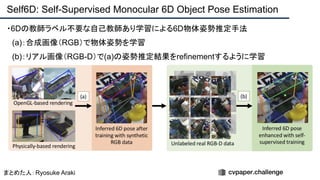
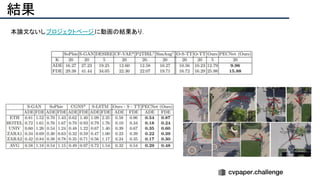
Downloaded 50 times
















![+αの情報
・著者コード(PyTorch):[リンク]
・ECCV Oral Youtube:[リンク]
・ECCV2020には3本の論文を通している研究室
・CVPR/IROS等への実績も多い
・Blind PnP問題の研究として,今後も引用されていくと思われる.](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-25-320.jpg)



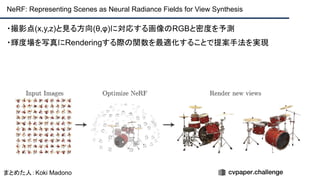

![+αの情報
・著者コード(PyTorch):[https://github.com/bmild/nerf]
・データセット:[https://drive.google.com/drive/folders/128yBriW1IG_3NJ5Rp7APSTZsJqdJdfc1]
・project page:[http://tancik.com/nerf]
・Video : [https://youtu.be/JuH79E8rdKc]](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-41-320.jpg)

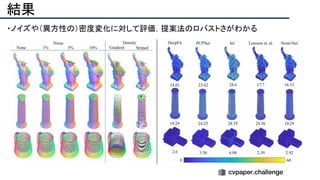
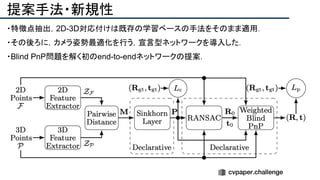
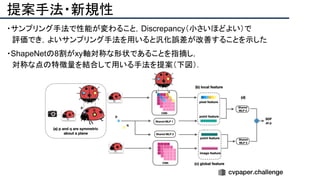
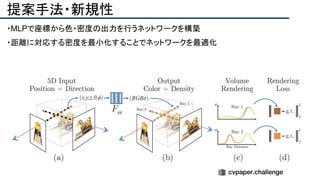
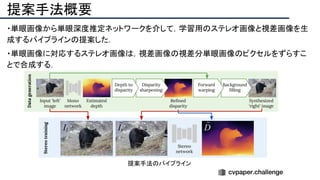
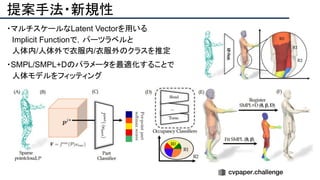
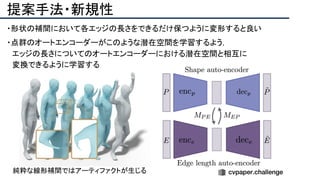
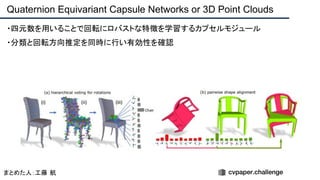
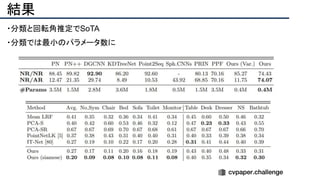
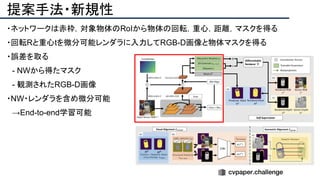
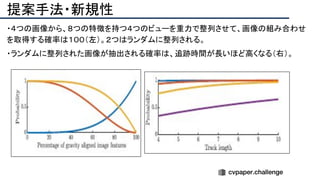
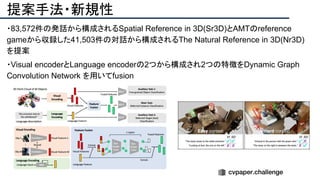
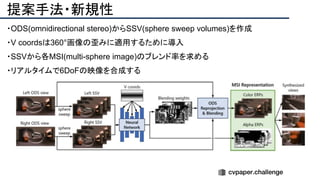
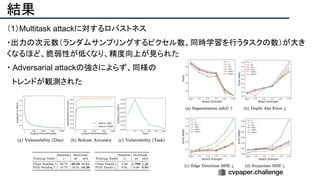
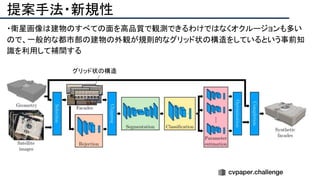
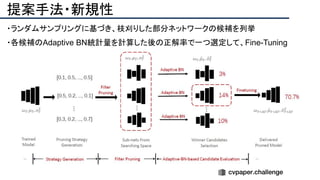
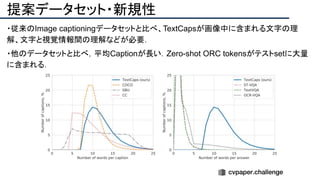
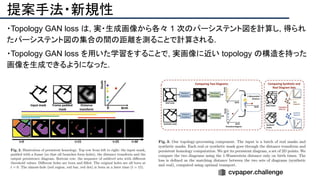
![提案手法・新規性
・PnPを[1,2]と同様のコスト関数を持つ非線形2次プログラムとしてキャストする.
・従来の問題を日多項式ソルバーの開発・独自の数学的フレームワークの確立により解
決.
・NOMPからの最小値の地域検索
・FOAMアルゴリズムを用いた高度な行列因数分解を解かず,多項式の直行金jい問題とし
て解いている.](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-43-320.jpg)


