The document discusses online bitrate ladder prediction for adaptive video streaming, focusing on optimizing encoding efficiency using advanced codecs like VVC. It highlights the importance of dynamically adjusting bitrate-resolution pairs based on video complexity to enhance quality and minimize encoding energy consumption. Various encoding methods and their effectiveness in achieving peak signal-to-noise ratio (xPSNR) and target bitrate objectives are analyzed through experimental results.



![Introduction to per-title encoding
3 CONTENT
[1] T. Stockhammer, “Dynamic Adaptive Streaming over HTTP –: Standards and Design Principles,” in Proceedings of the Second Annual ACM Conference on Multimedia Systems,
2011, p. 133–144.
Context- HTTP Adaptive Streaming (HAS)
HAS divides the video content into segments and encodes each segment at various representations, stored
in plain HTTP servers, which continuously adapt the video delivery to the network conditions and device
capabilities of the client [1].
Figure: HAS [1] concept.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-3-320.jpg)
![Introduction to per-title encoding
4 CONTENT
[2] B. Bross, Y. Wang, Y. Ye, S. Liu, J. Chen, G. Sullivan, and J. Ohm. (2021). Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Transactions on
Circuits and Systems for Video Technology. 31. 3736-3764. 10.1109/TCSVT.2021.3101953.
[3] R. Kaafarani et al., “Evaluation Of Bitrate Ladders For Versatile Video Coder,” in 2021 International Conference on Visual Communications and Image Processing (VCIP), 2021,
pp. 1–5.
[4] A. Aaron, Z. Li, M. Manohara, J.D. Cock, D. Ronca, "Per-title encode optimization." The Netflix Techblog (2015).
Motivation for online convex-hull estimation
● The convex hull is where the encoding point achieves
“Pareto efficiency”.
● Online convex-hull estimation methods provide a dynamic
and adaptive means to optimize bitrate and resolution
selections.
● By dynamically adjusting the bitrate-resolution pairs in
response to the video content complexity and coding
algorithms, these methods achieve an optimal trade-off
between computational efficiency and visual fidelity in the
face of the increased intricacies associated with advanced
codecs like VVC [2,3].
Figure: Conceptual plot to depict the bitrate-quality relationship for
any video source encoded at different resolutions. Source: [4]](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-4-320.jpg)
![Introduction to per-title encoding
5 CONTENT
Figure: Rate-distortion (RD) and rate-encoding time curves of representative sequences (segments) of Inter-4K
dataset encoded at 540p, 1080p and 2160p resolutions using VVenC at faster preset. Here, XPSNR is used as
the quality metric.
Quality versus encoding time trade-off
● Dynamic resolution encoding is the most
extensively studied per-title encoding
scheme in adaptive streaming
applications, focusing on adjusting
encoding resolutions dynamically to
optimize video quality [5, 6, 7, 8].
● Encoding time depends on the encoding
resolution chosen for the video content.
The number of pixels in each frame
significantly impacts the computational
workload.
[5] J. Cock, Zhi Li, M. Manohara, and A. Aaron, “Complexity-based consistent-quality encoding in the cloud,” in 2016 IEEE International Conference on Image Processing (ICIP), 2016,
pp. 1484–1488.
[6] A. Katsenou, J. Sole, and D. R. Bull, “Content-gnostic Bitrate Ladder Prediction for Adaptive Video Streaming,” in 2019 Picture Coding Symposium (PCS), 2019, pp. 1–5.
[7] M. Bhat, J. Thiesse, and P. Le Callet, “Combining Video Quality Metrics To Select Perceptually Accurate Resolution In A Wide Quality Range: A Case Study,” in 2021 IEEE
International Conference on Image Processing (ICIP), 2021, pp. 2164–2168.
[8] A. Zabrovskiy, P. Agrawal, C. Timmerer, and R. Prodan, “FAUST: Fast Per-Scene Encoding Using Entropy-Based Scene Detection and Machine Learning,” in 2021 30th Conference
of Open Innovations Association FRUCT, 2021, pp. 292–302.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-5-320.jpg)
![Introduction to per-title encoding
6 CONTENT
● Reducing encoding energy consumption (in data centers)
is critical in streaming applications since it contributes to
environmental sustainability [12].
● The streaming industry can reduce its carbon footprint and
energy consumption by minimizing encoding time.
● Our prior experiments suggest a pseudo linear relationship
between encoding time and encoding energy
consumption.
Reducing encoding time- “greenifies” streaming
Figure: Average encoding metrics for 7.5 fps, 15 fps, 24 fps, and 30 fps HLS CBR
encoding using the veryslow preset of the x264 [9] AVC [10] encoder. Source: [11]
Figure: Average encoding metrics for HLS CBR encoding at 30 fps using selected presets
of x264 [9] AVC [10] encoder. Source: [11]
[9] VideoLAN, “x264.” [Online]. Available: https://www.videolan.org/developers/x264.html
[10] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/AVC video coding standard,” in IEEE Transactions on Circuits and Systems for Video
Technology, vol. 13, no. 7, 2003, pp. 560–576.
[11] Vignesh V. Menon, Samira Afzal, Prajit T. Rajendran, Klaus Schoeffmann, Radu Prodan, and Christian Timmerer. [n. d.]. Content-Adaptive Variable Framerate Encoding
Scheme for Green Live Streaming, [Online]. Available: http://arxiv.org/abs/2311.08074
[12] A. Stephens, C. Tremlett-Williams, L. Fitzpatrick, L. Acerini, M. Anderson, and N. Crabbendam, “The Carbon Impacts of Video Streaming,” Jun. 2021.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-6-320.jpg)

