Download as PDF, PPTX


![関連研究(Image Segmentation)
n Semantic Segmentation
• CNNを用いた画像分類問題として長い間取り組まれる
• MaskFormer [Cheng+, NeurIPS2021]
• Object Queries [Carion+, ECCV2020]を持つ変換デコーダを使用
• Semantic Segmentationをマスク分類問題と扱う
n Instance Segmentation
• Cascade R-CNN [Cai &Vasconcelos, CVPR2018], Hybrid Task Cascade [Chen+, CVPR2019],
Panoptic-DeepLab [Cheng+, CVPR2020]
• マスク分類器として定式化
n Panoptic Segmentation [Kirillov+, CVPR2019]
• 初期アーキテクチャ:Panoptic-FPN [Kirillov+, CVPR2019]
• Transformer-based
• Mask2Former [Cheng+, CVPR2022], MaskFormer [Cheng+, NeurIPS2021],
Max-DeepLab [Wang+, CVPR2021], Axial-DeepLab [Wang+, ECCV2020],
Cmt-DeepLab [Yu+, CVPR2022], k-means Mask TransFormer [Yu+, ECCV2022]](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-3-2048.jpg)
![関連研究(Universal Segmentation, Transformer-based Architecture)
nUniversal Image Segmentation
• 画像とシーンの構文解析
Object Instance and Occlusion Ordering [Tighe+, CVPR2014],
Image Parsing [Tu+, IJCV2005], Describing the scene as a whole [Yao+, CVPR2012]
• Panoptic Segmentation [Kirillov+, CVPR2019]
• Panoptic Segmentation専用に設計されたアーキテクチャ
• Mask2Former [Cheng+, CVPR2022], MaskFormer [Cheng+, NeurIPS2021]
nTransformer-based Architecture
• 変換Encoder・Decoder構造に基づくアーキテクチャ
• DETR [Carion+, ECCV2020]
• Mask2Former [Cheng+, CVPR2022] :マスク分類を定式化
• Image Segmentationに有効であることを実証](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-4-2048.jpg)