![+αの情報
・ SQPnP is available at https://github.com/terzakig/sqpnp.
・.[1] Lu, C.P., Hager, G.D., Mjolsness, E.: Fast and globally convergent pose
estimation from video images. IEEE Transactions on Pattern Analysis and Machine
Intelligence 22(6), 610–622 (2000)
・[2]Schweighofer, G., Pinz, A.: Globally optimal O(n) solution to the PnP problem for
general camera models. In: British Machine Vision Conference. pp. 1–10 (2008)](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-46-320.jpg)

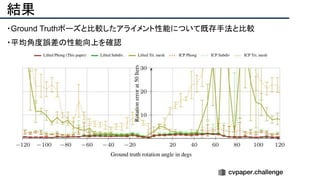



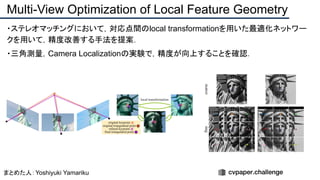
![提案手法のポイント
・ 単眼深度推定で得られる深度画像は境界が曖昧[*1]
なので,Sobel filterを適用し,深度画
像をRefineする.これによりステレオ視差推定の性能が向上する.
・合成できない領域は他の単眼画像で穴埋めする.
[*1]単眼深度推定の学習Lossに平滑化項が含まれるためだと考えられる(まとめた人の私見).
Depth refineによる,ステレオ視差推定の性能向上 合成できない領域への穴埋め例](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-55-320.jpg)











![+αの情報
・Yida Wang [https://www.researchgate.net/profile/Yida_Wang]
David Joseph Tan[http://campar.in.tum.de/Main/DavidTan]
Nassir Navab[https://scholar.google.de/citations?user=kzoVUPYAAAAJ&hl=ja]
Federico Tombari[https://scholar.google.com/citations?user=TFsE4BIAAAAJ&hl=ja]
Technische Universitat Munchen, Google Inc
・project page:[https://www.merl.com/research/license#KCNet]
・この研究室は毎年のように CVPRに論文を通している
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling CVPR'18.
https://arxiv.org/abs/1712.06760
Adversarial Semantic Scene Completion from a Single Depth Image
2018 International Conference on 3D Vision (3DV)](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-81-320.jpg)


