbagai jenis automata seperti DFA dan NFA. Dokumen ini juga menguraikan metode untuk menghilangkan rekursif kiri dalam aturan produksi dan tantangan yang dihadapi dalam proses parsing.









































































