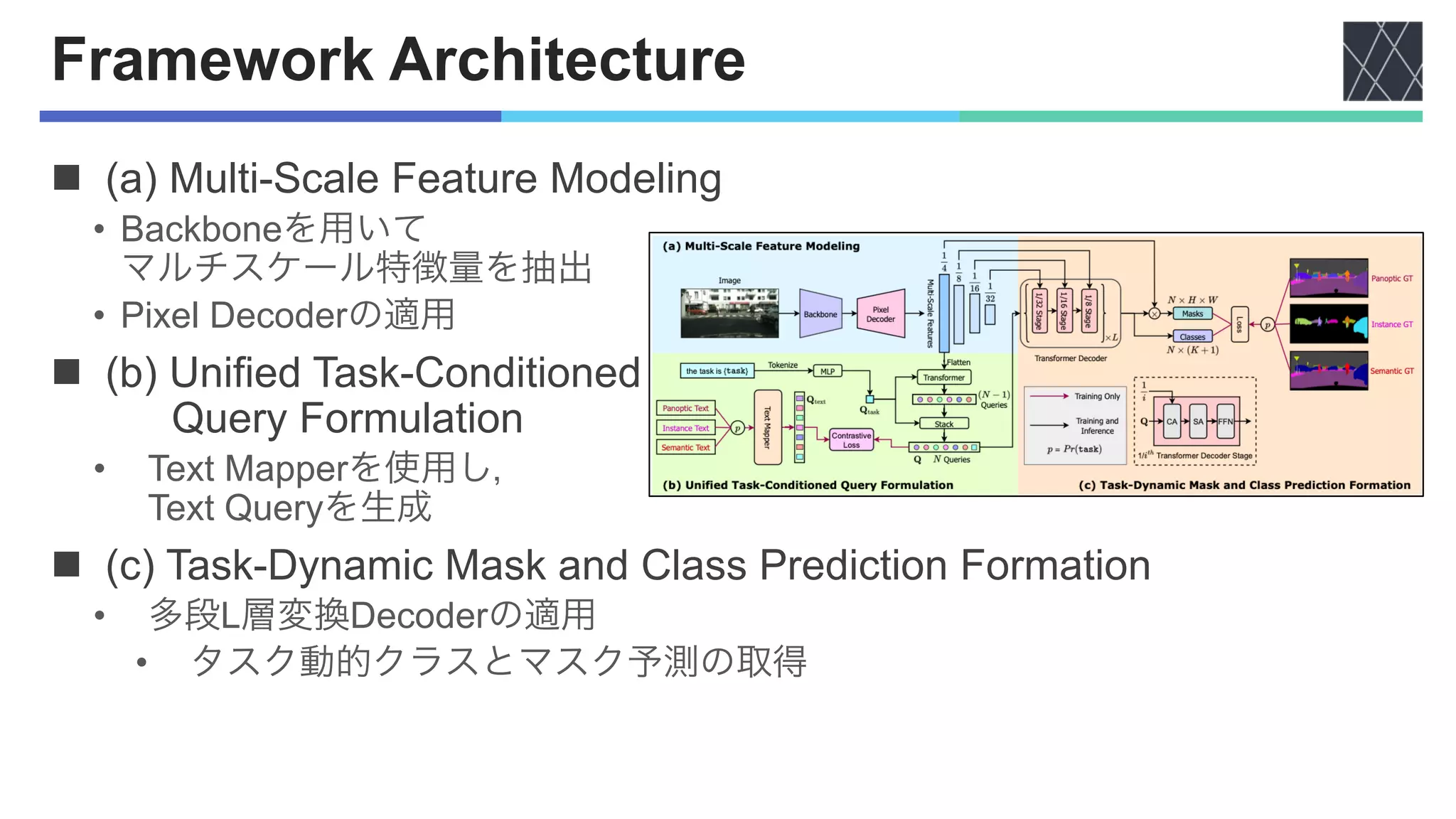

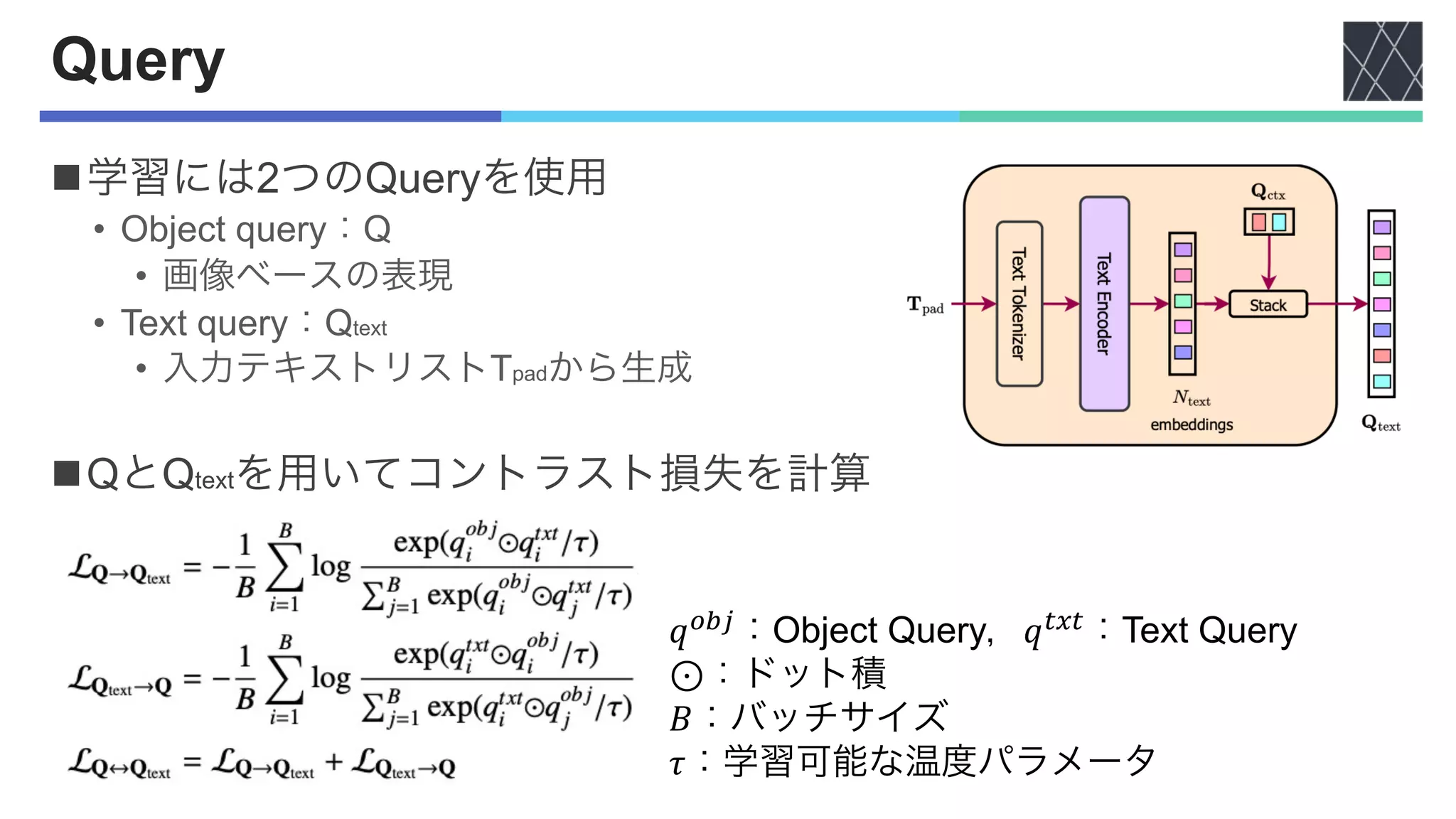
![Other Architecture Components, Losses
nBackbone and Pixel Decoder
• 入力画像からマルチスケール特徴量を抽出
• ImageNet Classification [Krizhevsky+, NeurIPS2012]の
事前学習済みBackBoneを使用
nTransformer Decoder
• マルチスケール戦略[Cheng+, CVPR2022]を使用
• 最終的な予測とマスク取得
nLosses
• ℒ!"#:CE-loss
• ℒ$!%:binary cross-entropy,ℒ&'!%:dice-lossの組み合わせ
• ℒ(')*":コントラスト損失と上記3つの損失の重み(𝜆)つき合計](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-8-2048.jpg)
![実験設定
nDatasets
• Cityscapes [Marius+, CVPR2016]
• Train:2,975枚,Val:500枚,Test:1,525枚
• 19クラス(11の”stuff”,8の”thing”)
• ADE20K [Zhou+, CVPR2017]
• Train:20,210枚,Val:2,000枚
• 150クラス(50の”stuff”,100の”thing”)
• COCO [Lin+, ECCV2014]
• Train:118,000枚,Val:5,000枚
nEvaluation Metrics
• Semantic, Instance:AP [Lin+, ECCV2014], mIoU [Everingham+, IJCV2015]
• Panoptic:PQ [Kirillov+, CVPR2019]](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-9-2048.jpg)
![実験結果(ADE20K)
n3つのタスクにおいてMask2Formerの性能を上回る
• OneFormer:1回の合同学習
• Mask2Former [Cheng+, CVPR2022]:個別学習モデル
• Backbone:Swin-L [Liu+, ICCV2021]](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-10-2048.jpg)
![実験結果(Cityscapes)
nBackbone:Swin-L [Liu+, ICCV2021]
• PQ:+0.6%,AP:+1.9%の向上
nBackbone :ConvNeXt-L,ConvNeXt-XL [Liu+, CVPR2022]