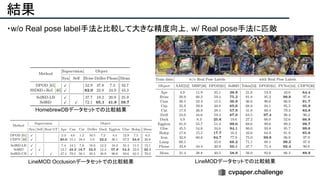

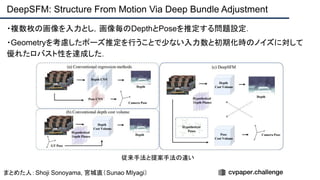
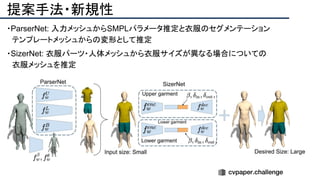
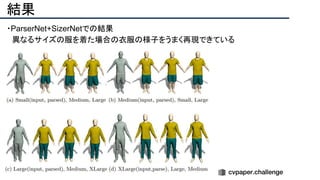
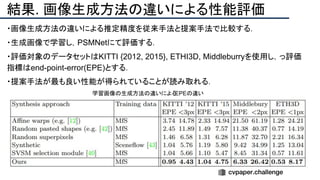
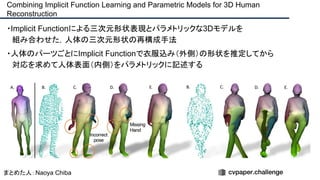
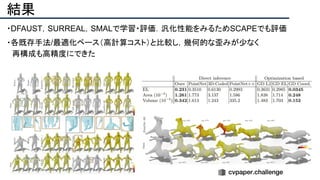
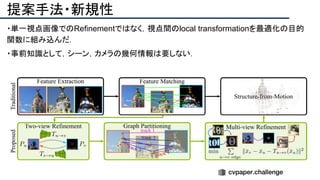
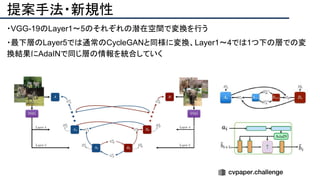
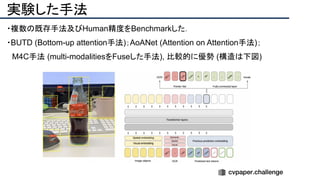
![提案手法・新規性
・SfMで考慮されていたGeometry情報を追加したDeepSFMを提案.
・[Depth/Pose] cost volumeそれぞれにGeometryな制約を追加し,DepthとPoseの整合
性を一致させることで性能を向上させた.
提案手法のネットワーク図](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-93-320.jpg)


![+αの情報
・著者コード(PyTorch):[https://github.com/weixk2015/DeepSFM]
・データセット:[https://github.com/weixk2015/DeepSFM/tree/master/dataset]
・project page:【https://weixk2015.github.io/DeepSFM/】
・この研究室は毎年のようにCVPRに論文を通している
【https://ist.fudan.edu.cn/】
・この論文は今後も引用されそう?
動画
・https://www.youtube.com/watch?v=3SVC1uj1ePY](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-96-320.jpg)
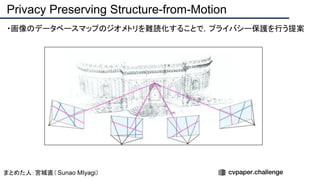

![+αの情報
・データセット:[https://research.cs.cornell.edu/1dsfm/]
・project page:[https://inf.ethz.ch/] [https://cvg.ethz.ch/]
・この研究室は毎年のようにCVPRに論文を通している
CVPR 2018「StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation」
CVPR 2017「 Designing Effective Inter-Pixel Information Flow for Natural Image Matting」](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-101-320.jpg)


![+αの情報
・著者コード(PyTorch):[リンク]
・データセット
Nr3D:[リンク]
Sr3D / Sr3D +:[リンク]
・project page:[リンク]
・Stanford Univ.のLeonidas J. Guibas先生の3D系激強研究室[リンク]
・ECCV2020 8本採択,CVPR2020 9本採択](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-105-320.jpg)
![+αの情報
・著者コード(C++/Python):[リンク]
・project page:[リンク]
・Qualitative Examples (YouTube):[リンク]
・3次元計測技術の研究では有名なMarc Pollefeysの研究室の論文
・CVPR・ECCV・ICCVで多くの論文が採択されている](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-110-320.jpg)






![+αの情報
・Sebastian Scherer:[リンク]
・データセット:[リンク]
・主にロボットについての研究を行っている](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-120-320.jpg)
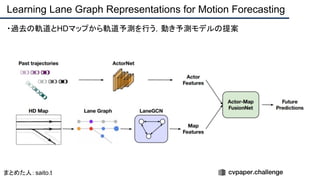
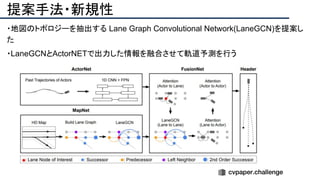
![+αの情報
・著者HP
Ming Liang[リンク]
Raquel Urtasun[リンク]
・この研究室は2013年から毎年CVPRに論文を通している
・ラスト著者のRaquel Urtasun氏はECCV2020にて12本採択されている](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-124-320.jpg)





