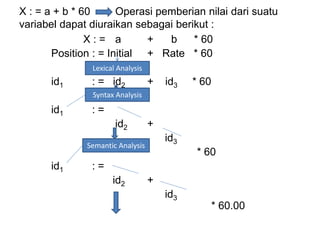
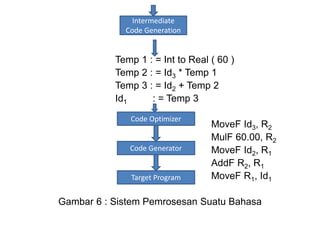
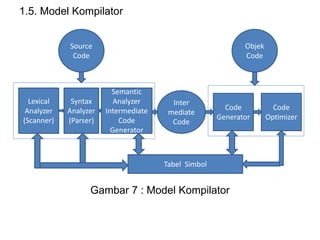
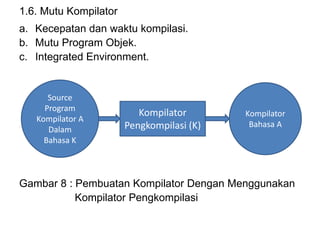
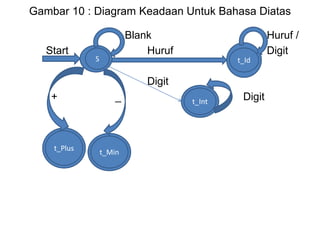
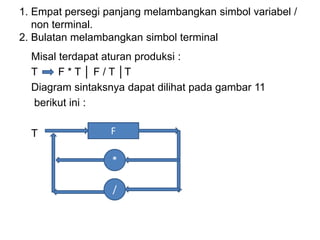
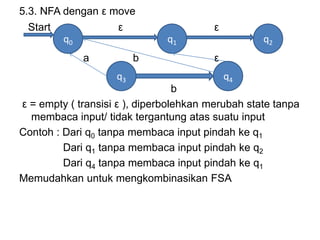
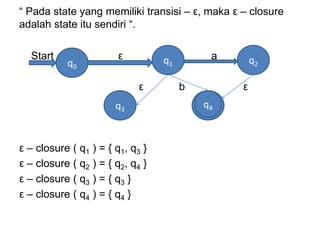
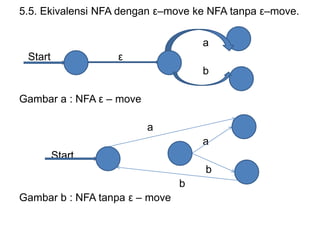
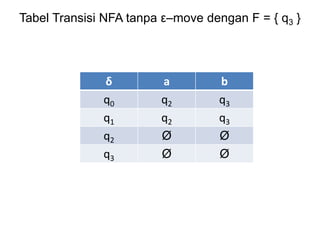
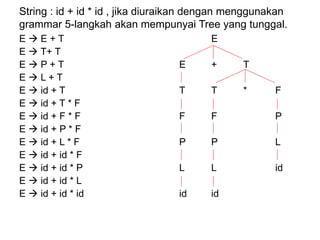
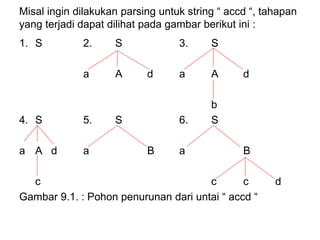
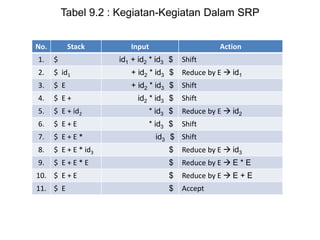
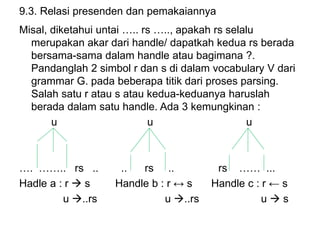
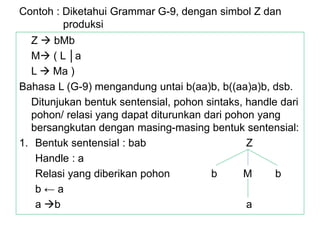
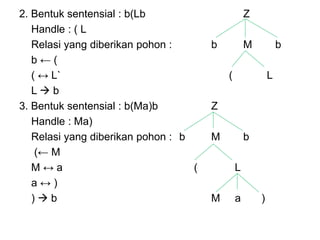
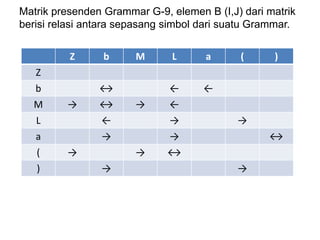
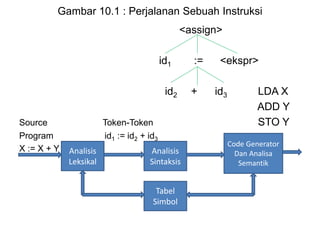
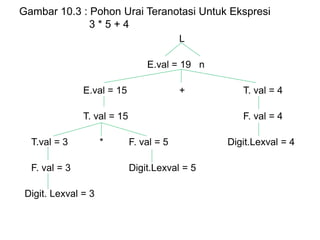
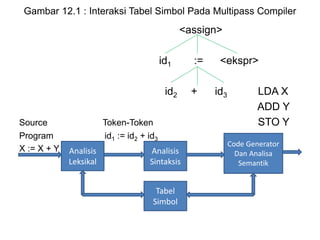
Dokumen ini merupakan pengantar tentang compiler, mencakup terminologi bahasa pemrograman, jenis translator, dan tahapan dalam teknik kompilasi. Penjelasan juga diberikan mengenai analisis leksikal, struktur data, serta desain dan implementasi bahasa pemrograman. Selain itu, dokumen ini menyertakan latihan untuk memperdalam pemahaman mengenai konsep-konsep yang dibahas.


















