Download to read offline
![AutoPrompt: Eliciting Knowledge from Language Models with
Automatically Generated Prompts
[Shin+, ACL Anthlogy2020]
Toward Human Readable Prompt Tuning: Kubrick’s The
Shining is a good movie, and a good prompt too?
[Shi+, ACL Anthlogy2023]
Hard Prompts Made Easy: Gradient-Based Discrete
Optimization for Prompt Tuning and Discovery
[Wen+, NeurIPS2023]
水野翼(名工大玉木研)
2025/6/12](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-1-320.jpg)
![AutoPrompt: Eliciting Knowledge from Language Models with
Automatically Generated Prompts
[Shin+, ACL Anthlogy2020]
Toward Human Readable Prompt Tuning: Kubrick’s The
Shining is a good movie, and a good prompt too?
[Shi+, ACL Anthlogy2023]
Hard Prompts Made Easy: Gradient-Based Discrete
Optimization for Prompt Tuning and Discovery
[Wen+, NeurIPS2023]
水野翼(名工大玉木研)
2025/6/12](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/75/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-1-2048.jpg)
![3つの論文の簡単な概要
◼AutoPrompt [Shin+, ACL Anthlogy2020]
• 勾配誘導探索に基づきタスク特化プロンプトを生成
• あらゆるプロンプトを自動生成,人手による試行錯誤を排除
◼Toward Human Readable Prompt Tuning [Shi+, ACL Anthlogy2023]
• 自然で解釈可能なプロンプトの生成手法
• 性能と可読性の両立を実現
◼Hard Prompt Made Easy [Wen+, NeurIPS2023]
• 効率的な勾配法を活用しハードプロンプトを最適化・学習する手法
• ソフトプロンプトの性能をハードプロンプトで達成
• 画像生成,テキスト分類タスクで高い転移性能](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-2-320.jpg)

![概要
◼プロンプト学習とは
• タスクを自然言語に変換して言語モデルに入力する手法
• 例)分類タスク→「これはポジティブですか?」などの文章に変換
• 課題
• 適切なプロンプトの生成には人手と試行錯誤が必要
• 経験や直感に頼った設計‥一貫性や汎用性に欠ける
◼AutoPrompt
• 勾配誘導探索により,人手なしでプロンプトを自動生成
• モデルが「効果的な単語列」を自ら見つける
• 特徴
• 離散的なハードプロンプトの自動生成
• 文分類・関係抽出など多様なタスクに対応 勾配誘導探索[Eric+, ACL Anthrogy2019]](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-4-320.jpg)
![手法
◼記法と基本構造
• 入力文:𝑥inp,プロンプト文: 𝑥prompt
• 𝜆:𝑥𝑖𝑛𝑝や追加のトークン・特殊トークン[MASK]の配置を決定
• マスク付き言語モデル(MLM)により[MASK]に
最も適切な単語の確率分布𝑝([𝑀𝐴𝑆𝐾]|𝑥𝑝𝑟𝑜𝑚𝑝𝑡)を推定](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-5-320.jpg)
![手法
◼最適化ステップ
1. 初期化:全トリガートークンを[MASK]に設定
2. 勾配計算:各語彙𝑤 ∈ 𝒱での尤度変化を予測
3. 候補選出:上位𝑘個の有望候補を選択
4. 実評価:各候補で実際に順伝播して性能測定
5. 更新:最良の候補でトークンを更新
勾配誘導探索[Eric+, ACL Anthrogy2019]](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-6-320.jpg)
![実験概要
◼対象モデル
• BERT [Devlin+, NAACL2019]:110Mのパラメータ
• RoBERTa [Liu+, arXiv2019]:355Mのパラメータ
◼対象タスク:感情分析,自然言語推論,事実探索,関係抽出](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-7-320.jpg)
![感情分析(Sentiment Analysis)
◼設定
• データセット:SST-2 [Socher+, ACL Anthlogy2013]
• タスク:二値感情分類(positive/negative)
• 比較対象:手動プロンプト,再学習されたモデル
◼性能評価
• BERT+AutoPrompt:教師ありBiSTMと同等性能
• RoBERTa + AutoPrompt:再学習されたBERTと同等精度
◼少数データでの性能優位性
• BERT:AutoPrompt≒再学習
• RoBERT:100~1,000サンプルでAutoPrompt > 再学習](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-8-320.jpg)
![感情分析(Sentiment Analysis)
◼設定
• データセット:SST-2 [Socher+, ACL Anthlogy2013]
• タスク:二値感情分類(positive/negative)
• 比較対象:手動プロンプト,再学習されたモデル
◼性能評価
• BERT+AutoPrompt:教師ありBiSTMと同等性能
• RoBERTa + AutoPrompt:再学習されたBERTと同等精度
◼少数データでの性能優位性
• BERT:AutoPrompt≒再学習
• RoBERT:100~1,000サンプルでAutoPrompt > 再学習](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-9-320.jpg)
![感情分析(Sentiment Analysis)
◼設定
• データセット:SST-2 [Socher+, ACL Anthlogy2013]
• タスク:二値感情分類(positive/negative)
• 比較対象:手動プロンプト,再学習されたモデル
◼性能評価
• BERT+AutoPrompt:教師ありBiSTMと同等性能
• RoBERTa + AutoPrompt:再学習されたBERTと同等精度
◼少数データでの性能優位性
• BERT:AutoPrompt >= 再学習
• RoBERT:AutoPrompt > 再学習](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-10-320.jpg)
![自然言語推論(NLI)
◼実験設定
• データセット:SICK-E [Marelli+, ACL Anthlogy2014]
• ラベル: contradiction, entailment, neutral
• 特性
• standard: neutral偏重
• 2-way: contradiction vs. entailment
• 3-way: バランス調整版
◼結果
• AutoPrompt:Majority baselineを大幅に上回る
• 2-wayタスク:再学習されたBERTに匹敵](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-11-320.jpg)
![事実探索
◼評価指標
• MRR :正解の順位の逆数の割合
• P@1:1位が正解である割合
• P@10:10位以内が正解がある割合
◼実験設定
• データセット:LAMA [Petroni+, ACL Anthlogy2019]
• 比較手法:LAMA手動プロンプト,LPAQA [Jiang+, ACL Anthlogy2021]
◼結果
• AutoPromptはLAMAよりP@1を最大+12%性能向上
• 1つのプロンプトでLPAQAの30プロンプトの平均を上回る](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-12-320.jpg)
![関係抽出
◼実験設定
• データセット:T-Rex [Elsahar+, ACL Anthlogy2018]
• 比較手法:教師ありRELSTM, LAMA, LPAQA
◼結果
• AutoPromptは教師ありモデルを最大33%上回る
• BERTがRoBERTより優秀](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-13-320.jpg)