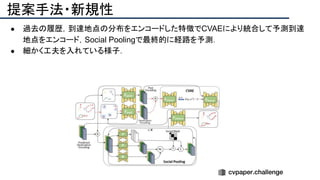


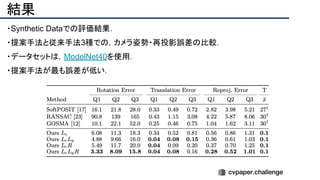
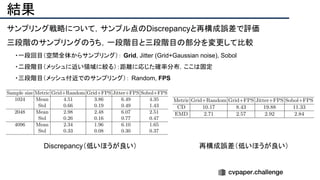
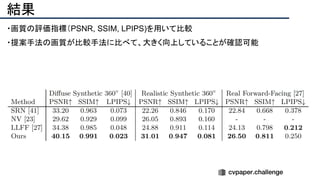
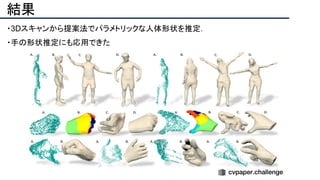
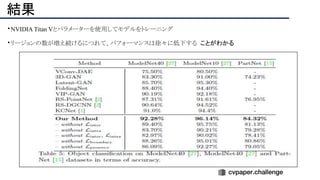
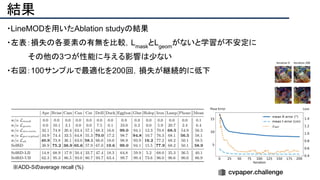
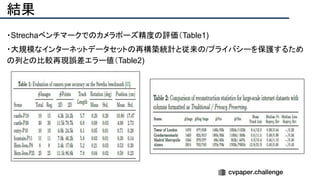
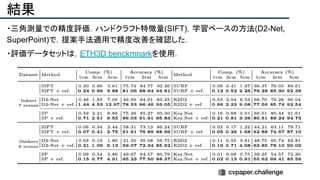
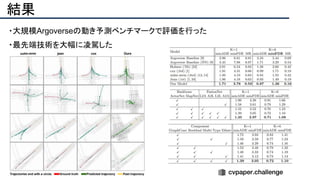
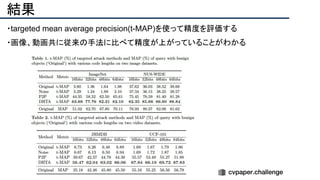
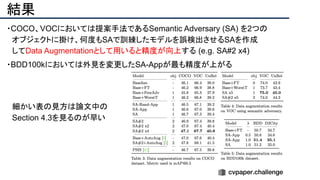
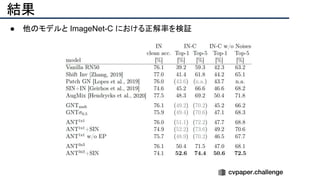
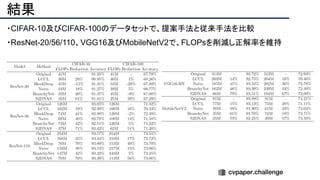
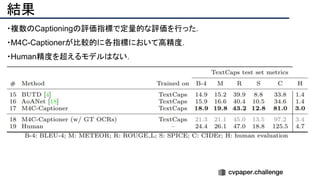
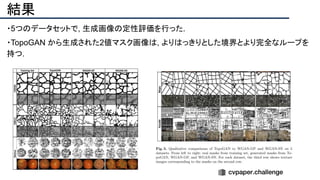
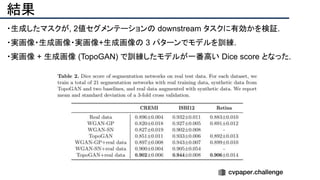
![結果
- PSNR/SSIMによる定量評価
- 従来法の組み合わせに対し,平均的に 5[dB]
(for x2)以上精度向上
- 1[dB]でも相当すごいという肌感
- 出力画像の比較](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-141-320.jpg)