![XPSNR or VMAF in VVC?
8 CONTENT
[13] C. R. Helmrich et al., “Information on and analysis of the VVC encoders in the SDR UHD verification test,” in WG 05 MPEG Joint Video Coding Team(s) with ITU-T SG 16,
document JVET-T0103, Oct. 2020.
[14] M. Wien and V. Baroncini, “Report on VVC compression performance verification testing in the SDR UHD Random Access Category,” in WG 05 MPEG Joint Video Coding
Team(s) with ITU-T SG 16, document JVET-T0097, Oct. 2020.
[15] C. R. Helmrich et al., “A study of the extended perceptually weighted peak signal-to-noise ratio (XPSNR) for video compression with different resolutions and bit depths,” in ITU
Journal: ICT Discoveries, vol. 3, May 2020. [Online] http://handle.itu.int/11.1002/pub/8153d78b-en
● Traditional convex-hull estimation methods use Video
Multimethod Assessment Fusion (VMAF) as the perceptual
quality metric.
● However, as observed in [13], Peak Signal to Noise Ratio
(PSNR) and VMAF measures fail to model the subjective
quality of VVC-coded bitstreams accurately.
● It was observed that Structural Similarity Index (SSIM),
Multi-Scale Structural Similarity Index (MS-SSIM), and
eXtended Peak Signal-to-Noise Ratio (XPSNR) can predict
the subjective codec ranking reported in [14] with
acceptable accuracy [15].
Table: – Evaluation results for Spearman rank order correlation
with MOS values. Source: [15]](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-8-320.jpg)

