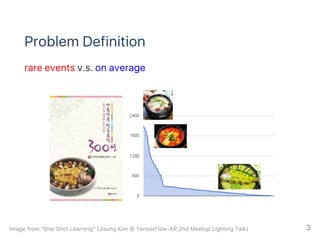
This document summarizes a paper on learning to remember rare events using a memory-augmented neural network. The paper proposes a memory module that stores examples from previous tasks to help learn new rare tasks from only a single example. The memory module is trained end-to-end with the neural network on two tasks: one-shot learning on Omniglot characters and machine translation of rare words. The implementation uses a TensorFlow memory module that stores key-value pairs to retrieve examples similar to a query. Experiments show the memory module improves one-shot learning performance and handles rare words better than baselines.






![Memory module (query)
Memory query q is a vector of size key-size :
q =R , ∣∣q∣∣ = 1
The nearest neighbor(*) of q in M :
NN(q, M) = arg q ⋅ K[i].
Given a query q, Memory M will compute k‑NN:
(n , ..., n ) = NN (q, M)
Return the main result. the value V [n ]
k
i
max
1 k k
1
(*) Since the keys are normalized, the nearest neighbor w.r.t. cosine similarity. 9](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-9-320.jpg)
![Memory module (query)
Cosine similarity: d = q ⋅ K[n ]
Return softmax (d ⋅ τ, ..., d ⋅ τ)
Inverse of softmax temperature: τ = 40
i i
1 k
10](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-10-320.jpg)
![[Note] Softmax temperature, τ
The idea is to control randomness of predictions
: Softmax outputs are more close to each other
: Softmax outputs are more and more "hardmax"
For a low temperature (τ → 0 ), the probability of the output
with the highest expected reward tends to 1.
+
11](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-11-320.jpg)


![Memory module (train)
loss(q, v, M) = [q ⋅ K[n ] − q ⋅ K[n ] + α]
K[n ]: positive neightbor, V [n ] = v
K[n ]: negative neightbor, V [n ] ≠ v
α: Margin to make loss as zero
b p +
p p
b b
14](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-14-320.jpg)
![Memory module (Update)
Case V [n ] = v:
K[n ] ←
A[n ] ← 0
Case V [n ] ≠ v:
if memory has empty space at n ,
assign n with n
if not, n = max(A[n ])
K[n ] ← q, V [n ] ← v, and A[n ] ← 0.
p
1 ∣∣q+k[n ]∣∣1
q+k[n ]1
1
b
empty
′
empty
′
k
′ ′ ′
15](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-15-320.jpg)



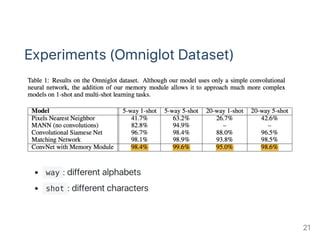
![Experiments (Omniglot Dataset)
Omniglot dataset
This dataset contains 1623 different handwritten characters
from 50 different alphabets.
Each of the 1623 characters was drawn online via Amazon's
Mechanical Turk by 20 different people.
Each image is paired with stroke data, a sequences of [x,y,t]
coordinates with time (t) in milliseconds.
Stroke data is available in MATLAB files only.
Omniglot dataset for one‑shot learning (github): https://github.com/brendenlake/omniglot 19](https://image.slidesharecdn.com/pr12pr-036learningtoremeberrareevents-170917140144/85/PR12-PR-036-Learning-to-Remember-Rare-Events-19-320.jpg)












































![_Deep learning in python Trustworthy [RNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythonrnn-251207084551-1fa069f9-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] image super resolution using deep convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12imagesuper-resolutionusingdeepconvolutionalnetworks-170424004350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[대전AI포럼] 위성영상 분석 기술 개발 현황 소개](https://cdn.slidesharecdn.com/ss_thumbnails/08-170822064935-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OSGeo-KR Tech Workshop] Deep Learning for Single Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/osgeo-krdeeplearningforsingleimagesuper-resolution-180223175347-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PR12] PR-026: Notes for CVPR Machine Learning Sessions](https://cdn.slidesharecdn.com/ss_thumbnails/pr-026notesforcvprmachinelearningsessions-170731034245-thumbnail.jpg?width=640&height=640&fit=bounds)

![[PR12] PR-063: Peephole predicting network performance before training](https://cdn.slidesharecdn.com/ss_thumbnails/peepholepredictingnetworkperformance-180130162632-thumbnail.jpg?width=640&height=640&fit=bounds)





