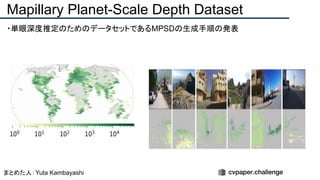
![+αの情報
・著者コード(PyTorch):[リンク]
・データセット:[リンク]
・LIFULL HOME’S datasetは国立情報学研究所が提供するデータセット
← LIFULL HOME’S datasetの例](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-146-320.jpg)








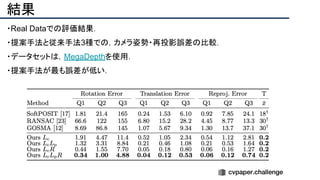
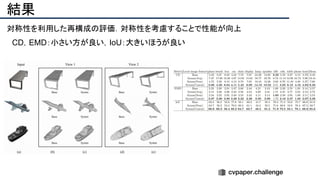
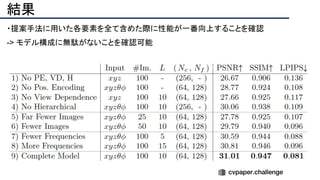
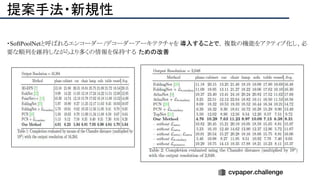
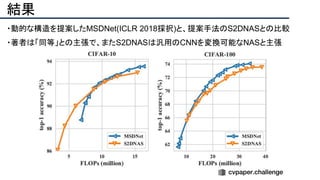
![[22]E-LPIPS: Robust Perceptual Image Similarity via Random Transformation Ensembles
https://arxiv.org/abs/1906.03973
結果
・E-LPIPS, SSIM, PSNRでベースラインとの数値評価
・E-LPIPS[22] は比較的新しい評価指標で,VGG16の特徴を計算比較する](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-158-320.jpg)

![+αの情報
・著者コード:[https://github.com/brownvc/matryodshka]
8/25の時点では "Code release coming soon!"の状態
・project page:[http://visual.cs.brown.edu/projects/matryodshkawebpage/]
10分のプレゼンビデオ/Supplemental Video(従来手法との比較)の視聴が可能](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-160-320.jpg)





![+αの情報
・著者コード(PyTorch):[https://github.com/minyoungg/pix2latent]
・youtube:[https://www.youtube.com/watch?v=pfq9C5yB5WY]](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-169-320.jpg)





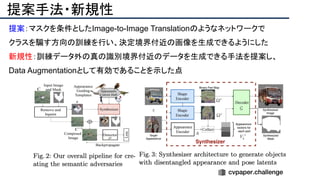









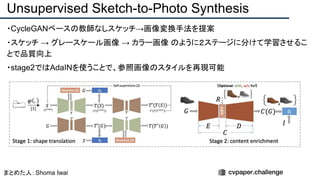
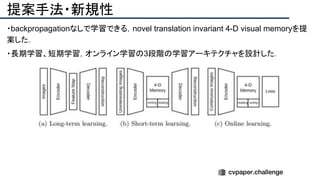
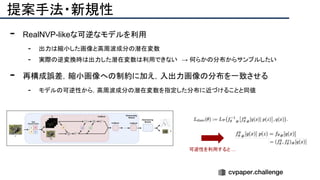
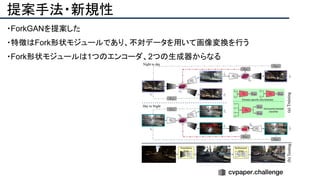
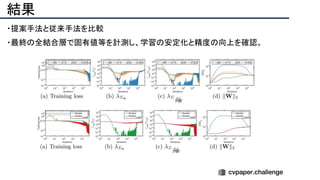
![提案手法・新規性
・スケッチのノイズをうまく修正するため、人工的にノイズを加えたスケッチデータを用意し、
ノイズを除去するように学習させる(下図[1][2])
・Attentionモジュールを使ってノイズを抑制(下図[3])](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-191-320.jpg)