![Spatiotemporal complexity feature extraction
11 CONTENT
We use seven DCT-energy-based features extracted using Video Complexity Analyzer (VCA) [16]:
● average texture energy (EY),
● average gradient of the luma texture energy (h)
● average luma brightness (LY),
● average chroma texture energy of U and V channels (EU and EV)
● average chroma brightness of U and V channels (LU and LV) [17].
[16] V. V. Menon, C. Feldmann, K. Schoeffmann, M. Ghanbari, and C. Timmerer, “Green Video Complexity Analysis for Efficient Encoding in Adaptive Video Streaming,” in First
International ACM Green Multimedia Systems Workshop (GMSys ’23), 2023.
[17] V. V. Menon, P. T. Rajendran, C. Feldmann, K. Schoeffmann, M. Ghanbari and C. Timmerer, "JND-Aware Two-Pass Per-Title Encoding Scheme for Adaptive Live Streaming," in IEEE
Transactions on Circuits and Systems for Video Technology, vol. 34, no. 2, pp. 1281-1294, Feb. 2024, doi: 10.1109/TCSVT.2023.3290725.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-11-320.jpg)
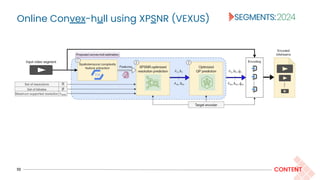
![XPSNR-optimized resolution prediction
12 CONTENT
The objective of selecting the optimized resolution based on bitrate and video complexity features is
decomposed into two parts:
Modeling:
XPSNR of a video scene encoded at resolution r and bitrate b, i.e., x(r,b) is modeled as a function of video
complexity features, b, and normalized resolution height r‘ = r/2160
Resolution optimization:
Select the resolution that maximizes the predicted XPSNR.
We trained XGBoost [18] model hyperparameter tuned to predict XPSNR.
● max_depth=10, and n_estimators=400
[18] T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,
Aug. 2016, pp. 785–794.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-12-320.jpg)
![Optimized QP prediction
13 CONTENT
Modeling:
The optimized QP is modeled as a function of spatiotemporal features, target bitrate b, and normalized
resolution height r‘ as:
● For applications such as streaming, avoiding exceeding the maximum bitrates specified in the
HLS/DASH manifests [19, 20] during the encoding process is essential.
● Failure to adhere to these limits can lead to buffer overflows or underflows in video players.
[19] I. Sodagar, “The MPEG-DASH Standard for Multimedia Streaming Over the Internet,” IEEE MultiMedia, vol. 18, no. 4, pp. 62–67, 2011.
[20] A. Bentaleb, B. Taani, A. C. Begen, C. Timmerer, and R. Zimmermann, “A Survey on Bitrate Adaptation Schemes for Streaming Media Over HTTP,” vol, 21, no. 1, IEEE
Communications Surveys Tutorials, pp. 562–585, 2019.
QP optimization:
The optimization function aims to predict the QP, minimizing the discrepancy between the predicted and
target bitrate for a given resolution.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-13-320.jpg)
![Optimized QP estimation
14 CONTENT
Cascaded approach
● This method involves training distinct XGboost regression models for minimum and maximum QP
values (qmin and qmax, respectively).
● The optimized for a target bitrate b is determined using linear regression, as follows:
● The equation captures the non-linear relationship between bitrate
and QP by employing a logarithmic mapping of the bitrate values.
● VVenC implemented capped VBR ratecontrol in Jan 2024 release
[21], the QP is specified using the qp option, while the maxrate
(easy mode) or MaxBitrate (expert mode) option is used to specify
the upper bound of bitrate variability.
Figure: QP versus normalized bitrate (in log
scale) for a representative video segment.
[21] C. Helmrich, V. George, V. V. Menon, A. Wieckowski, B. Bross, and D. Marpe, “Fast constant-quality video encoding using VVenC with rate capping based on pre-analysis
statistics”, 2024.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-14-320.jpg)

![Experimental design
16 CONTENT
Dataset generation
Figure: Calculation of the groundtruth PSNR, XPSNR, and bitrate to train the prediction
models. This example shows the ground truth calculation of a video encoded at 1080p with qp
30.
● We used 1000 videos of the Inter-4K dataset [22] to
validate the performance of the encoding methods.
● We encoded the sequences at UHD (2160p) 60fps
using VVenC v1.10 [23] using preset 0 (faster).
● We extracted the spatiotemporal features using
VCA v2.0.
● We ran constant quality encoding by varying qp
values from qmin to qmax for each resolution.
● We computed full-reference PSNR and XPSNR
quality metrics after the compressed video was
upscaled to the original resolution (2160p).
[22] A. Stergiou and R. Poppe, “AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling,” in IEEE Transactions on Image Processing, vol. 32, 2023, pp.
251–266.
[23] A. Więckowski, J. Brandenburg, T. Hinz, C. Bartnik, V. George, G. Hege, C. Helmrich, A. Henkel, C. Lehmann, C. Stoffers, I. Zupancic, B. Bross, and D. Marpe, “VVenC: An
Open And Optimized VVC Encoder Implementation,” in Proc. IEEE International Conference on Multimedia Expo Workshops (ICMEW), pp. 1–2.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-16-320.jpg)
![Experimental design
17 CONTENT
1. Default: This method employs a fixed resolution encoding, i.e., all
bitstreams are encoded at the exact resolution as the input video.
2. FixedLadder: This method employs a fixed set of bitrate-resolution
pairs. We use the HLS bitrate ladder specified in the Apple authoring
specifications [24] as the fixed set of bitrate-resolution pairs.
3. Bruteforce: This method determines optimized resolution, which
yields the highest XPSNR for a given target bitrate after an
exhaustive encoding process at all supported resolutions and QPs.
Benchmarks Table: An example fixed bitrate-ladder, i.e., set of
bitrate-resolution pairs. Source: [24].
[24] Apple Inc., “HLS Authoring Specification for Apple Devices.” [Online]. Available:
https://developer.apple.com/documentation/http-live-streaming/hls-authoring-specification-for-apple-devices
Table: Experimental parameters used for evaluation.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-17-320.jpg)

