Download to read offline





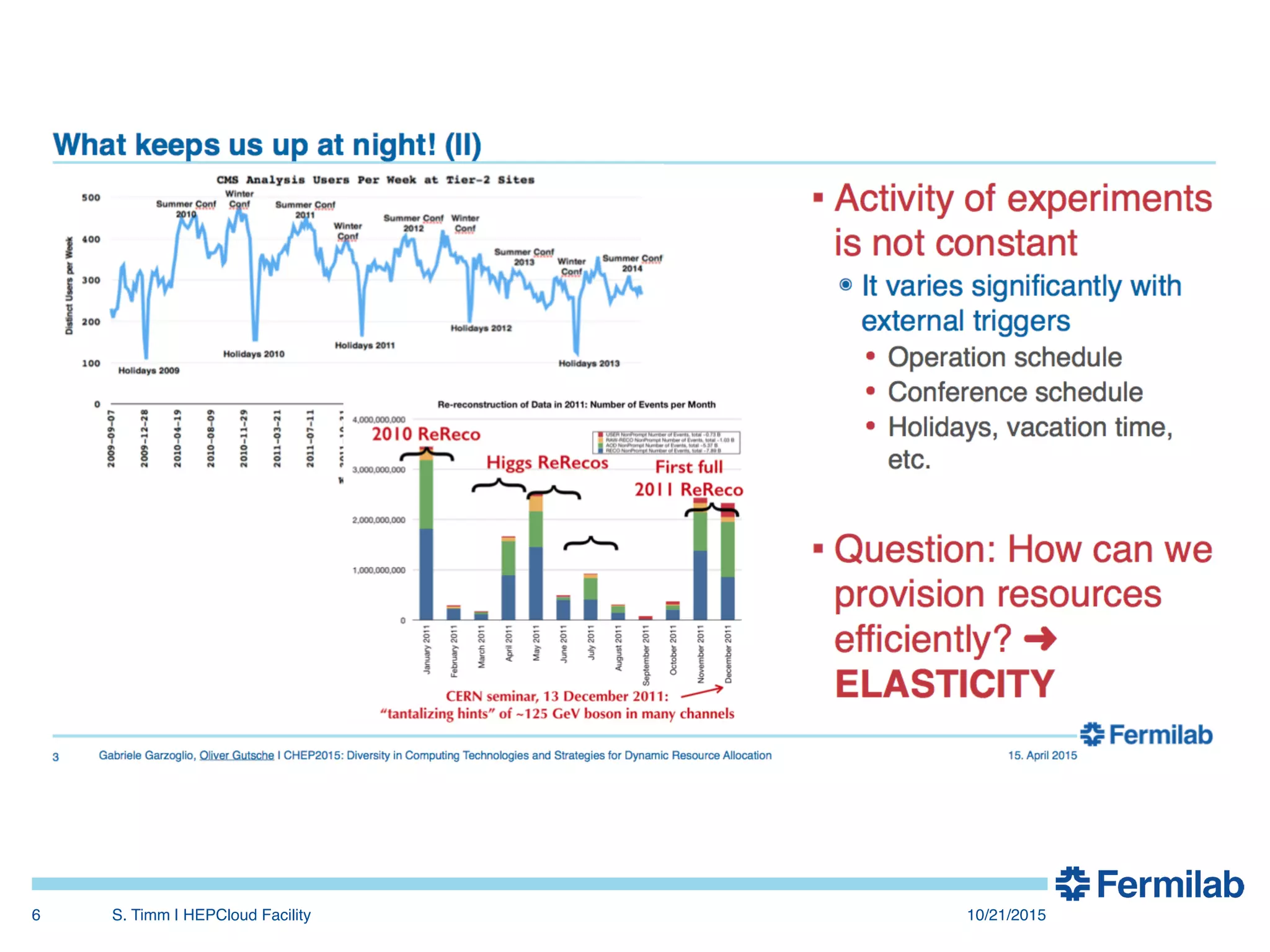



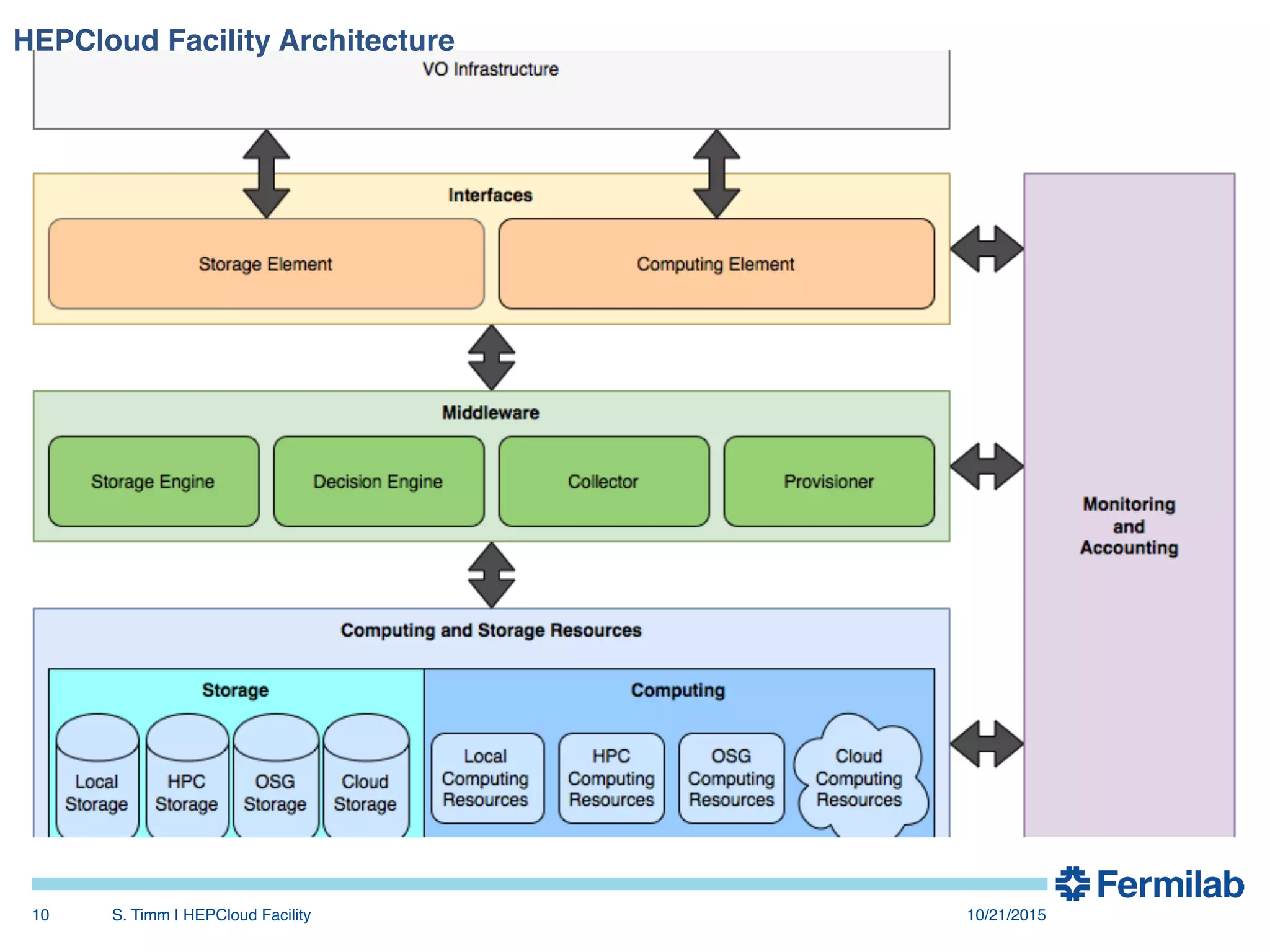



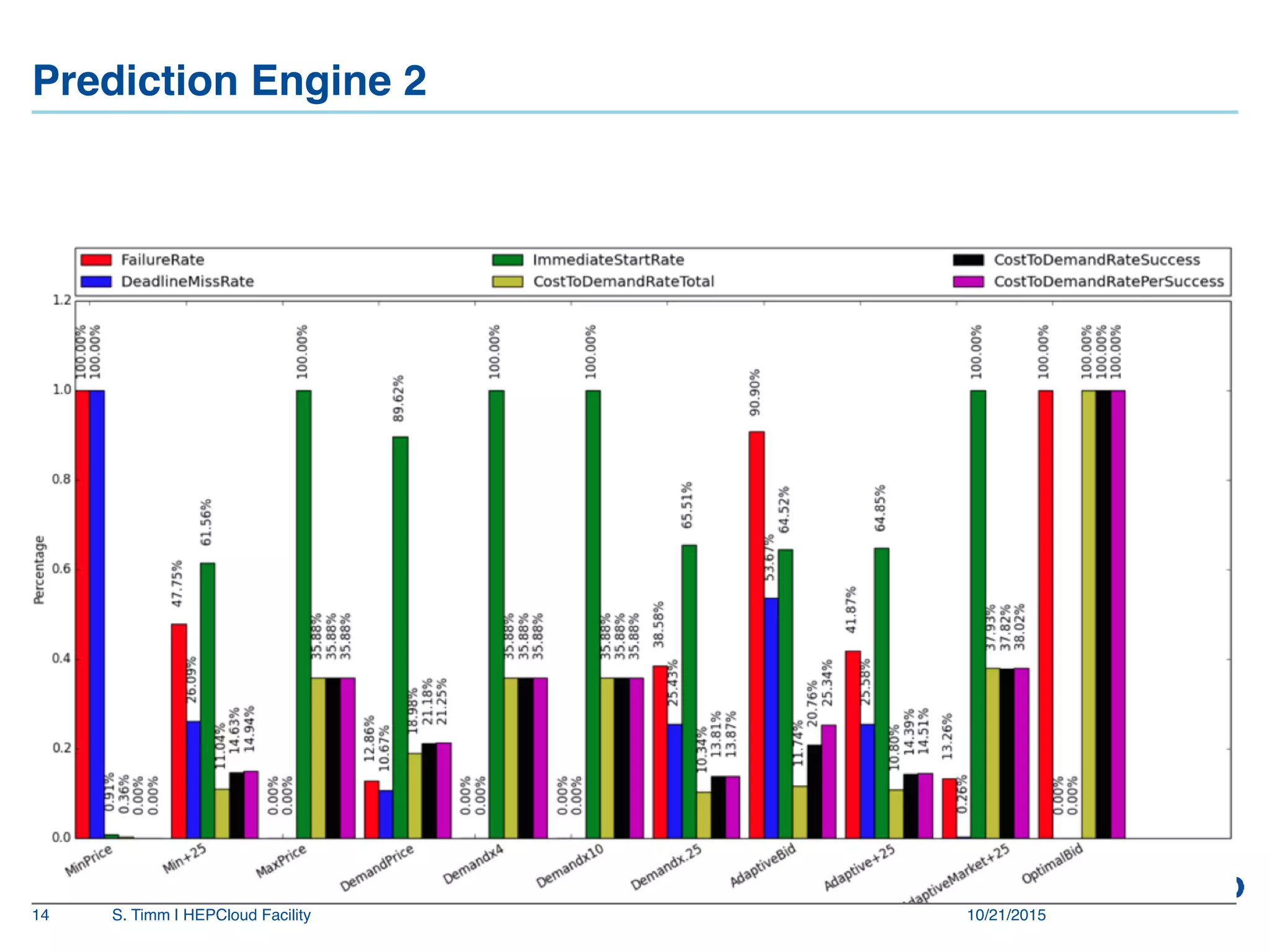
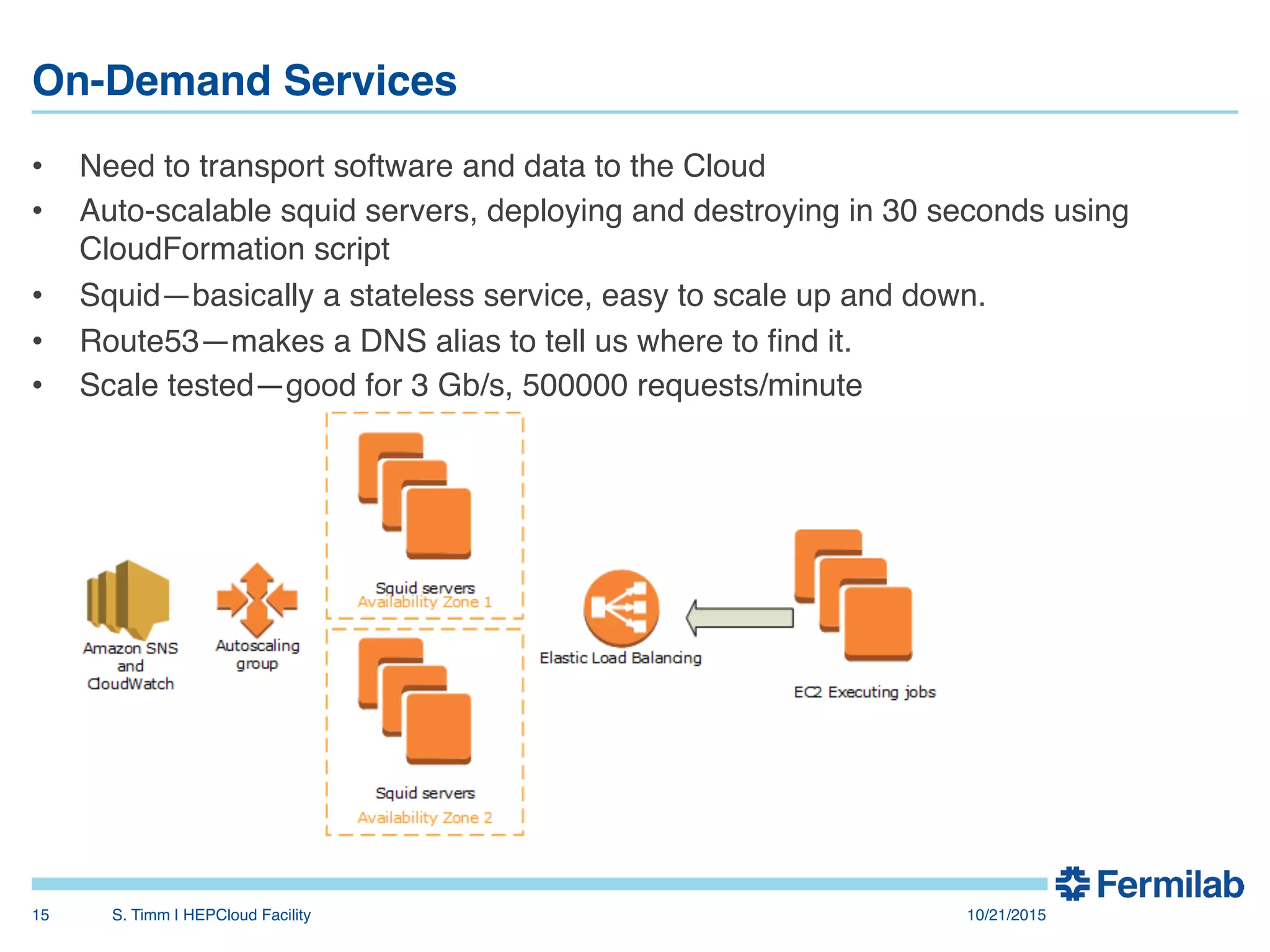





The document discusses the Fermilab HEPCloud project, which aims to expand data-intensive computing capabilities by integrating commercial and community cloud resources with existing infrastructure. It outlines the history, motivation, significant developments, use cases, and future considerations related to the project, emphasizing the need to address peaks in demand without overprovisioning. The document highlights the potential for high energy physics computing needs to harness multiple computing platforms to meet increasing demands efficiently.

















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











