Download to read offline










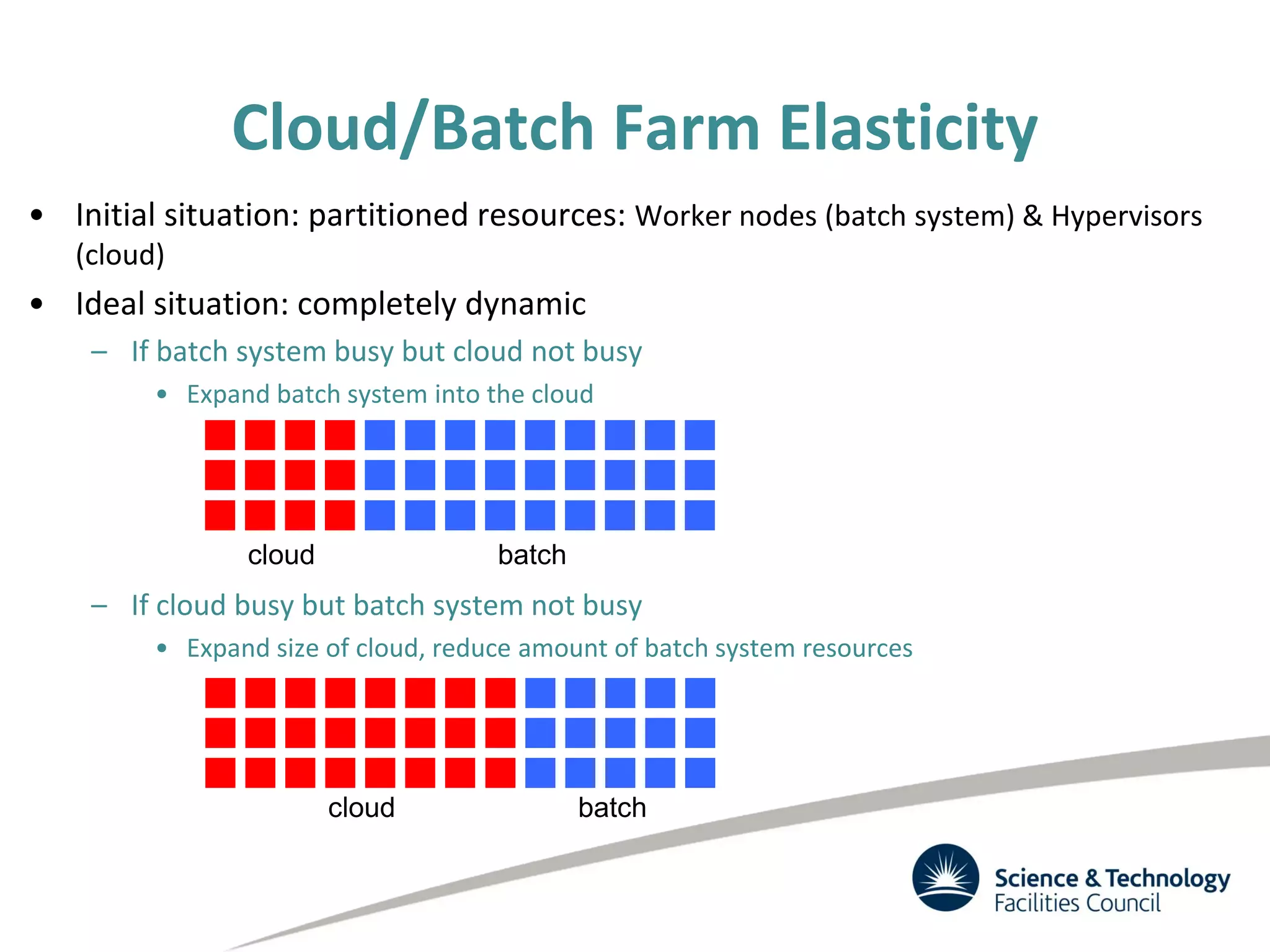



















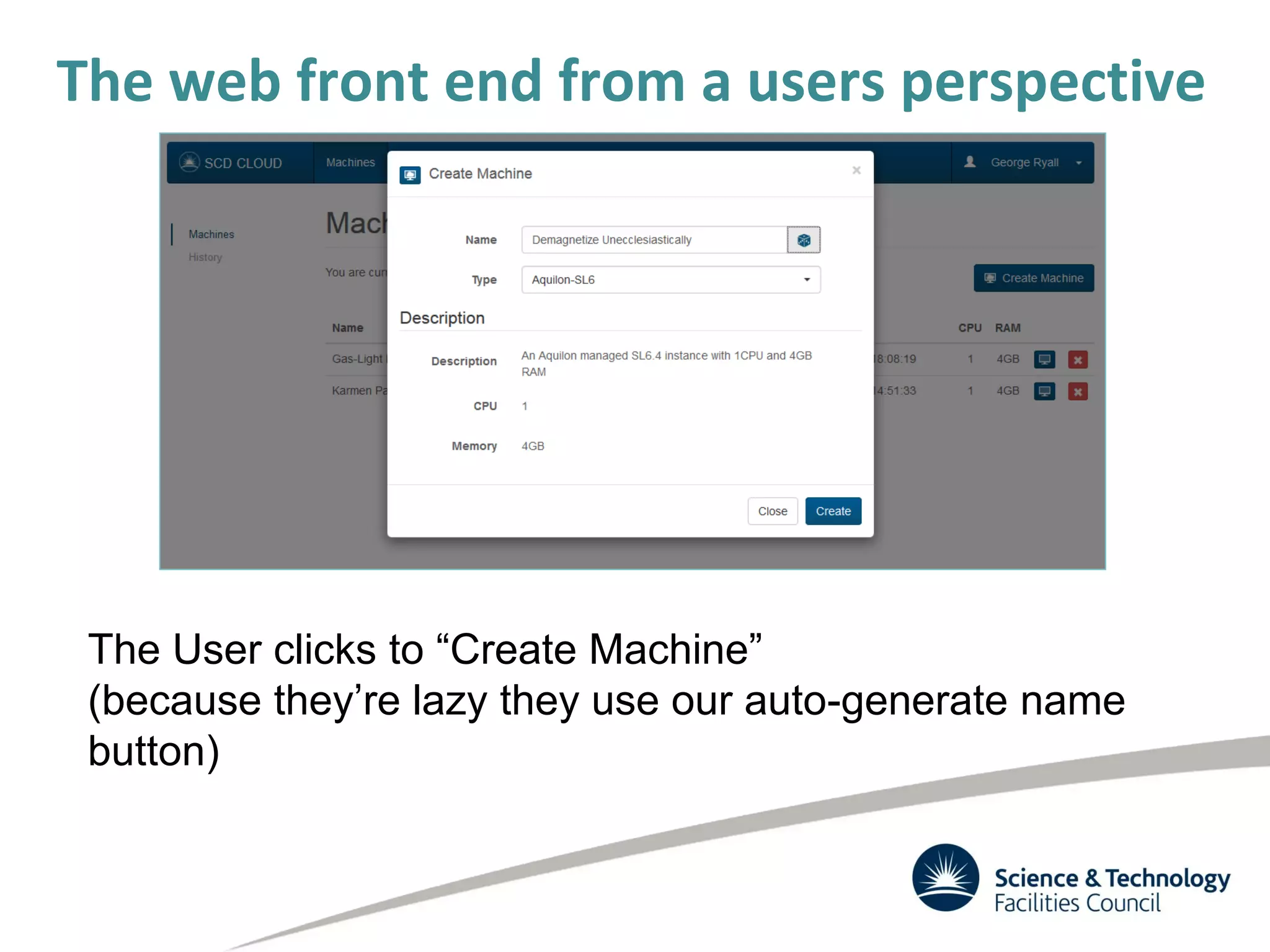





The document discusses the STFC's cloud computing capabilities for scientific research, outlining its background, use cases, and current projects. It highlights the integration of self-service virtual machines and cloud bursting with batch processing systems, along with the need for network isolation and traceability for user activity. The summary also notes the development of a user-friendly web interface and future plans for system upgrades and feature enhancements.



















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















