Download as PDF, PPTX



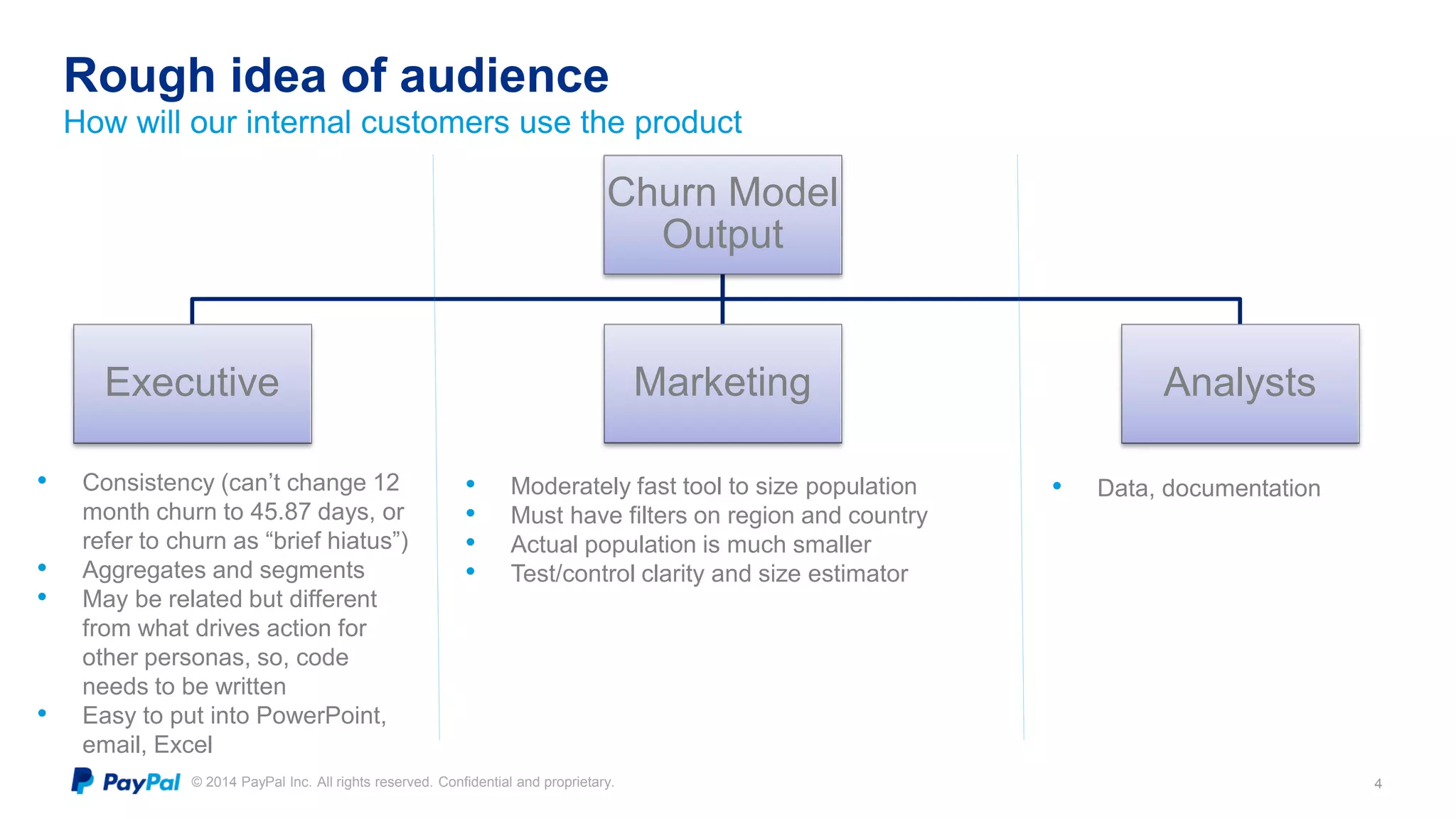
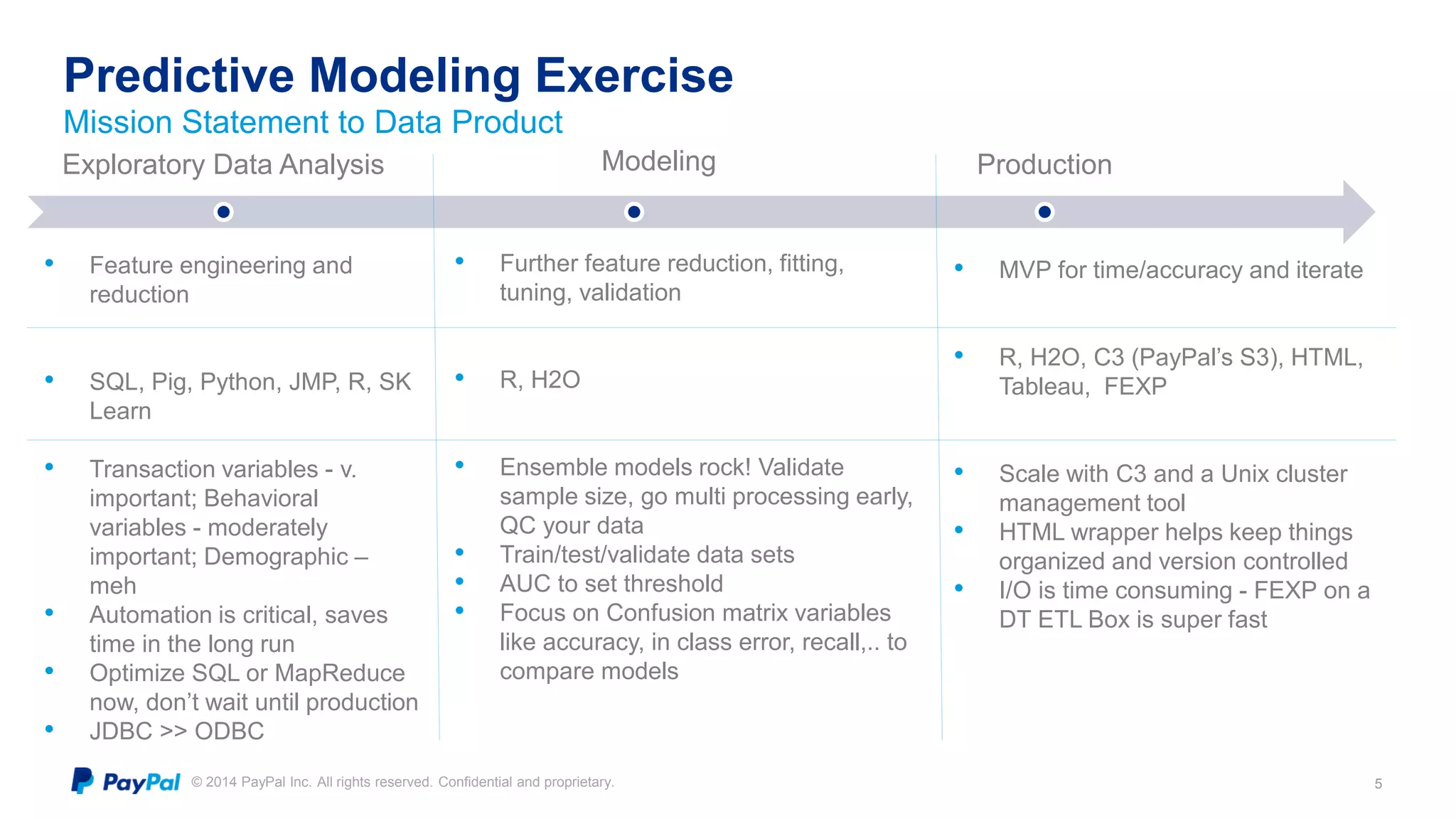

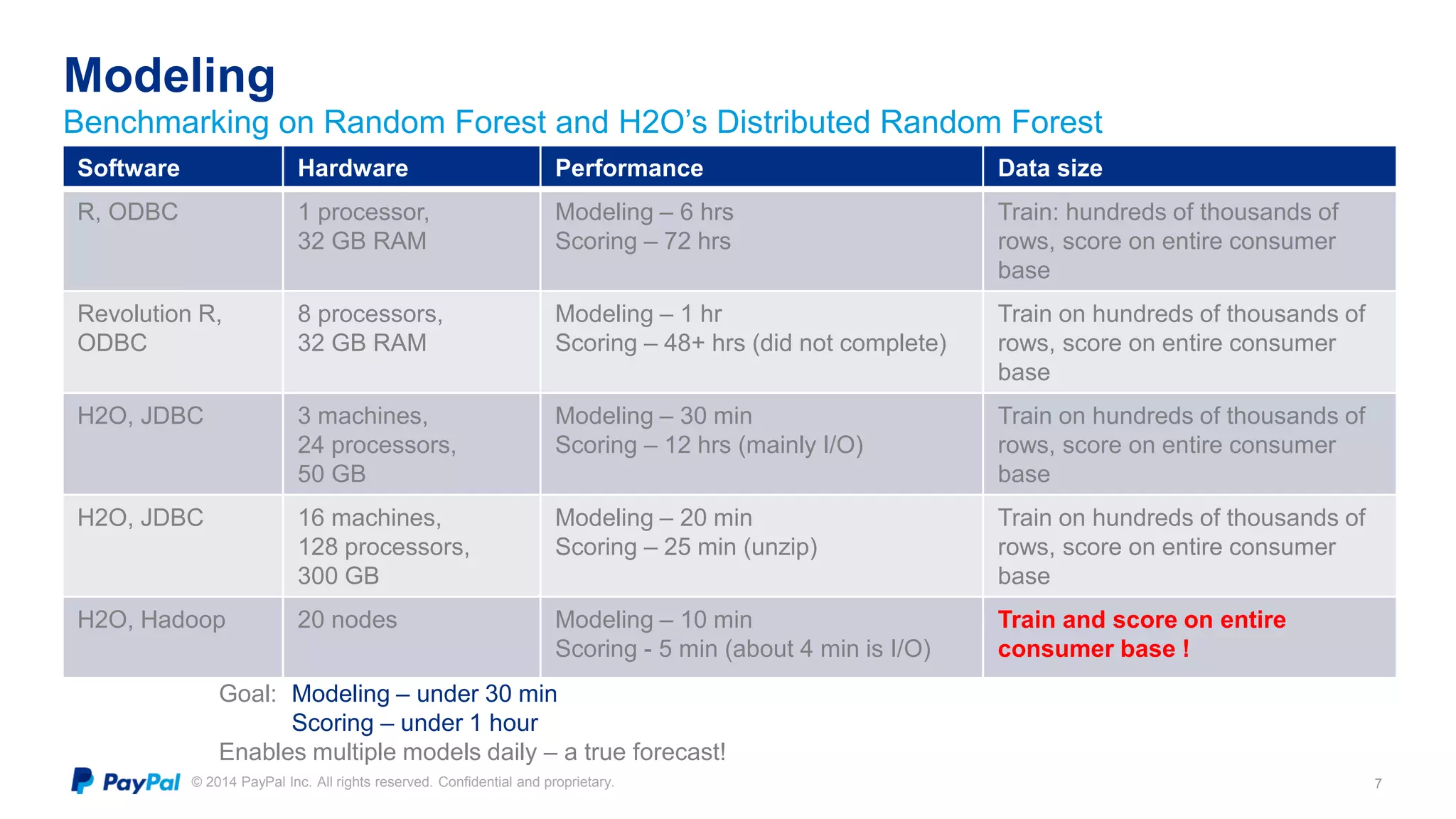



The document discusses PayPal's efforts to develop a consumer churn prediction model. It describes the evolution of their thinking around churn, provides examples of model performance metrics on different datasets and hardware configurations, and discusses lessons learned around feature engineering, model optimization, and productionizing predictive models. The goal is to develop a model that can be run daily to better forecast consumer churn.











































































































