Xunsong Li, Pengzhan Sun, Yangcen Liu, Lixin Duan, Wen Li, "Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition ", TMM2025 https://ieeexplore.ieee.org/document/10891539


![関連研究
◼オブジェクト中心の動作認識
• ORN [Baradel+, ECCV2018]
• 物体間関係をGRUで時系列推論
• STRG [Wang+, ECCV2018], OR2G [Ou+, CVPR2022]
• 領域グラフで関係を捉える
• STIN [Materzynska+, CVPR2020]
• 物体ボックスの動きを直接扱う
• STLT [Radevski+, arXiv2021]
• ボックス表現をTransformer強化
• ORViT [Herzig+, CVPR2022]
• パッチトークンと物体トークンを
同一Transformerで共同注意
STINの例(fig1a)
STLTの例(fig4)](https://image.slidesharecdn.com/20251009dair-251105102028-1875d77c/85/Simultaneous-Detection-and-Interaction-Reasoning-for-Object-Centric-Action-Recognition-3-320.jpg)
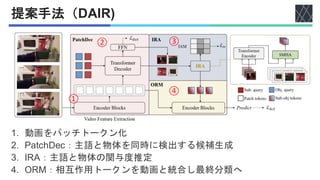


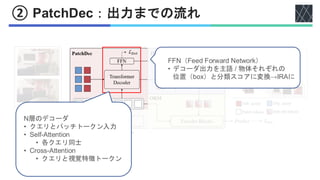
![② PatchDec:物体検出損失
Kuhn
Rezatofighi+, CVPR2019
物体検出損失𝐿𝐷𝐸𝑇
• 予測とGTをHungarian Matching algorithm [Kuhn]
で対応づけし,そのコストの足し合わしたもの
• 𝐿𝑏:L1 ボックス回帰損失
• 𝐿𝑢:IoU損失 [Rezatofighi+, CVPR2019]
• 𝐿𝑐:二値交差エントロピー分類損失](https://image.slidesharecdn.com/20251009dair-251105102028-1875d77c/85/Simultaneous-Detection-and-Interaction-Reasoning-for-Object-Centric-Action-Recognition-8-320.jpg)



![実験設定
◼データセット
• Something-Else [Materzynska+, CVPR2020]
• 174クラス
• train:54919本
• test:57876本
• IKEA-Assembly [Yu+, WACV2021]
• 12クラス
• 16764本
◼基盤モデル
• MViT-S [Li+, CVPR2022]
• Kinetics400で事前学習
◼モジュール構成
• PacthDec:デコーダ6層
• IRA:エンコーダ3層,デコーダ1層
◼各種設定
• AdamW
• 35epoch
• バッチサイズ32
• 入力動画
• 224*224にクロップ,リサイズ](https://image.slidesharecdn.com/20251009dair-251105102028-1875d77c/85/Simultaneous-Detection-and-Interaction-Reasoning-for-Object-Centric-Action-Recognition-12-320.jpg)

![アブレーションスタディ②(検出性能)
◼SomethingElse
• 評価指標
• mAP
• 比較モデル
• Faster-RCNN [Ren+, arXiv2016]
• DETR [Zhu+, arXiv2021]
◼Ikea-Assembly
• 評価指標
• mAP
• 小型オブジェクトでは性能が低く,
検出に失敗する
• 高精度動画(1920*1080)の第三者
視点での小さい物体はリサイズ
(240*240)すると処理が困難](https://image.slidesharecdn.com/20251009dair-251105102028-1875d77c/85/Simultaneous-Detection-and-Interaction-Reasoning-for-Object-Centric-Action-Recognition-14-320.jpg)
![最新手法との比較(Something-Else)
◼比較モデル
• Mformer [Patrick+, NeurlPS2021]
• MViT [Li+, CVPR2022]
• マルチブランチ系
• RGBとBoxを別処理
• 同じRGBモデルMViT使用
• STIN [Materzynska+, CVPR2020]
• STLT [Radevski+, arXiv2021]
• Transformer系
• MGAF [Kim+, ICCV2021]
• SViT [Avraham+, NeurlPS2022]](https://image.slidesharecdn.com/20251009dair-251105102028-1875d77c/85/Simultaneous-Detection-and-Interaction-Reasoning-for-Object-Centric-Action-Recognition-15-320.jpg)














