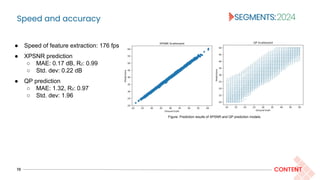
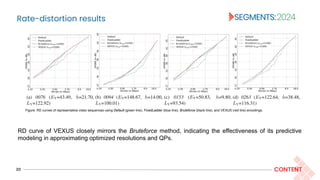
![Result summary
22 CONTENT
● Coding efficiency (in terms of Bjøntegaard Delta [25] rates), encoding and decoding times decrease
as rmax decreases.
● The trade-off between quality and coding efficiency is based on the target audience, delivery platform,
and available resources.
[25] HSTP-VID-WPOM, “Working practices using objective metrics for evaluation of video coding efficiency experiments,” International Telecommunication Union, 2020. [Online].
Available: http://handle.itu.int/11.1002/pub/8160e8da-en
Table: Average results of the encoding schemes compared to Default encoding.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-22-320.jpg)

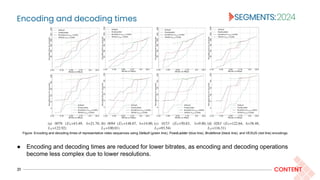
![Encoding time constrained convex-hull estimation
24 CONTENT
Resolution optimization:
● Select the resolution that maximizes the predicted XPSNR, constrained on the maximum encoding time [26].
● Encoding time is predicted using the same approach as the QP prediction.
● Encoding time constraint is effectively a constraint on the encoding energy.
[26] V. V. Menon, A. Premkumar, P. T. Rajendran, A. Więckowski, B. Bross, C. Timmerer, and D. Marpe, "Energy-efficient Adaptive Video Streaming with Latency-Aware Dynamic
Resolution Encoding." 2024 Mile High Video (MHV), doi: 10.1145/3638036.3640801.](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-24-320.jpg)
![Encoding time constrained convex-hull estimation
25 CONTENT
Figure: RD curves, and encoding times of representative video sequences (segments) using VEXUS (𝑟max = 2160).
Source: [27]
Results
RD performance decreases as the encoding time constraint is lowered.
Figure: Selected encoding resolutions of representative
video sequences (segments) using VEXUS (𝑟max = 2160).
Source: [27]
[27] A. Premkumar, P. T. Rajendran, V. V. Menon, A. Więckowski, B. Bross, and D. Marpe, "Quality-Aware Dynamic Resolution Adaptation Framework for Adaptive Video
Streaming,” 2024 [Online]. Available: https://github.com/PhoenixVideo/QADRA](https://image.slidesharecdn.com/vigneshsegments2024-240328164854-45863583/85/Online-Bitrate-ladder-prediction-for-Adaptive-VVC-Streaming-25-320.jpg)































![[IJET-V1I2P1] Authors :Imran Ullah Khan ,Mohd. Javed Khan ,S.Hasan Saeed ,Nup...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i2p1-150413013648-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




