![実験設定
◼比較手法
• AutoPrompt:
貪欲なトークン選択・Verbalizer考
慮
• AutoPromptSGD:
勾配降下のみ,Langevinなし
◼ターゲットタスク
• 感情分析[McAuley&Leskovec, 2013], [Socher+, 2013]
• トピック分類[Zhang+, 2015]
◼モデル
• GPT-2 Large(774Mパラメータ)
[Radford+, 2019]
• 最適化手法:AdamW[LoshChilov&Hutter, 2018]
◼アブレーション
• ノイズなし,流動性制約なし](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-18-320.jpg)






![手法
◼入力と設定
• 固定モデル:𝜃
• 最適化対象:埋め込み列𝑷 = [𝑒1, … , 𝑒𝑀] (𝑀個,𝑑次元)
• 目的関数: 𝐿 (タスク損失)
◼最適化の流れ
• 初期化:連続埋め込み𝑷を利用(ソフトプロンプト)
• 投影: 𝑷を最も近い語彙埋め込みにマッピング
→ハードプロンプト𝑷′
• 評価: 𝑷′
を用いてタスク損失R(𝑷′
)を計算
• 勾配更新: 𝑃に対して勾配を計算・更新
(𝑷′
は固定)
• 繰り返し:性能が収束するまで繰り返す](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-25-320.jpg)

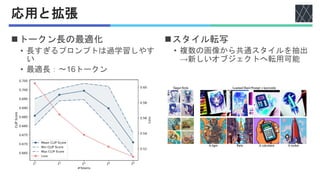
![定量 / 定性的評価
◼評価データセット
• LAION, MS COCO, Celeb-A, Lexica.art
◼評価方法
• 学習プロンプトで生成された画像と
元画像のCLIP類似度をOpenCLIP-ViT/Gで測定
• 比較手法:CLIP Interrogator [Radford+, arXiv2021], BLIP [Li+, arXiv2022]
◼結果
• 全てのデータセットで安定した高性能
• 8トークンの短いプロンプトで競争力のスコア
• 内容の反映:プロンプトに主要要素(例:milkyway)
を明示的に含む
• 短く高密度なプロンプト(絵文字なども含む)](https://image.slidesharecdn.com/20250612autoprompthumanreadablepromptpez-250624004720-897628ea/85/AutoPrompt-Eliciting-Knowledge-from-Language-Models-with-Automatically-Generated-Prompts-Toward-Human-Readable-Prompt-Tuning-Kubrick-s-The-Shining-is-a-good-movie-and-a-good-prompt-too-27-320.jpg)






Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, Sameer Singh, "AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts", EMNLP2020 https://aclanthology.org/2020.emnlp-main.346/ Weijia Shi, Xiaochuang Han, Hila Gonen, Ari Holtzman, Yulia Tsvetkov, Luke Zettlemoyer, "Toward Human Readable Prompt Tuning: Kubrick’s The Shining is a good movie, and a good prompt too?", EMNLP2023 https://aclanthology.org/2023.findings-emnlp.733/ Yuxin Wen, Neel Jain, John Kirchenbauer, Micah Goldblum, Jonas Geiping, Tom Goldstein, "Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery", NeurIPS 2023 https://proceedings.neurips.cc/paper_files/paper/2023/hash/a00548031e4647b13042c97c922fadf1-Abstract-Conference.html


![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackstakgfinal-190820070754-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会] Towards an Automatic Turing Test: Learning to Evaluate Dialogue Respo...](https://cdn.slidesharecdn.com/ss_thumbnails/170925dlhackstowardsanautomaticturingtest-170925104902-thumbnail.jpg?width=640&height=640&fit=bounds)



