• OneFormerはPQ:68.5%,AP:46.7%の性能を発揮](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-11-2048.jpg)
![実験結果(Cityscapes)
nBackbone:Swin-L [Liu+, ICCV2021]
• PQ:+0.6%,AP:+1.9%の向上
nBackbone :ConvNeXt-L,ConvNeXt-XL [Liu+, CVPR2022]
• OneFormerはPQ:68.5%,AP:46.7%の性能を発揮](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-12-2048.jpg)
![実験結果(COCO)
nBackbone:Swin-L
• 個別に学習したMask2Former [Cheng+, CVPR2022]と同等の性能
• PQ:+0.1%向上
• AP
• panoptic annotationから得られたGTを使用し評価
• panoptic annotationとinstance annotationに不一致があるため
• AP :instance annotationに対する評価
instance](https://image.slidesharecdn.com/20230927oneformeronetransformertoruleuniversalimagesegmentationcvpr2023-231002080302-e25004b6/75/OneFormer-One-Transformer-To-Rule-Universal-Image-Segmentation-13-2048.jpg)


Jitesh Jain, Jiachen Li, Mang Tik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi, "OneFormer: One Transformer To Rule Universal Image Segmentation" CVPR2023 https://openaccess.thecvf.com/content/CVPR2023/html/Jain_OneFormer_One_Transformer_To_Rule_Universal_Image_Segmentation_CVPR_2023_paper.html



![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]EfficientDet: Scalable and Efficient Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/191122dlseminar-191122013544-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=640&height=640&fit=bounds)













































