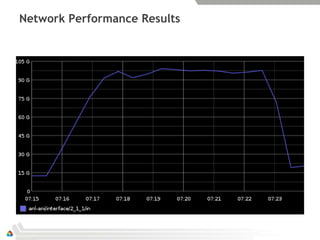
The document summarizes Magellan's experiences with OpenStack as a cloud computing platform for high performance computing workloads. Initial testing found stability and scalability issues with Eucalyptus, but OpenStack performed much better. A production OpenStack deployment was established to support scientific computing projects. Further work optimized networking performance, achieving near-wire speed wide area data transfers of 95 Gbps using OpenStack. The results demonstrate OpenStack's potential for on-demand high performance computing and data-intensive workloads.


































![[OpenStack Day in Korea 2015] Track 2-3 - 오픈스택 클라우드에 최적화된 네트워크 가상화 '누아지(Nuage)'](https://cdn.slidesharecdn.com/ss_thumbnails/23-150213052422-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
































































