Download to read offline







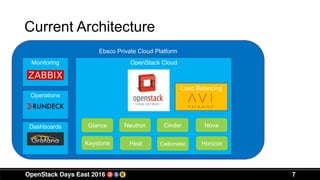










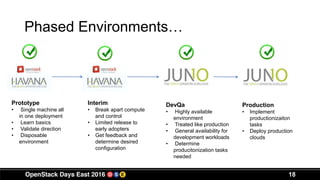
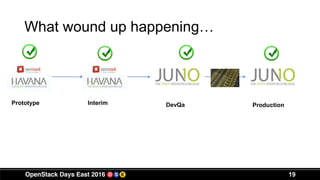






This document discusses Ebsco's implementation and use of OpenStack for their IT infrastructure. Some key points: - Ebsco is a leading provider of online research content and discovery services for libraries. They needed a self-service infrastructure and full-stack automation for their development and operations teams. - They chose OpenStack because it provides standardized compute, network and storage interfaces that allow various products to integrate easily. It also allows them to build an infrastructure as a service platform for their teams. - Currently, Ebsco runs 3 OpenStack clouds supporting over 1,100 instances across development, testing and production environments. They have focused on skills training, vendor integration challenges, deployment difficulties and adoption rates over the course of










































































