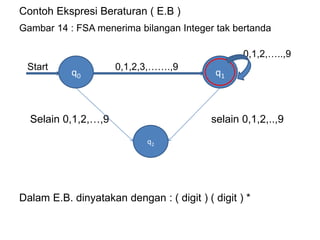



































































![Hal ini didasari pemikiran, sebuah iterasi pada
implementasi level rendah akan memerlukan operasi.
Inisialisasi/ pemberian nilai awal pada variabel loop.
Dilakukan sekali pada saat permulaan eksekusi loop.
Pengetesan apakah variabel loop telah mencapai
kondisi terminasi. Adjusment yaitu penambahan atau
pengurangan nilai pada variabel loop dengan jumlah
tertentu. Operasi yang terjadi pada tubuh perulangan
(Loop Body).
Contoh pada instruksi :
For I := 1 to 2 Do
A [ I ] := 0 ;
Dapat dioptimasikan menjadi : A [ 1 ] := 0 ;
A [ 2 ] := 0 ;
Yang hanya memerlukan dua instruksi assignment saja.](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-119-320.jpg)


















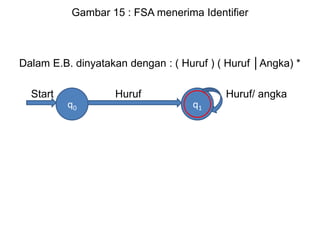
![Tabel array diacu dengan field referensi pada tabel
identifier.
Contoh implementasi tabel array :
tabarray : array [ 1…tabmax ] of record
Indekstype, elementype : types ;
elementref, low, high, elemensize, tabsize, : integer
end;
12.2.3. tabel Blok
Tabel blok digunakan untuk menyimpan informasi-
informasi blok-blok yang ada pada tabel utama. Dengan
berdasarkan pada tabel ini, dapat diketahui batas-batas
suatu blok pada tabel utama ( tabel identifier ).](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-139-320.jpg)
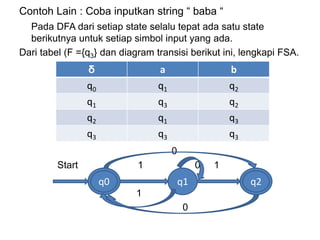
![Tabel Blok memiliki field :
• No. urut blok.
• Batas awal blok.
• Batas akhir blok.
• Ukuran parameter/ parameter size.
• Last variabel.
• Last parameter.
Contoh implementasi tabel blok.
Tabblok : array [ 1…..tabmax ] of record
Lastvar, lastpar, parsize, varsize : integer ;
end;](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-140-320.jpg)

![Untuk blok procedure X :
Last variabel = 4
Variabel size = 2
Last parameter = 3
Parameter size = 1 ( dianggap char butuh satu byte ).
12.2.4. Tabel Real
Tabel real ini digunakan untuk menyimpan nilai dari
suatu identifier yang bertipe real. Elemen-elemen dari
tabel ini adalah sebagai berikut :
• No. urut elemen.
• Nilai real suatu variabel yang mengacu ke indeks tabel.
Contoh implementasi tabel real :
Tabreal : array [ 1….tabmax ] of real](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-142-320.jpg)
![Pemikirannya disini setiap tipe yang dimiliki oleh
suatu bahasa akan memiliki tabelnya sendiri.
12.2.5. Tabel String
Tabel ini digunakan untuk menyimpan informasi
string yang terdapat pada program sumber.
Elemen-elemen yang terdapat dalam tabel ini
adalah :
• No. urut elemen.
• Karakter-karakter yang merupakan konstanta.
Contoh implementasi tabel string :
Tabstring : array [ 1…..tabmax ] of string](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-143-320.jpg)
![12.2.6. Tabel Display
Tabel ini menyimpan informasi mengenai blok-blok
yang lagi aktif. Elemen-elemen yang terdapat di
dalam tabel ini adalah :
• No. urut tabel.
• Blok yang aktif
Pengisian tabel display dilakukan dengan
konsep stack.
Urutan pengaksesan : tabel display – tabel blok-
tabel simbol,
Contoh implementasi tabel display :
tabdisplay : array [ 1….tabmax ] of integer](https://image.slidesharecdn.com/teknikkompilasi-200912050101/85/Teknik-kompilasi-144-320.jpg)








































































![Modul Ajar KBC Al-Qur’an Hadis Kelas 9 MTs [MODULKELAS.COM]](https://cdn.slidesharecdn.com/ss_thumbnails/modulajarkbcal-quranhadiskelas9mtsmodulkelas-260124161811-c72fa7d6-thumbnail.jpg?width=640&height=640&fit=bounds)