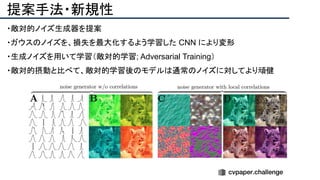
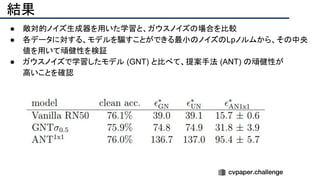
![+αの情報
● 敵対的摂動の転移性や耐転移性の議論につながると考えられる
● NNで敵対的摂動を生成するための方法とも
● その他
○ 著者コード(PyTorch):[https://github.com/bethgelab/game-of-noise]
○ ImageNet-C:[https://github.com/hendrycks/robustness]](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-200-320.jpg)




![+αの情報
・データセット
・Alderley [https://wiki.qut.edu.au/pages/viewpage.action?pageId=181178395]
・BDD100K [https://bdd-data.berkeley.edu/]](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-206-320.jpg)

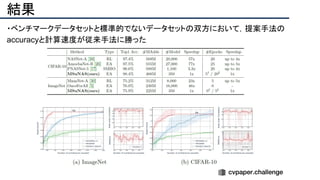
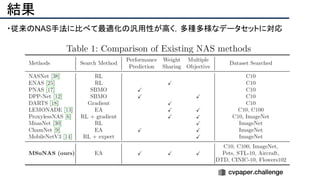
![+αの情報
・著者ホームページ:[http://zhichaolu.com/]
・著者dblp:[https://dblp.org/pid/144/1417.html]
・GitHub:[https://github.com/mikelzc1990/nsganetv2]
・この研究室は毎年のようにArxivに論文を通している
・進化計算とニューラルネットワークの組合せは強そう](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-212-320.jpg)
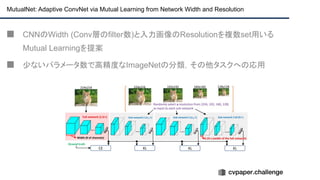
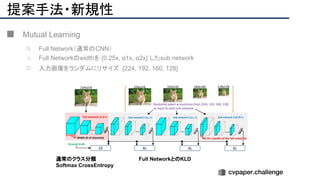
![+αの情報
■ Mutua Learningで学習したモデルをDetectionやSegmetationに転用することは有用
[Github] https://github.com/taoyang1122/MutualNet](https://image.slidesharecdn.com/eccv2020oralsurveyslideshare122-200924121426/85/ECCV2020-Oral-1-2-216-320.jpg)


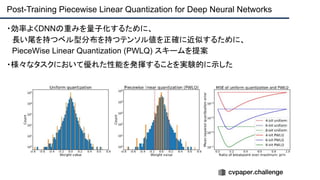
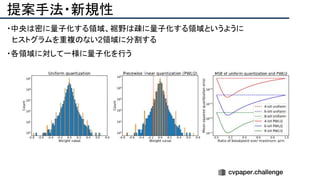


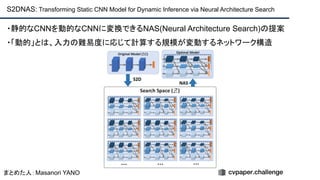
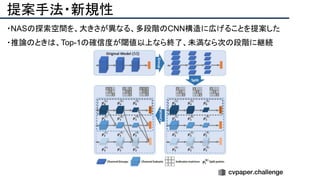











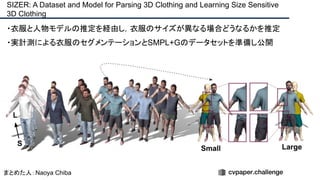
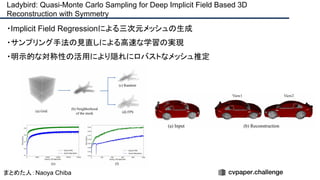
cvpaper.challengeにおいてECCVのOral論文をまとめた「ECCV 2020 報告」です。 ECCV2020 Oral論文 完全読破(2/2) [https://www.slideshare.net/cvpaperchallenge/eccv2020-22-238640597/1] pp. 7-10 ECCVトレンド pp. 12-81 3D geometry & reconstruction pp. 82-137 Geometry, mapping and tracking pp. 138-206 Image and Video synthesis pp. 207-252 Learning methods cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ作成・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。2020の目標は「トップ会議に30+本投稿」することです。
![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Ensemble Distribution Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/ensembledistributiondistillation-200110020132-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



















